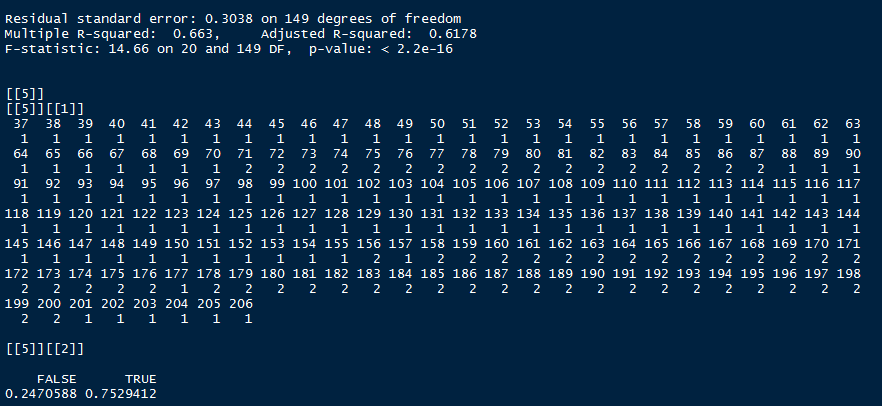
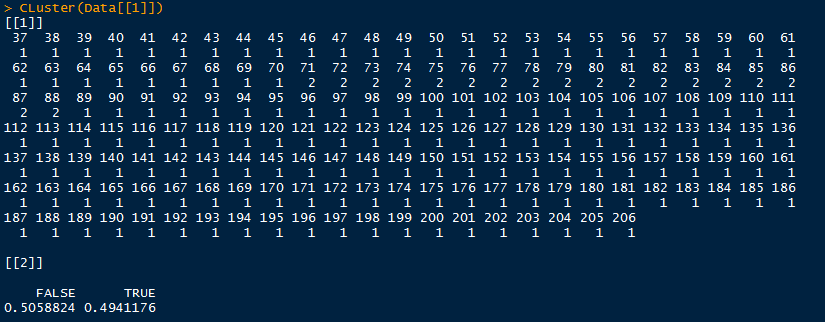
因为工作需要,所以需要对数据进行分类。虽然分类方法很多,但是能够有效并且快速的分类还是蛮少的。以下是两种分类方法,CLuster函数没有对原始数据进行任何处理,直接进行聚类分析。LmReg函数是在线性回归的基础上,先进行变量选择后,再聚类。结果很客观,分类正确率从49%增加至75%。但这都不是这篇博客的重点,毕竟分类正确率,只停留在75%,还是很牞铯的,仍然需要其他方法继续探索。
这篇文章想分享的,其实还是线性回归的自动选择。
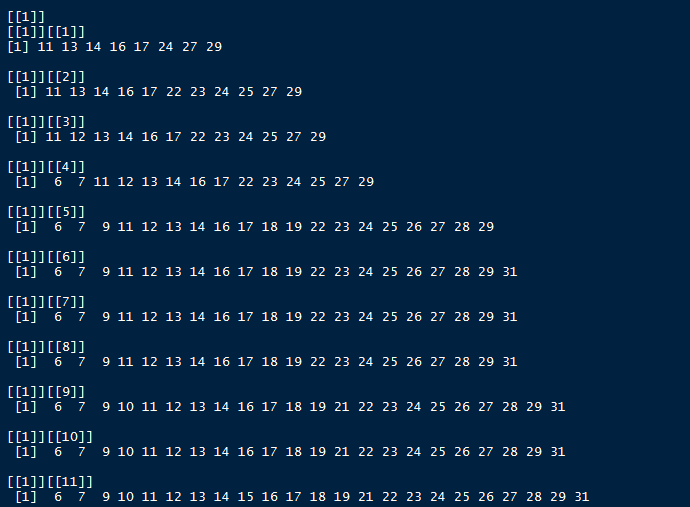
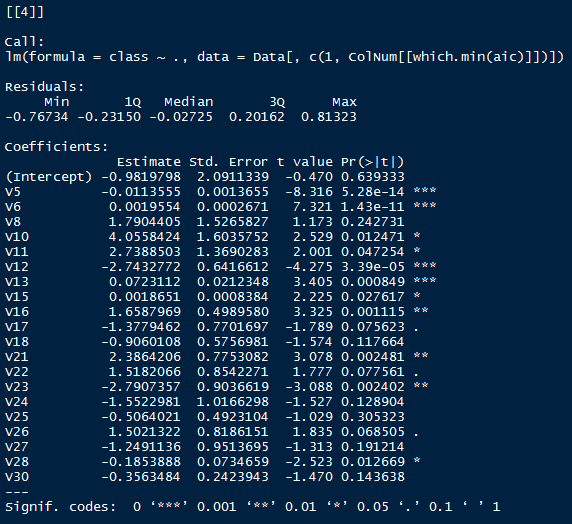
平时我们做线性回归分析,都是先包含所有变量,然后根据P值,一个变量一个变量进行筛选,再看效果如何。但这样的手速实在太慢了,P值就在那里,不来不去。我的想法是:根据P值的不同,进行变量的自动选择。把P值小于0.05的参与变量拿出来,进行线性回归,得到一个AIC值;把P值小于0.1的参与变量拿出来,进行线性回归,再得到一个AIC值。如此重复,在诸多可能情况下,选择最小的AIC值所对应的参与变量,就是最优的变量剩余。
途中,遇到一个超大bug,这一定跟我基础不牢固有关系——变量的混用。看我代码的LmReg函数i,j处应该不难理解,当时就是把i 混用到ColNum这里来了,而List列表标号,是整数!!!!!
切记!!变量不能混用!!
先把我的代码贴上,包括两个函数:1、分类正确率计算函数;2、线性回归自动选择自变量函数。
CLuster <- function(Data){
Classified <- dist(Data[,2:ncol(Data)],method='euclidean') %>% hclust() %>% cutree(k=2)
CorrectRatio <- table(Classified==Data[,1])/sum(table(Classified==Data[,1]))
print(list(Classified,CorrectRatio))
}
LmReg <- function(Data){
Data[,1] <- as.numeric(Data[,1]) # 我的数据框,第一列是因变量,factor类型
Tmp1 <- lm(class~.,data=Data) %>% summary # 做线性回归
Tmp11 <- as.data.frame(Tmp1$coefficients)[-1,] # 提取出线性回归时得到的coefficients表
ColNum <- list() # 将要参与线性回归的列数以列表型保存下来,因为随着P值的增大,列数肯定越多
aic <- c() # aic值的保存,用这个值确定哪些自变量进行线性回归时,所取得的效果最好
for(i in seq(0.05,1,length.out = 20)){
j <- round(i*20,0)
ColNum[[j]] <- which(Tmp11$`Pr(>|t|)` < i) + 1 # 加1是因为,我的自变量是从第二列开始的。
aic <- c(aic,lm(class~.,data=Data[,c(1,ColNum[[j]])]) %>% AIC)
}
print(list(ColNum,aic,which.min(aic),lm(class~.,data=Data[,c(1,ColNum[[which.min(aic)]])]) %>% summary,CLuster(Data[,c(1,ColNum[[which.min(aic)]])]))) # 输出P值不同时的参与列数、对应的AIC值、回归效果以及分类正确率。
}
效果如下:(第二个函数print的东西太多,所以看起来有点杂乱)
![]()