发现系统变慢,执行top或者uptime命令,来了解系统的负载情况

每列的含义:
11:28:54 当前时间
up 650 days,17:35 系统运行时间
2 users 正在登录的用户数
最后load average三个数字分别表示,过去的1分钟、5分钟、15分钟的平均负载
平均负载:单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和cpu使用率没有直接关系
可运行状态进程:正在使用cpu或者正在等待cpu的进程,ps命令看到的处于R的进程
不可中断状态进程:处于内核态关键流程汇总的进程,并且这些流程是不可打断的,比如等待硬件设备的io响应,ps命令中看到的D状态
不可中断状态实际上是系统对进程和硬件设备的一种保护机制
简单理解平均负载就是平均活跃进程数,最理想的就是每个cpu上刚好运行一个进程,这样每个cpu都得到了充分利用,即平均负载最理想的情况就是等于cpu的个数
首先看下系统有多少个cpu

我们服务器是8核的,开了超线程是16
有个cpu个数,可以知道,当平均负载比cpu个数还大的时候,系统就已经出现了过载
当平均负载高于cpu数量70%的时候,就应该排查负载高的问题了,一旦负载高,就可能导致进程响应变慢,今儿影响服务的正常功能
注意点:
1、平均负载高有可能是cpu密集型进程导致的
2、平均负载高并不一定代表cpu使用率高,还有可能是io更繁忙了
3、当发现负载高的时候,你可以使用mpstat pidstat等工具,辅助分析负载的来源
vmstat是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常常用来分析cpu上下文切换和中断的次数

cs:每秒上下文切换的次数
in:每秒中断的次数
r:正在运行和等待cpu的进程数
b:处于不可中断睡眠状态的进程数
vmstat是系统总体的上下文切换,如果想看每个进程的详细情况,使用pidstat
vmstat是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常常用来分析cpu上下文切换和中断的次数
cs:每秒上下文切换的次数
in:每秒中断的次数
r:正在运行和等待cpu的进程数
b:处于不可中断睡眠状态的进程数
vmstat是系统总体的上下文切换,如果想看每个进程的详细情况,使用pidstat
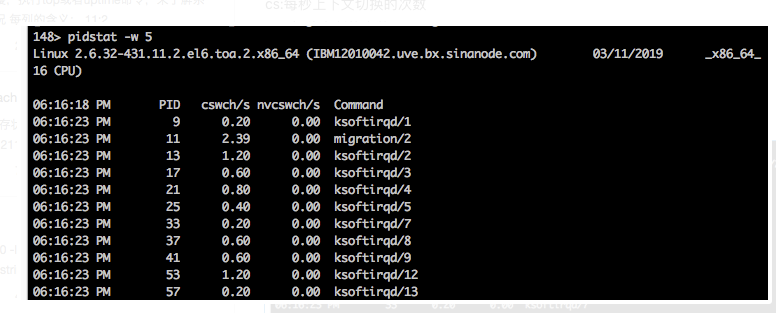
cswch:每秒自愿上下文切换:指进程无法获取所需资源,导致的上下文切换,比如io、内存等系统资源不足时,就会发生资源上下文切换
nvcsich:每秒非自愿上下文切换:指进程由于时间片已到等原因,被系统强制调度,进而发生上下文切换,比如大量进程在争抢cpu时发生
怎么看指标
如果r的值大于cup的个数,说明有大量的cpu在竞争
us + sy这两列使用率加起来上升到100%,说明cpu主要是内核占用了
in列数量特别大,表示中断处理也是潜在的问题
综合以上指标,知道,系统的就绪队列过长,也就是正在运行和等待cpu的进程过多,导致了大量的上下文切换,而上下文切换有导致了系统cpu的占用率升高
使用pidstat来看 cpu和进程上下文切换情况
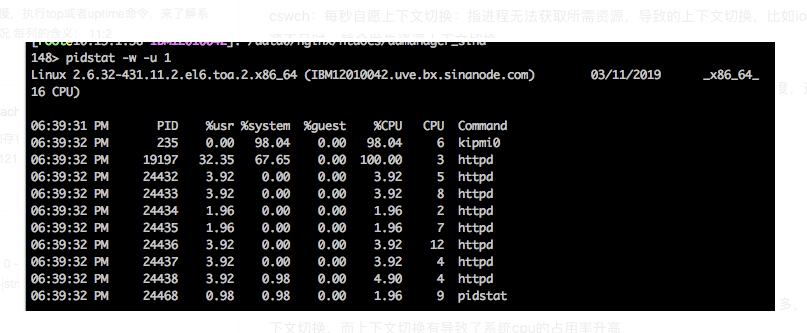
从图上看服务器cpu的升高是由kipmi0造成的
总结:
1、自愿上下文切换变多了,说明进程都在等待资源,有可能发生io等其他问题
2、非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢cpu,说明cup成了瓶颈
3、中断次数多了,说明cup被中断处理程序占用。还需要通过查看/proc/interrupts文件分析
cswch:每秒自愿上下文切换:指进程无法获取所需资源,导致的上下文切换,比如io、内存等系统资源不足时,就会发生资源上下文切换
nvcsich:每秒非自愿上下文切换:指进程由于时间片已到等原因,被系统强制调度,进而发生上下文切换,比如大量进程在争抢cpu时发生
怎么看指标
如果r的值大于cup的个数,说明有大量的cpu在竞争
us + sy这两列使用率加起来上升到100%,说明cpu主要是内核占用了
in列数量特别大,表示中断处理也是潜在的问题
综合以上指标,知道,系统的就绪队列过长,也就是正在运行和等待cpu的进程过多,导致了大量的上下文切换,而上下文切换有导致了系统cpu的占用率升高
使用pidstat来看 cpu和进程上下文切换情况
从图上看服务器cpu的升高是由kipmi0造成的
总结:
1、自愿上下文切换变多了,说明进程都在等待资源,有可能发生io等其他问题
2、非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢cpu,说明cup成了瓶颈
3、中断次数多了,说明cup被中断处理程序占用。还需要通过查看/proc/interrupts文件分析