1.列表页分页的链接获取不到
原因是:整个HTML页面响应中没有分页链接
利用System.out.println(page.getHtml().toString());将整个爬取的列表页整个显示出来
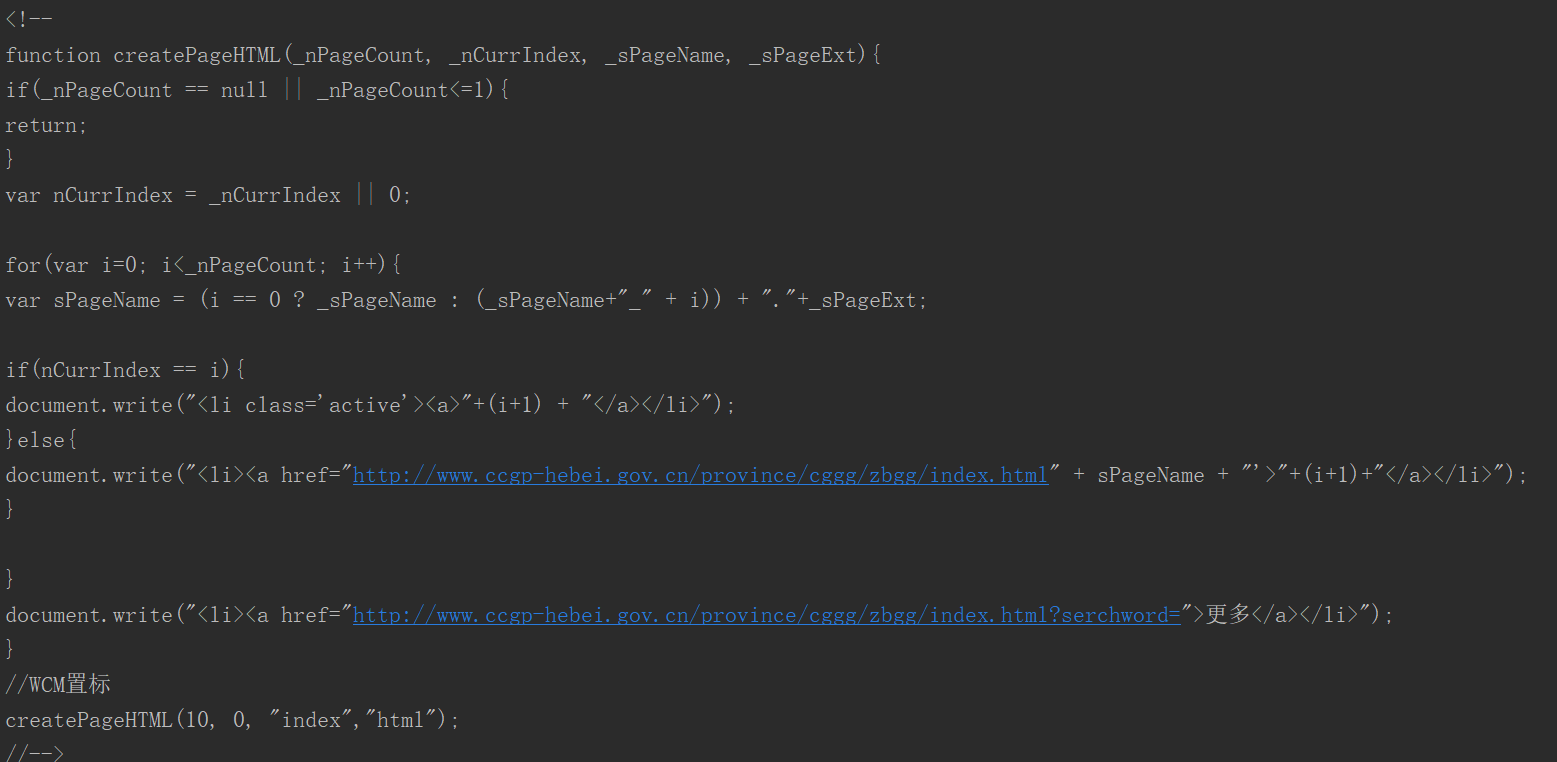
发现爬取到的整个页面是就没有分页链接,网页的分页使用js生成的,所以爬不到
解决办法:根据规律自己组地址
规律是分页的index_1,index_2,页数在变,所以用循环累加页数,一共十页
2.爬取的文章内容为:
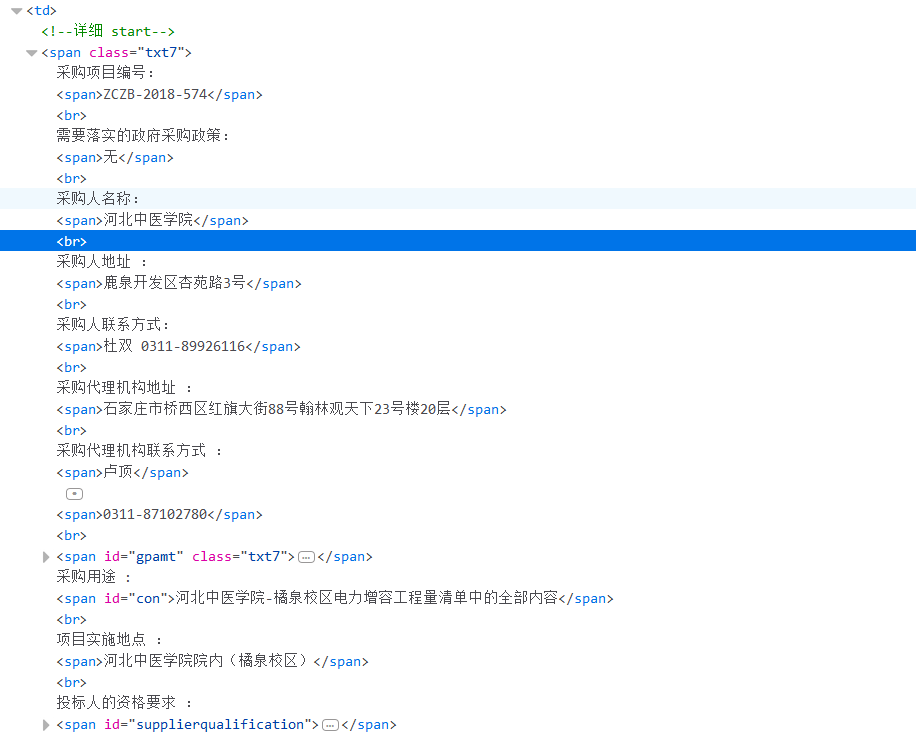
要爬取span标签下内容,但是爬取的内容有的在span标签里面的span,直接指定的话不能将嵌套在里面的span标签下的内容爬取到,这涉及到方法xpath函数的方法text()allText()的区别
首先指定爬取的内容在span class="txt7" ,这样其实爬取的是标签下的所有内容
page.putField("content",page.getHtml().xpath("//span[@class='txt7']"));
爬取结果为
发现包括标签,用text()方法只能将直接的文本摘出来
page.putField("content",page.getHtml().xpath("//span[@class='txt7']/text()"));
结果为

丢失了间接span下的文本,所以要用allText(),其可以保留直接和间接的文本

达到自己要的效果!!!