前言
当我们在Redis数据库中set一个KV的时候,这个KV保存在哪里?如果我们get的时候,又从哪里get出来。时间复杂度,空间复杂的等等,怎么优化等等一系列问题。
服务器中的数据库
Redis服务器将所有数据库信息都保存在redis.h##redisService结构体中。代码如下:
1 struct redisServer { 2 3 // ... 4 5 /* General */ 6 7 // 配置文件的绝对路径 8 char *configfile; /* Absolute config file path, or NULL */ 9 10 // 数据库 11 redisDb *db; 12 13 // 是否设置了密码 14 char *requirepass; /* Pass for AUTH command, or NULL */ 15 16 // PID 文件 17 char *pidfile; /* PID file path */ 18 19 // TCP 监听端口 20 int port; /* TCP listening port */ 21 22 // ... 23 24 }
列了几个,我认为比较重要的。其中最重要的,肯定是redisDb *db; 这个数据结构保存了我们所有的数据。
Redis 是一个键值对(key-value pair)数据库服务器, 服务器中的每个数据库都由一个 redis.h/redisDb 结构表示, 其中, redisDb 结构的 dict 字典保存了数据库中的所有键值对, 我们将这个字典称为键空间(key space)。代码如下:
/* Redis database representation. There are multiple databases identified * by integers from 0 (the default database) up to the max configured * database. The database number is the 'id' field in the structure. */ typedef struct redisDb { // 数据库键空间,保存着数据库中的所有键值对 dict *dict; /* The keyspace for this DB */ // 键的过期时间,字典的键为键,字典的值为过期事件 UNIX 时间戳 dict *expires; /* Timeout of keys with a timeout set */ // 正处于阻塞状态的键 dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */ // 可以解除阻塞的键 dict *ready_keys; /* Blocked keys that received a PUSH */ // 正在被 WATCH 命令监视的键 dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */ struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */ // 数据库号码 int id; /* Database ID */ // 数据库的键的平均 TTL ,统计信息 long long avg_ttl; /* Average TTL, just for stats */ } redisDb;
其中最重要的就是 dict *dict; 他是一个字典,不太了解的小伙伴,可以看我前一篇的文章(https://www.cnblogs.com/wenbochang/p/11673590.html),对redis的字典有详细的介绍。
这个dict存储了我们真正的数据。
键空间和用户所见的数据库是直接对应的:
- 键空间的键也就是数据库的键, 每个键都是一个字符串对象。
- 键空间的值也就是数据库的值, 每个值可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象在内的任意一种 Redis 对象。
因为数据库的键空间是一个字典, 所以所有针对数据库的操作 —— 比如添加一个键值对到数据库, 或者从数据库中删除一个键值对, 又或者在数据库中获取某个键值对, 等等, 实际上都是通过对键空间字典进行操作来实现的。那么复杂度显而易见基本就是O(1)级别了,这也是redis为什么能这么快的一个重要原因。
对键取值
对一个数据库键进行取值, 实际上就是在键空间中取出键所对应的值对象。代码如下:
1 /* 2 * 返回字典中包含键 key 的节点 3 * 4 * 找到返回节点,找不到返回 NULL 5 * 6 * T = O(1) 7 */ 8 dictEntry *dictFind(dict *d, const void *key) 9 { 10 dictEntry *he; 11 unsigned int h, idx, table; 12 13 // 字典(的哈希表)为空 14 if (d->ht[0].size == 0) return NULL; /* We don't have a table at all */ 15 16 // 如果条件允许的话,进行单步 rehash 17 if (dictIsRehashing(d)) _dictRehashStep(d); 18 19 // 计算键的哈希值 20 h = dictHashKey(d, key); 21 // 在字典的哈希表中查找这个键 22 // T = O(1) 23 for (table = 0; table <= 1; table++) { 24 25 // 计算索引值 26 idx = h & d->ht[table].sizemask; 27 28 // 遍历给定索引上的链表的所有节点,查找 key 29 he = d->ht[table].table[idx]; 30 // T = O(1) 31 while(he) { 32 33 if (dictCompareKeys(d, key, he->key)) 34 return he; 35 36 he = he->next; 37 } 38 39 // 如果程序遍历完 0 号哈希表,仍然没找到指定的键的节点 40 // 那么程序会检查字典是否在进行 rehash , 41 // 然后才决定是直接返回 NULL ,还是继续查找 1 号哈希表 42 if (!dictIsRehashing(d)) return NULL; 43 } 44 45 // 进行到这里时,说明两个哈希表都没找到 46 return NULL; 47 }
看代码其实是很简单的。
- 首先判断字典是否为空,如果为空,没有继续下去的必要了,直接return null
- 第二步,如果在进行rehash,则先进行渐进式rehash。(不懂的,翻我上一篇博文)
- 第三步,计算key的hash值。
- 第四步,查找ht[0],ht[1]两张table表。其中如果是链表,则while循环查找即可。
- 找到返回,没找到返回null。非常的简单清晰的逻辑。
- 大致如下图:
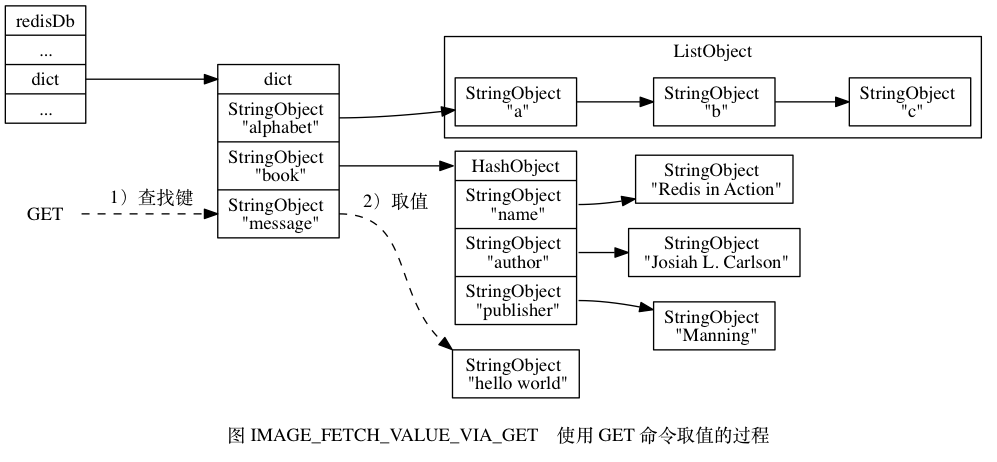
对键增加,删除,更新类似于查找。我就不一一列出源码了。
后言
当使用 Redis 命令对数据库进行读写时, 服务器不仅会对键空间执行指定的读写操作, 还会执行一些额外的维护操作, 其中包括:
- 在读取一个键之后(读操作和写操作都要对键进行读取), 服务器会根据键是否存在, 以此来更新服务器的键空间命中(hit)次数或键空间不命中(miss)次数, 这两个值可以在 INFO stats 命令的
keyspace_hits属性和keyspace_misses属性中查看。
- 在读取一个键之后, 服务器会更新键的 LRU (最后一次使用)时间, 这个值可以用于计算键的闲置时间, 使用命令 OBJECT idletime <key> 命令可以查看键
key的闲置时间。
- 如果服务器在读取一个键时, 发现该键已经过期, 那么服务器会先删除这个过期键, 然后才执行余下的其他操作。
- 如果有客户端使用 WATCH 命令监视了某个键, 那么服务器在对被监视的键进行修改之后, 会将这个键标记为脏(dirty), 从而让事务程序注意到这个键已经被修改过。
- 服务器每次修改一个键之后, 都会对脏(dirty)键计数器的值增一, 这个计数器会触发服务器的持久化以及复制操作执行。