新学,命令全都敲了一遍,感兴趣就一条条跟着敲吧(咳咳)
数据库连接:mysql -u root -p
创建数据库:create databases 数据库名;
显示数据库:show databases;
删除数据库:drop database 数据库名;
选择数据库:use 数据库名;
mysql支持数据类型:严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC);近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION);
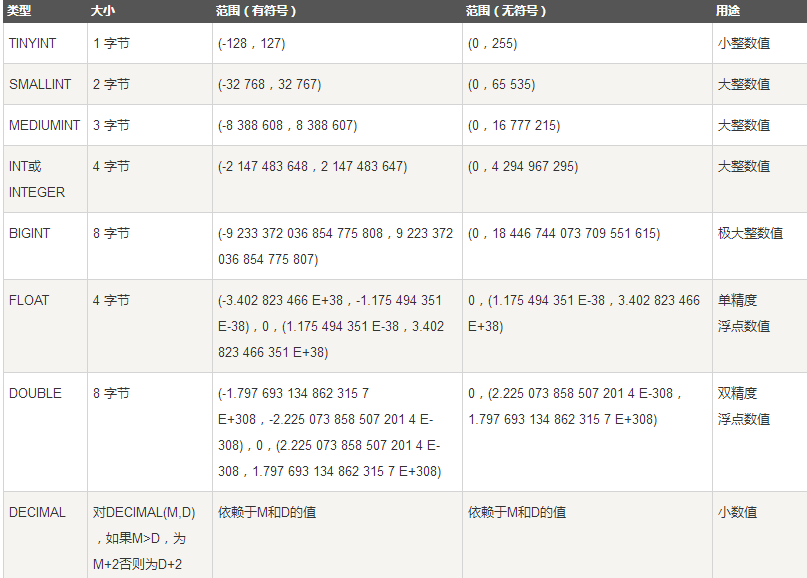
(主要是INT型)
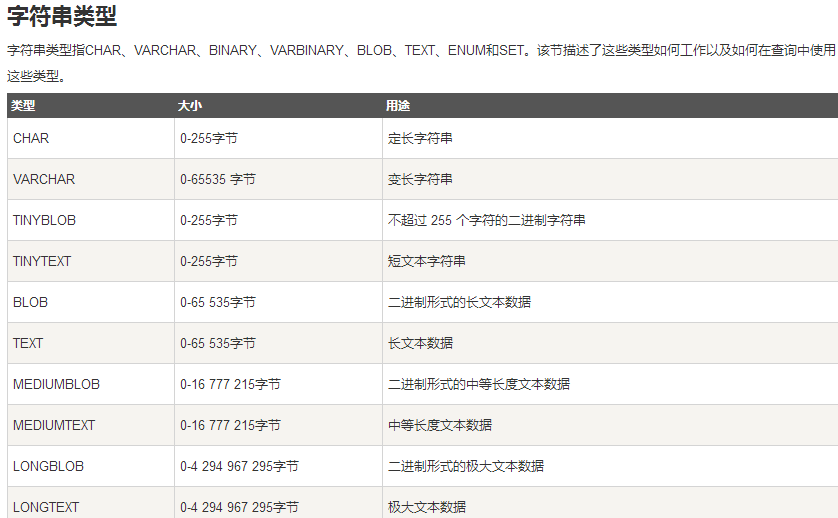
(主要是VARCHAR型)
创建数据表:create table table_name (column_name column_type);
删除数据表:drop table table_name;
插入数据:insert into table_name ( field1, field2,...fieldN ) values( value1, value2,...valueN );
查询数据:select column_name,column_name from table_name [where Clause] [limitN] [ offset M];
where设置条件:select field1, field2,...fieldN from table_name1, table_name2... [where condition1 [AND [OR]] condition2.....];
修改或者更新数据:update table_name set field1=new-value1, field2=new-value2 [where Clause];(更新某一条记录的某个字段的值)
添加或删除数据表字段:alter table jzytab1 drop i;alter table jzytab1 add i INT;
删除行记录:delete from table_name [where Clause];
获取某一字段中含有某些字符的所有记录:select field1, field2,...fieldN from table_name where field1 like condition1 [AND [OR]] filed2 = 'somevalue';(%代表任意字符)
连接两个select语句,去重得到不重复字段值:
select expression1, expression2, ... expression_n from tables [where conditions]
union [ALL | DISTINCT]
select expression1, expression2, ... expression_n from tables[whereconditions];
例如:select country from Websites
union
select country from apps
order by country;
排序数据:select field1, field2,...fieldN from table_name1, table_name2... order by field1, [field2...] [asc [desc]];
对一个或者多个列的结果集进行分组,然后再分组的基础上使用count计数,或使用sum求和,或使用ave求平均值:select column_name, function(column_name) from table_name where column_name operator value group by column_name;
实现在分组统计数据基础上再进行相同的统计:select name, sum(singin) as singin_count from jzytab2 group by name with rollup;
连接(内连接,左连接,右连接):直接上例子
select a.id,a.zuozhe,b.count from jzytab1 a inner join jzytab2 b on a.zuozhe= b.zuozhe;
左连接:
select a.id,a.zuozhe, b.count from jzytab1 a left join jzytab2 b on a.zuozhe= b.zuozhe;
右连接:
select a.id,a.zuozhe, b.count from jzytab1 a right join jzttab2 b on a.zuozhe= b.zuozhe;
值为NULL时,判断条件不能是=NULL或者!=NULL,只能用IS NULL或者IS NOT NULL:select * from jzytab1 where city IS NULL;
正则表达式简单介绍:^st:以st开头的单词。ok$:以ok结尾的单词。o{2}:连续出现两个o的单词。
举例子喽:
SELECT name FROM jzytab1 WHERE name REGEXP '^st';
SELECT name FROM jzytab1 WHERE name REGEXP 'ok$';
SELECT name FROM jzytab1 WHERE name REGEXP 'mar';
SELECT name FROM jzytab1 WHERE name REGEXP '^[aeiou] | ok$';(以元音字符开头或以'ok'字符串结尾的所有数据)
数据库事务理解:主要用于处理操作量大,复杂度高的数据。例如,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务(四特性:一致同意持久的隔离原子)!
在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句后就会马上执行 COMMIT 操作。执行命令 SET AUTOCOMMIT=0,用来禁止使用当前会话的自动提交。(出现问题了:设置自动提交之后,又禁用了自动提交。当开始一个事务时,插入一条记录后回滚不回去了。。。。。。)
修改字段类型及名称:alter table 表名 modify city CHAR(10);以前是VARCHAR(30)或者:
alter table 表名 change 旧字段名 新字段名 新字段类型;
修改字段的默认值:(失败了||=_=|| 为啥呢):alter table jzytab1 alter i set default 1000;
alter table jzytab1
-> modify j bigint NOT NULL DEFAULT 100;
修改数据表的类型(修改存储引擎):alter table jzytab1 ENGINE = MYISAM;
MySQL常用的四种引擎:MyISAM存储引擎(不支持事务、也不支持外键,优势是访问速度快)、InnoDB存储引擎(提供了具有提交、回滚和崩溃恢复能力的事务安全)、MEMORY存储引擎(memory类型的表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引)、MERGE存储引擎(一组MyISAM表的组合,这些MyISAM表必须结构完全相同)。
修改表名:alter table jzytab1 rename to jzytab2;
索引:单列索引和组合索引。(一个表可以有多个单列索引)组合索引:一个索引包含多个列。
创建索引:create index 索引名 on 表名(列名(length));
添加索引:alter table 表名 add index 索引名(列名);
显示索引信息:show index from 表名;G