- 首先对于河北省采购网爬取数据,要有两个url,一个是列表页链接url_list,一个是文章页链接url_poost
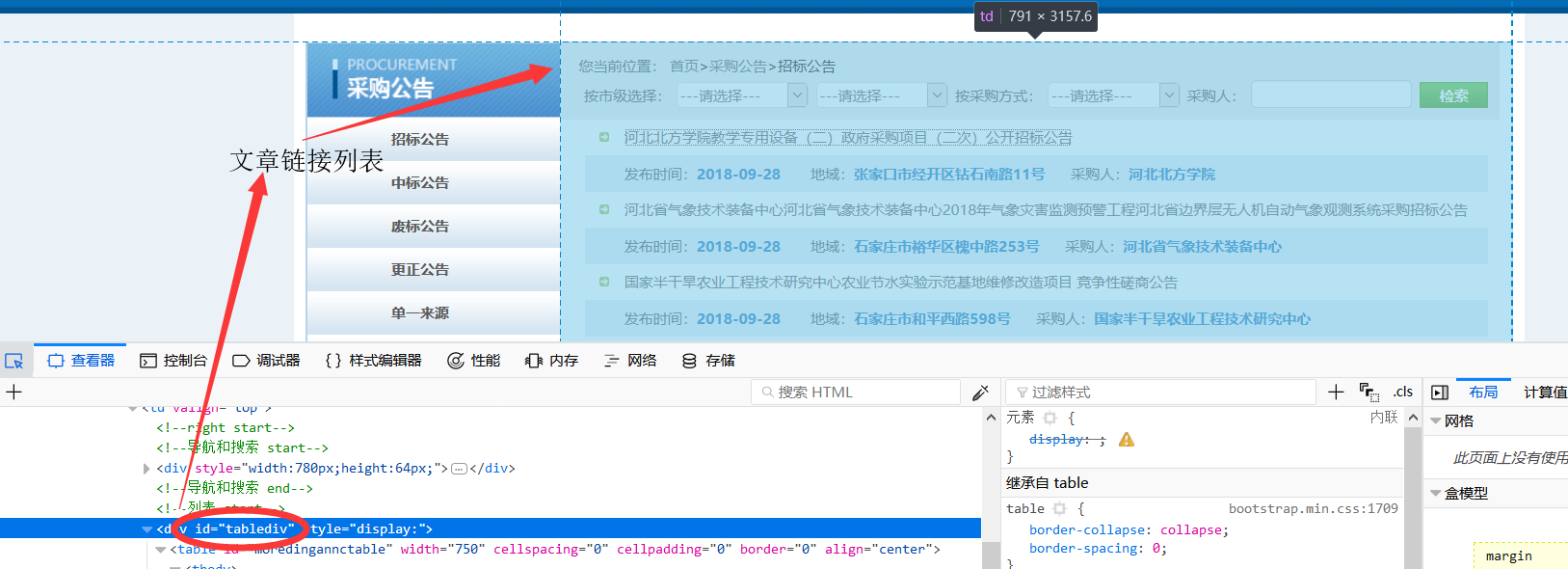
- 由于爬取的页面较为简单,所以并不需要书写正则表达式来筛选文章页链接直接在url_list下获取并添加到请求中:page.addTargetRequests(page.getHtml().xpath("//div[@id="tablediv"]").links().all());
其中,div[@id="tablediv"]对应爬取的网页中的包含文章列表链接的标签,如图:
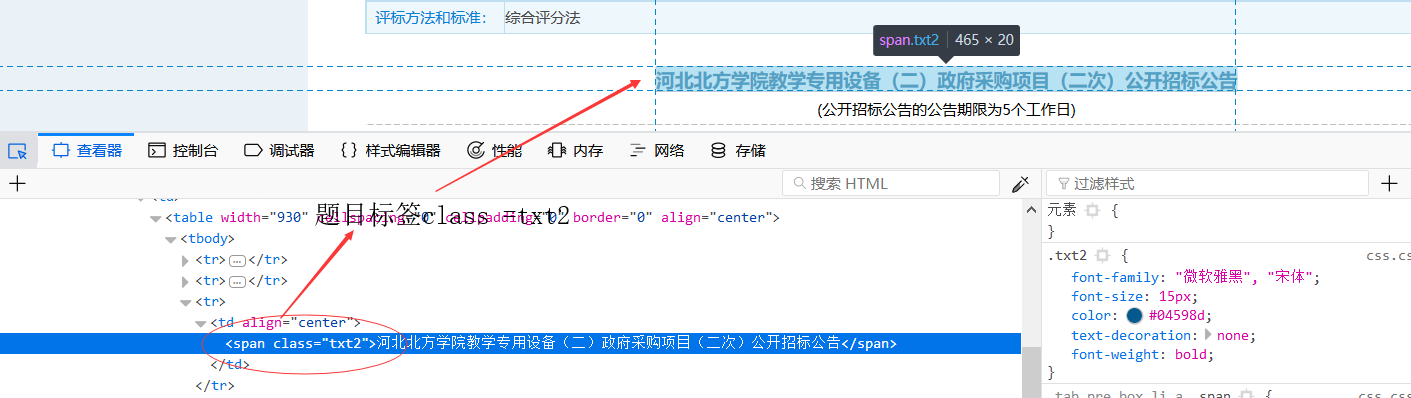
3.正常获取到后在通过xpath提取指定标签的内容:
page.putField("title", page.getHtml().xpath("//span[@class='txt2']/text()"));
如图:
4.在初始运行的时候要首先加载一个网址链接
public static void main(String[] args) {
Spider.create(new GitHub()).addUrl("http://www.ccgp-hebei.gov.cn/province/cggg/zbgg/index.html")
.run();
}
- 去标签:(/text())
page.putField("title", page.getHtml().xpath("//span[@class='txt2']/text()"));