一 软件测试基础理论题
- 常见的测试方法有哪些?


1 从是否关心内部结构来看分为:白盒,黑盒,灰盒 黑盒测试不考虑程序内部结构和逻辑结构,主要是用来测试系统的功能是否满足需求规格说明书。一般会有一个输入值,一个输入值,和期望值做比较。 白盒测试主要应用在单元测试阶段,主要是对代码级的测试,针对程序内部逻辑结构,测试手段有:语句覆盖、判定覆盖、条件覆盖、路径覆盖、条件组合覆盖 灰盒是一种综合测试法,它将黑盒与白盒结合在一起,是基于程序运行时的外部表现又结合内部逻辑结构来设计用例,执行程序并采集路径执行信息和外部用户接口结果的测试技术。 2 从是否执行代码来看分为:静态测试和动态测试 静态测试:指不运行被测程序本身,仅通过分析或检查源程序的语法、结构、过程、接口等来检查程序的正确性。 动态测试:是指通过运行被测程序,检查运行结果与预期结果的差异,并分析运行效率、正确性和健壮性等性能指标。 3 从开发过程级别来看分为:单元测试,集成测试,系统测试,验收测试。 单元测试的粒度最小,一般由开发小组采用白盒方式来测试,主要测试单元是否符合“设计”。 集成测试界于单元测试和系统测试之间,起到“桥梁作用”,一般由开发小组采用白盒加黑盒的方式来测试,既验证“设计”,又验证“需求”。 系统测试的粒度最大,一般由独立测试小组采用黑盒方式来测试,主要测试系统是否符合“需求规格说明书”。系统测试中具体的类型类型有:功能测试,性能测试,接口测试,安全性测试,兼容性测试等 验收测试与系统测试相似,主要区别是测试人员不同,验收测试由用户执行。
- 测试用例设计方法(可能会结合具体的题让你用方法设计测试用例)有哪些?
等价类划分,边界值分析,判定表,正交实验法,错误推测,因果图,场景法等
常见的设计测试用例题:给你一部电梯怎么设计测试用例,针对一支笔设计测试用例,对手机上的计算器设计测试用例,给你一个纸杯怎么怎么设计测试用例,针对美团支付尽可能多的设计测试用例
- 说一说web测试和app测试有哪些异同点?
相同: web测试和app测试从流程上来说,没有区别。都需要经历测试计划方案,用例设计,测试执行,缺陷管理,测试报告等相关活动。从技术上来说,web测试和app测试其测试类型也基本相似,都需要进行功能测试、性能测试、安全性测试、GUI测试等测试类型。 不同: 他们的主要区别在于具体测试的细节和方法有区别,比如:性能测试,在web测试只需要测试响应时间这个要素,在app测试中还需要考虑流量测试和耗电量测试。 兼容性测试:在WEB端是兼容浏览器,在App端兼容的是手机设备。而且相对应的兼容性测试工具也不相同,web因为是测试兼容浏览器,所以需要使用不同的浏览器进行兼容性测试(常见的是兼容IE,chrome,firefox,360,Edge,Safari,搜狗)如果是手机端,那么就需要兼容不同品牌,不同分辨率,不同android版本甚至不同操作系统的兼容。(常见的兼容方式是兼容市场占用率前N位的手机即可),有时候也可以使用到兼容性测试工具,但WEB兼容性工具多用IETester等工具,而app兼容性测试会使用Testin这样的商业工具也可以做测试。 安装测试:web测试基本上没有客户端层面的安装测试,但是app测试是存在客户端层面的安装测试,那么就具备相关的测试点。 还有,app测试基于手机设备,还有一些手机设备的专项测试。如交叉事件测试,操作类型测试,网络测试(弱网测试,网络切换) 交叉事件测试:就是在操作某个软件的时候,来电话、来短信,电量不足提示等外部事件。 操作类型测试:如横屏测试,手势测试 网络测试:包含弱网和网络切换测试。需要测试弱网所造成的用户体验,重点要考虑回退和刷新是否会造成二次提交。弱网络的模拟,据说可以用360wifi实现设置。 从系统架构的层面,web测试只要更新了服务器端,客户端就会同步会更新。而且客户端是可以保证每一个用户的客户端完全一致的。但是APP端是不能够保证完全一致的,除非用户更新客户端。如果是app下修改了服务器端,意味着客户端用户所使用的核心版本都需要进行回归测试一遍。 还有升级测试:升级测试的提醒机制,升级取消是否会影响原有功能的使用,升级后用户数据是否被清除了。
- 接口怎么测试?
接口测试点: 1 业务功能是否实现,包括正常、异常场景是否实现。 正常包括单个参数,组合参数,必填参数,非必填参数都在接口文档范围内输入 异常场景包括少传,多传,不传接口文档里规定的参数,重复提交、并发提交、多机环境、大数据量测试 2 检查接口返回的数据是否与预期结果一致。 如新增成功时业务code是否返回00,新增用户已存在时code是否返回02,传参类型错误时code是否返回03,与接口文档对比 响应body:是否与文档里给的结果和字段一致 响应数据:是否与数据库数据匹配 3 检查接口的容错性,假如传递参数值为空,长度不一致,错误数据,不同数据类型等时是否可以处理。 4 接口参数的边界值。例如,传递的参数足够大,足够小或为负数时,接口是否可以正常处理。 5 接口的性能,http请求接口大多与后端执行的SQL语句性能、算法等比较相关。 6 接口的安全性,外部调用的接口尤为重要。 1 敏感信息是否加密 2 必要参数是否后端也进行验证(绕过前端很容易,需要后端同样进行控制) 3 接口是否防恶意请求(SQL注入) 7 接口的兼容性,比如接口进行了调整,但是前端没有进行变更,这时候需要验证新的接口是否满足旧的调用方式
- 什么是C/S和B/S架构?分别说一说?
C/S架构软件: 是Client/Server的简称,指客户/服务器模式 这种模式只要客户机上安装一个浏览器,如Internet Explorer,服务器安装Oracle、MYSQL等数据库。浏览器通过Web Server 同数据库进行数据交互。 B/S型模式: 是Browser/Server的简称,指浏览器/服务器模式。 它是软件系统体系结构,通过它可以充分利用两端硬件环境的优势,将任务合理分配到Client端和Server端来实现,降低了系统的通讯开销。目前大多数应用软件系统都是Client/Server形式的两层结构。
二 数据库题
- 简述内连接和外连接的区别?
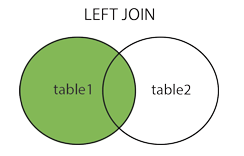
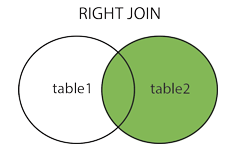
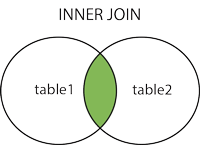
外连接分为左外连(left join)和右外连(right join) 左连接:取左表的全部,右表按条件符合的显示,不符合的则显示null 右连接:取右表的全部,左表按条件符合的显示,不符合的则显示null SELECT *FROM t_reserve a LEFT JOIN t_advisor b ON a.advisor_id=b.id; SELECT *FROM t_reserve a RIGHT JOIN t_advisor b ON a.advisor_id=b.id; 内连接关键字为inner join,返回两张表都满足条件的部分
- 多表查询/分组查询题
现有三张表,分别为: 学生表(学生id,姓名,性别,分数) )student(s_id, name, sex, score) 班级表(班级id,班级名称) class(c_id, c_name) 学生班级表(班级id,学生id) student_class(s_id,c_id) 1.查询一班得分在80分以上或者等于60,61,62的学生。 SELECT s.s_id, s. NAME, s.score, sc.c_id, c.c_name FROM student s LEFT JOIN student_class sc ON s.s_id = sc.s_id LEFT JOIN class c ON sc.c_id = c.c_id WHERE ( s.score > 80 OR s.score IN (60, 61, 62) ) AND c.c_name = '一班'; 2.査询所有班级的名称,和所有班中女生人数和女生的平均分。 SELECT sc.s_id, c.c_name, COUNT(s.sex), AVG(s.score) FROM student_class sc LEFT JOIN class c ON sc.c_id = c.c_id LEFT JOIN student s ON sc.s_id = s.s_id WHERE s.sex = '女' GROUP BY c.c_name ORDER BY c.c_id ASC;
-
什么是数据库事务?
数据库事务( transaction)是访问并可能操作各种数据项的一个数据库操作序列,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。事务由事务开始与事务结束之间执行的全部数据库操作组成。
三 网络协议篇
- get和post的区别?
get和post是http协议最常用的两种请求方式: 1.get请求是从服务器获取资源,post请求是向服务器提交数据 2.get请求参数放在url里,通过?拼接;post请求参数放在body里,通过表单提交 ①url很容易被截获,所以get比post更不安全 ②因为get放在url里,url存在长度限制一般限制最长256个字符,而post放在body则不存在长度限制 3.get请求通过url可以放在浏览器中,所以可以被缓存和收藏为书签,并且能在浏览器历史中记录下来; 而post则不行 4.get方法发送同一个请求无论执行多少次效果都相同,不会对服务器端数据产生不良影响,所以get请求是幂等的,post请求是非幂等的
- 在浏览器中输入一个url后发生了什么?
1 在浏览器中输入一个url地址 2 浏览器通过DNS域名解析器找到域名对应的ip和端口 3 确认ip和端口后,向该ip对应的服务器的端口发送TCP请求(三次握手),建立连接 4 浏览器给web服务器发送一个http请求 5 服务器处理请求 6 服务器发送回一个HTML响应 7 关闭TCP连接(四次挥手) 8 浏览器开始显示HTML 9 浏览器发送获取嵌入在HTML中的对象 10 构建渲染树 11 浏览器布局渲染
- http和https有什么区别?
HTTP协议是超文本传输协议,被用于在Web浏览器和网站服务器之间传递信息。HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此HTTP协议不适合传输一些敏感信息,比如信用卡号、密码等。 为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS。为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。 HTTPS和HTTP的区别主要为以下四点: 1.https协议需要到ca申请证书,一般免费证书很少,需要交费。 2.http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议。 3.http和https使用的是完全不同的连接方式,用的端口也不一样,前者默认是80,后者默认是443。 4.http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络,比http协议安全。 思考:什么是http的无状态? 无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。即我们给服务器发送HTTP请求之后,服务器根据请求,会给我们发送数据过来,但是,发送完,不会记录任何信息。所以随着人们需求的增加,客户端使用cookie,服务端使用session来记录连接的状态
- 说一说对TCP协议的三次握手和四次挥手 的理解?
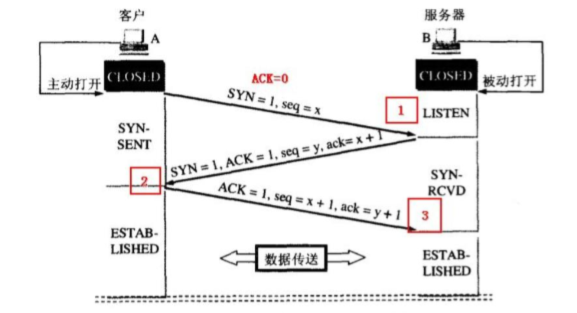
(注:seq代表序号,ack代表确认号) 第一次握手:当客户端需要去建立连接时,客户端就会发送SYN包(seq=x)到服务器,然后客户端进入SYN_SEND的状态,代表已经发SYN包过去,并且在等待服务器确认。此时ACK=0,SYN=1.,这时候由于才第一次握手,所以没有ACK标志 第二次握手:服务器收到SYN包,就会进行确认,由上面的标志位介绍我们可以知道SYN是表示同步序号,这时候会使得确认号=序号+1,即ack就会等于x+1,然后服务器也会像客户端发送一个SYN包(seq=y),这时候也就是服务器会发送SYN+ACK包,来表示服务器确认到了客户端的一次握手并且二次握手建立,此时服务器进入SYN_RECV状态。此时SYN=1,ACK=1,这时候由于是第二次握手,所以就会有一个服务器给客户端的确认标志。 第三次握手:客户端收到服务器的SYN+ACK包,然后就会像服务器发送确认包ACK(ack=k+1)和SYN(seq=x+1),等到这个包发送完毕之后客户端和服务器就会进入ESTABLISHED状态,完成三次握手,而后就可以在服务端和客户端之间传输数据。此时SYN标志位已经不需要,因为当我们发送ACK标志位的时候代表三次握手成功,已经建立完连接了,接下来可以传送数据过去了。 既然都有SYN包那为什么还要ACK来确认呢?SYN是同步序号,当 SYN=1 而ACK=0 时,表明这是一个连接请求报文。对方若同意建立连接,则应在响应报文中使 SYN=1 和 ACK=1。因此SYN置1就表示这是一个连接请求或连接接受报文。而ACK状态是用来确认是否同意连接。也就是传了 SYN,证明发送方到接收方的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。 当TCP三次握手完之后,就代表连接已经建立完成

当在传送完数据之后,客户端会和服务端之间有四次握手 第一次握手:客户端发送一个FIN和序号过去(seq=u),用来表示客户端和服务端之间有关闭的请求,同时关闭客户端到服务端的数据传送,客户端就进入FIN_WAIT_1的状态。 第二次握手:服务端收到FIN=1的标志位时,就会发送一个ACK标志位代表确认,然后确认序号就变成了收到的序号加1,即ack=u+1(FIN和SYN在这点上相同,但是作用不一样)这时候服务端进入CLOSE_WAIT状态,这是一个半关闭状态。只能服务端给客户端发送数据而客户端不能给服务端发送数据。 第三次握手:这次握手还是由服务端发起,这是服务端在传完最后的数据(没有就不传)就会发送一个FIN=1和ACK=1,且序号seq会改变(没有传数据则不变),而ack不变。这时候服务端就会进入LAST_ACK状态,表示最后确认一次。 第四次握手:客户端在接收到FIN之后,就会进入TIME_WAIT状态,接着就发送一个ACK和seq=u+1,ack=w+1给服务端,这时候服务端就会进入CLOSED状态。而客户端进入TIME_WAIT状态的时候必须要等待2MSL的时间才会关闭
- http常见的状态码分别代表什么?
1xx:信息提示 2xx:成功 200:成功。请求的所有数据都在响应体中 3xx:重定向 301:(Moved Permanently)当客户端触发的动作引起了资源URI的变化时发送此响应代码。另外,当客户端向一个资源的旧URI发送请求时,也发送此响应代码。 4xx:客户端错误 400:(Bad Request)客户端方面的问题。实体主题中的文档(若存在的话)是一个错误消息。希望客户端能够理解此错误消息,并改正问题。 401:(Unauthorized未授权)需要输入用户名和密码 404:(Not Found未找到)服务器无法找到所请求URL对应的资源 5xx:服务器错误 502:(Bad Gateway)指错误网关,无效网关;在互联网中表示一种网络错误
- 说一说对正向代理和反向代理的理解?
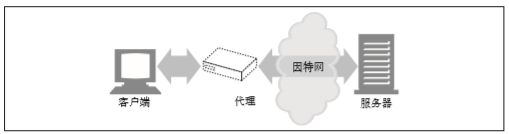
如图所示,正向代理,"它代理的是客户端",是一个位于客户端和原始服务器(Origin Server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器)。 然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。 正向代理的用途: 访问原来无法访问的资源,如 Google。 可以做缓存,加速访问资源。 对客户端访问授权,上网进行认证。 代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息。

通过上述的图解大家就可以看清楚了,多个客户端给服务器发送的请求,Nginx 服务器接收到之后,按照一定的规则分发给了后端的业务处理服务器进行处理了。 此时请求的来源也就是客户端是明确的,但是请求具体由哪台服务器处理的并不明确了,Nginx 扮演的就是一个反向代理角色。 客户端是无感知代理的存在的,反向代理对外都是透明的,访问者并不知道自己访问的是一个代理。因为客户端不需要任何配置就可以访问。 反向代理,"它代理的是服务端",主要用于服务器集群分布式部署的情况下,反向代理隐藏了服务器的信息。 反向代理的作用: 保证内网的安全,通常将反向代理作为公网访问地址,Web 服务器是内网。 负载均衡,通过反向代理服务器来优化网站的负载。
四 linux相关
- Linux怎么查看日志?
linux查看日志文件内容命令tail、cat、tac、head、echo tail -f test.log 实时查看日志,你会看到屏幕不断有内容被打印出来. 这时候中断第一个进程Ctrl+C, linux 如何显示一个文件的某几行(中间几行) 从第3000行开始,显示1000行。即显示3000~3999行 cat filename | tail -n +3000 | head -n 1000 显示1000行到3000行 cat filename| head -n 3000 | tail -n +1000 *注意两种方法的顺序 分解: tail -n 1000:显示最后1000行 tail -n +1000:从1000行开始显示,显示1000行以后的 head -n 1000:显示前面1000行 用sed命令 sed -n '5,10p' filename 这样你就可以只查看文件的第5行到第10行。 例:cat mylog.log | tail -n 1000 #输出mylog.log 文件最后一千行 tac (反向列示) tac 是将 cat 反写过来,所以他的功能就跟 cat 相反, cat 是由第一行到最后一行连续显示在萤幕上, 而 tac 则是由最后一行到第一行反向在萤幕上显示出来! 在Linux中echo命令用来在标准输出上显示一段字符,比如: echo "the echo command test!" 这个就会输出“the echo command test!”这一行文字!
- linu常用命令又哪些?
pwd 显示当前路径 cd 切换目录 cd ../ 切换到上级目录 cd / 切换到根目录 mkdir 创建目录 rmdir -rf 删除目录 ls 查看目录或文件信息 ll 列出目录或文件的详细信息。比如权限/修改时间等 vi 文本编辑器 键入i 进入编辑状态 退出编辑按ESC键 不保存退出: :q! 保存退出: :wq 输入/,进入搜索 输入:set nu,显示每一行的行数 按键盘G,可以直接定位到最末尾 cp 复制 cp a.txt b.txt将a文件复制,且另命名为b文件 mv移动 mv a.txt ../ 将a文件移动到上级目录(将一个文件移动到另一个目录没有重命名) mv a.txt ../b.txt 将a文件移动到上一级并改名为b文件(将一个文件移动到另一个目录并重命名) find查找文件 find . -name *.log 在当前目录查找以.log结尾的文件 find / -name log 在根目录查找log命名的目录 grep过滤 grep band file 在file文件中找寻band字符串 cat显示文本文件内容 cat a.txt head查看前几行 head -n 5 a.txt 查看a文件中的前5行内容 tail从指定点开始将我呢见写到标准输出 tail -n 5 文件名 查看后几行 tail -f error.log 不断刷新,看到最新内容 ps查看进程 ps -ef 显示所有运行的进程 netstat查看网络状况 netstat -apn 查看所有端口 rz上传 sz下载 .tar (注:tar是打包,不是压缩!) 解包:tar xvf FileName.tar 打包:tar cvf FileName.tar DirName .zip 解压:unzip FileName.zip 压缩:zip FileName.zip DirName 关闭防火墙 开启:service iptables start 关闭:service iptables stop
- Linux如何查看ip?
环境centos7 1 打开终端 2 在终端里输入命令ifconfig -a 3 如何找不到这个命令可以试试ip addr
五 编程题(python)
- 说说list ,tuple,dict之间的区别?
1 list,dict是可变类型;tuple是不可变类型 2 list用{}来申明,tuple用()来申明,dict用key,value键值对来表示,且key必须是不可变类型 3 list和tuple是有序的,可以用下标来访问,dict只能用key来访问
- 迭代器和生成器有什么区别?
迭代器: 迭代是Python最强大的功能之一,是访问集合元素的一种方式。 迭代器是一个可以记住遍历的位置的对象。 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。 迭代器有两个基本的方法:iter() 和 next() 创建一个迭代器: 把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与 __next__() 。 如果你已经了解的面向对象编程,就知道类都有一个构造函数,Python 的构造函数为 __init__(), 它会在对象初始化的时候执行。 __iter__() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 __next__() 方法并通过 StopIteration 异常标识迭代的完成。 __next__() 方法(Python 2 里是 next())会返回下一个迭代器对象。 生成器: 在 Python 中,使用了 yield 的函数被称为生成器(generator)。 跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。 在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。 调用一个生成器函数,返回的是一个迭代器对象。
- =和==和is有什么不同?
=:是赋值 ==:是判断是否相等,比较的是对象的值,返回True或False is:比较的是对象的内存地址,即is比较的是两个对象的id值是否相同。is 运算符比 == 效率高,在变量和None进行比较时,应该使用 is。
- 什么是装饰器,手写一个装饰器
#装饰器的本质是两层函数,两层函数的本质是闭包,闭包的本质是函数对象加函数部分所需要使用的一个外部变量 import time def timer(func): def func1(): time1 = time.time() func() time2 =time.time() print("时间差:%s" %(time2-time1)) return func1 @timer def a(): i = 1 while i<=1000000: i+=1 a()
- 简述一下三种方法的区别?
1 实例方法,参数要有self,必须通过实例化的对象去调用。 2 类方法,要加上@classmethod来声明,参数至少有一个,一般定义为cls,使用类变量,不能使用实例变量。通过类名或者实例对象调用。 3 静态方法,要加上@staticmethod来声明,可以没有参数,使用类变量,不能使用实例变量。通过类名或者实例对象调用。
- 说一说类的三大特性
封装:根据职责将属性和方法封装到一个抽象的类中。
继承:实现代码的重用,不需要重复编写代码。子类拥有父类所有的属性和方法。也可以重新定义父类方法。
多态:不同的对象调用相同的代码,产生不同的效果,提高代码的灵活性。
- 深浅拷贝的区别?
浅拷贝copy.copy(),数据半共享(只是拷贝原来变量中的不可变数据类型,可变数据类型只是引用) >>> import copy >>> >>> a=[1,2,3,'x',['y','z']] >>> c=copy.copy(a) >>> a.append(4) >>> a[4].append(100) >>> print(a) [1, 2, 3, 'x', ['y', 'z', 100], 4] >>> print(c) [1, 2, 3, 'x', ['y', 'z', 100]] 深拷贝copy.deepcopy(),数据完全不共享(复制其数据完完全全放独立的一个内存,形成一个新的对象,虽然与之前的值和内容一模一样,但是它们完完全全的两个对象,互不影响) >>> import copy >>> >>> a=[1,2,3,'x',['y','z']] >>> c=copy.deepcopy(a) >>> a.append(4) >>> a[4].append(100) >>> print(a) [1, 2, 3, 'x', ['y', 'z', 100], 4] >>> print(c) [1, 2, 3, 'x', ['y', 'z']]
- 写一个冒泡排序
#冒泡的核心是两两比较,大的放最后 for i in range(len(a)): for j in range(len(a)-1-i): #里层循环每次循环剔除一个元素,即-i if a[j]>a[j+1]: a[j],a[j+1] = a[j+1],a[j] #如果前一个元素大于后一个元素则交换两个元素 #print("****",a) print(a)
- 写一个快排
''' 快排的核心思想如下: 对于列表,选取一个轴值(一般选取第一个元素或者最后一个元素),把列表中小于该轴值的排在左边,大于该轴值的排在右边,这样,轴值在列表中的位置就确定了。 由此衍生出了轴值的左子列表,以及右子列表,递归的对于左子列表以及右子列表使用上述的排序算法,直到子列表中只有一个元素。 ''' a=[5,4,3,2,1,7] def quick_sort(arr): if len(arr)<=1: return arr piovt = arr[0] left = [] #小于pivot的元素,放到这里 right = [] #大于pivot的元素,放到这里 for i in arr[1:]: if piovt>i: left.append(i) elif piovt<i: right.append(i) return quick_sort(left)+[piovt]+quick_sort(right) print(quick_sort(a))
- 二分法查找
''' 二分法查找: 前提:必须是一个已经排好序的列表 核心:不断的除以2 a=[1,2,3,4,6,7,17,34] key =3 min=0 max=len(a)-1 center=(min+max)/2 每次找中间,用key跟中间元素比较, 如果比中间元素大,那么更新min的值 如果比中间元素小,那么更新max的值 如果等于中间元素,则找到了 ''' def brainy_search(arr,key): min = 0 max = len(arr)-1 if key in arr: while True: center = int((min+max)/2) if key > arr[center]: min = center +1 elif key < arr[center]: max = center -1 elif key == arr[center]: print("%s在列表中的位置是:%s" %(key,center)) return key else: print("%s不在列表中" %key) a=[1,2,3,4,6,7,17,34] print(brainy_search(a,2))
- python有重载和重写吗?怎么实现的?
重写是指子类重写父类的成员方法。子类可以改变父类方法所实现的功能, 但子类中重写的方法必须与父类中对应的方法具有相同的方法名。也就是说 要实现重写,就必须存在继承。 示例: class Person(): def print_info(self): print("*************") class ChinesePerson(Person): def print_info(self): #子类重写父类的print_info方法 print("________") p= ChinesePerson() #子类实例 p.print_info() #子类调用重写方法 p1=Person() #父类实例 p1.print_info() #父类调用重写方法 重载方法的名称是相同的,但在方法的声明中一定要有彼此不相同的成 份,以使编译器能够区分这些方法。重载的方法必须遵循下列原则: ➢方法的参数必须不同,包括参数的类型或个数,以此区分不同方法 体; ➢方法的返回类型、修饰符可以相同,也可以不同。 示例: def a(x): return x def a(x,y): return x+y print(a(1,2)) print(a(1)) 运行结果: 3 Traceback (most recent call last): File "0609.py", line 8, in <module> print(a(1)) TypeError: a() missing 1 required positional argument: 'y' 总结: 重写:把父类的方法覆盖掉,使用子类的同名方法。 重载:多个方法名一样,但是他们的参数类型,还有参数个数不一样(java)。 python不支持重载,因为python可以传可变参数,也没有参数类型的定义。
- 什么是单例,单例有什么用,业务场景是什么?
#单例模式(Singleton Pattern)是一种常用的软件设计模式,单例的本质是一个类最多生成一个实例 比如,某个服务器程序的配置信息存放在一个文件中,客户端通过一个 AppConfig 的类来读取配置文件的信息。 如果在程序运行期间,有很多地方都需要使用配置文件的内容,也就是说,很多地方都需要创建 AppConfig 对象的实例,这就导致系统中存在多个 AppConfig 的实例对象,而这样会严重浪费内存资源,尤其是在配置文件内容很多的情况下。 事实上,类似 AppConfig 这样的类,我们希望在程序运行期间只存在一个实例对象。所以单例设计模式一般用于有减少重复创建实例需求的场景 在 Python 中,我们可以用多种方法来实现单例模式: 1:使用模块使用 2:使用 new 3:使用装饰器(decorator) 4:使用元类(metaclass) 使用__new__示例: 1 真正生成实例的方法 2 在这个方法里,要判断是否存在_instance的类变量,如果已经存在了,直接返回 class Singleton(object): def __new__(cls, *args, **kw): if not hasattr(cls, '_instance'): print(cls) #orig = super(Singleton, cls) cls._instance = object.__new__(cls, *args, **kw) return cls._instance s1=Singleton()#第一次生成实例,走if语句成立,调用__new__生成一个实例,后返回 s2=Singleton()#第二次生成实例,if语句不成立不会再走下面的的语句,直接返回cls._instance(第一次生成的实例),以此来实现单例 print(s1==s2) print(id(s1)) print(id(s2)) 运行结果: <class '__main__.Singleton'> True 1526180159560 1526180159560
- 你熟悉哪些设计模式?
六 自动化篇
七 性能篇
八 工具篇