论文信息:论文
1. 概述
分布式表示在诸多自然语言处理系统中应用十分广泛,比如wrod2vec中每个单词被转换为一个全局向量。但这种方式忽略了单词的上下文信息,同一单词在不同的上下文中表示相同。因此近年来上下文嵌入方法风生水起,获得了快速发展和普遍关注。该论文就是对这些上下文嵌入方法的一篇综述。
假定语料库由一个句子(mathcal{S}={t_1,t_2,dots,t_N})构成,(t_i)是句子中的的单词。传统词向量技术就是要学习一个矩阵(mathbf{E} in mathbb{R}^{V imes d}),其中(V)是词汇表大小,(d)是每个词向量的维度。而上下文嵌入则可以表示为(mathbf{h}_{t_i}=f(e_{t_1},e_{t_2},dots,e_{t_N})),(e_{t_i})通常就是传统词向量方法获得的词嵌入。可以看到单词(t_i)的向量(mathbf{h}_{t_i})是和句子上下文有关的。但(f)的选择却是多种多样的,也就是各种各样的上下文嵌入方法。
2. 预训练语言模型
2.1 无监督预训练
学习词向量最典型的方式就是通过语言建模。所谓语言建模就是通过最大似然估计(MLE)建模单词序列的概率分布。一般来讲,就是给定句子中前(i-1)个单词,对第(i)个单词进行估计。
2.1.1 最早方法
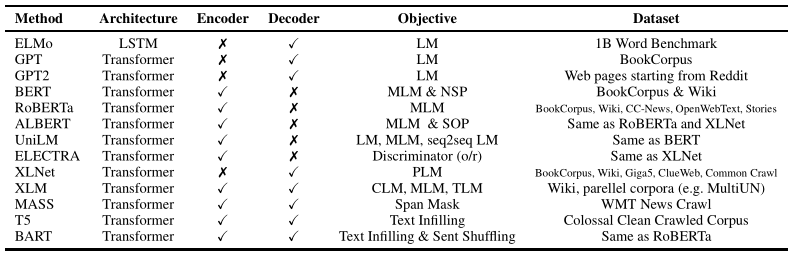
Dai and Le(2015)使用语言建模和序列自动编码器来改善循环网络的序列学习,它可以被认为是现代上下文嵌入方法的前身。在数据集IMDB,Rotten Tomatoes,20 Newsgroups和DBpedia上进行了预训练,然后对模型进行了情感分析和文本分类任务的微调,与随机初始化的模型相比,该模型具有出色的性能。
Ramachandran et al.(2016)拓展上述方法,提出了利用预训练方法来提高序列到序列(seq2seq)模型的准确性。
2.1.2 ELMo

ELMo (Peters, Matthew E., et al. 2018)使用前向LSTM捕获从左往右信息,使用后向LSTM捕获从右往左信息。然后将这两部分信息进行整合,得到单词的上下文信息。在实际模型中,这样的前向后向LSTM网络可能是多层的。
2.1.3 GPT, GPT2
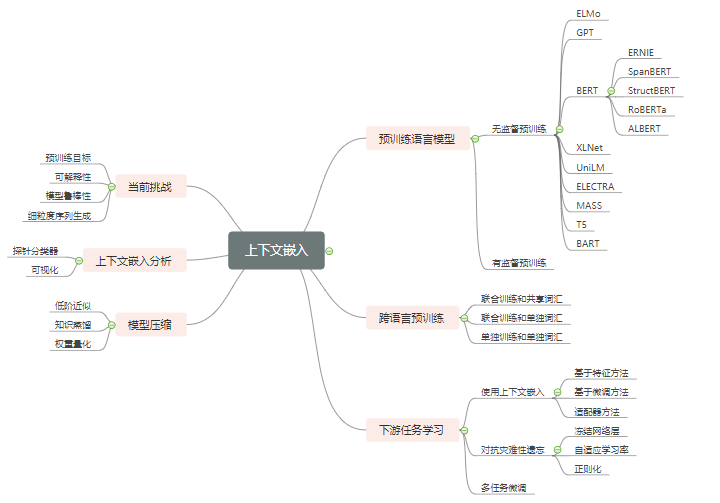
GPT(Radford et al., 2018)采用了两个阶段的学习范式:1)使用语言建模进行无监督预训练;2)有监督的下游任务微调。GPT使用多层Transformer结构,其中一层的结构图如下:
GPT2 (Radford et al., 2019) 的模型结构和GPT差不多,但论文使用了更大的数据量进行训练。但是,GPT2将文本分解成字节并用BPE (Sennrich et al., 2016) 构建词典,可能是这个方式给它带来了效果提升。
2.1.4 BERT
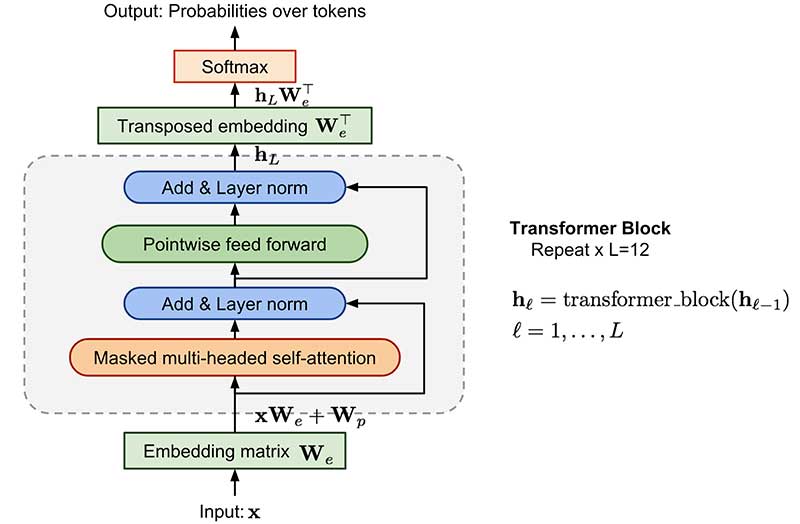
ELMo单纯地将前后向信息拼接,未考虑到它们之间的交互。而GPT(2)使用从左往右的解码器,每个单词只能获得上文信息。因此BERT (Devlin, Jacob, et al., 2018)决定真正地融合双向信息,具体而言提出了两个学习任务:1)Masked语言建模(MLM),首先Mask文本中的部分单词,然后通过上下文信息对Mask的单词进行预测;2)Next-sentence-prediction(NSP),即预测两个句子的前后关系。BERT的模型示意图如下:
同样的,本论文也指出无法确定BERT的效果是来自于新的训练目标还是更大的训练数据集。
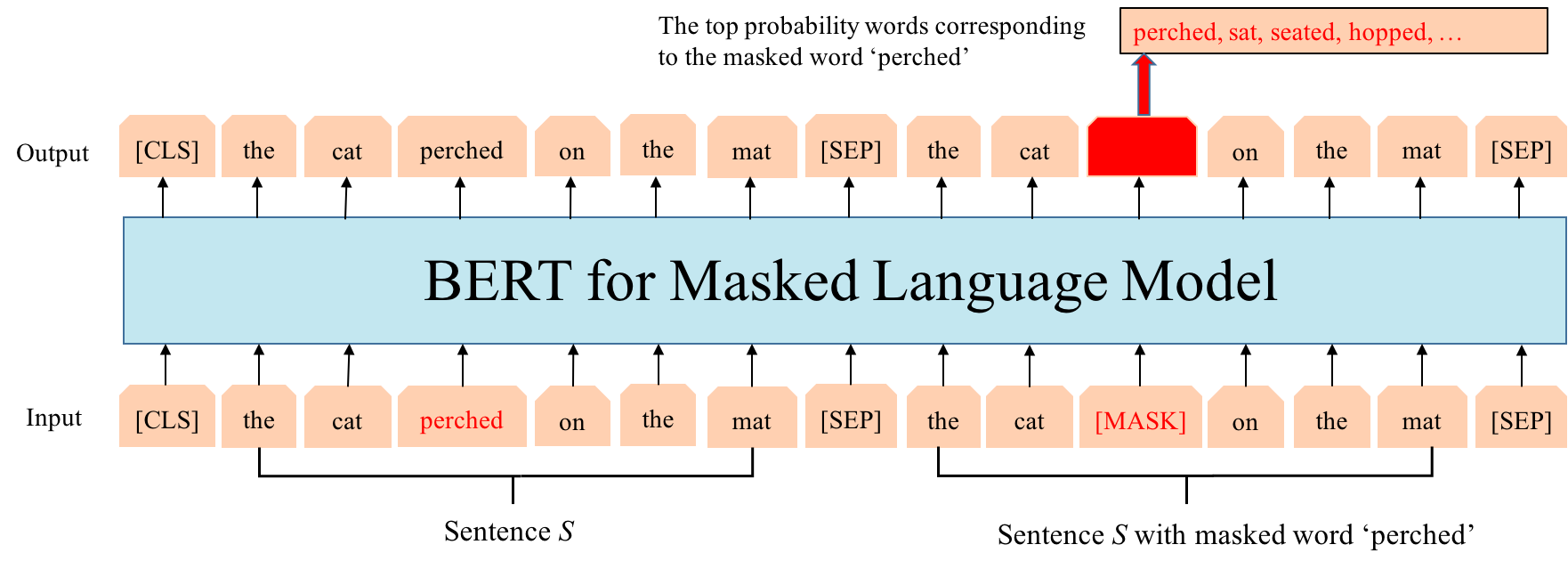
此时我们可以对BERT,GPT和ELMo做一个对比,下面这张图比较清晰地说明了它们之间的区别:
2.1.5 BERT变体
ERNIE (Zhang et al., 2019)引入了知识Mask策略,包括实体级Mask和短语级Mask,用以取代BERT中的随机Mask。
SpanBERT (Joshi et al.,2019)对ERNIE进行泛化,在无需外部知识的情况下随机Mask跨度(span)。
StructBERT (Wang et al.,2019b)提出了一个词结构目标,随机排列3-gram顺序然后进行重构。同时提出了一个句子结构目标,预测了两个连续段的顺序。
RoBERTa (Liu et al.,2019c)对BERT模型进行了一些更改,包括:1)使用更大的批次和更多的数据对模型进行更长的训练;2)取消NSP任务;3)在更长的序列上训练;4)在预训练过程中动态更改Mask位置。
ALBERT (Lan et al., 2019) 提出了两个参数优化策略以减少内存消耗并加速训练。此外,ALBERT还对BERT的NSP任务进行了改进。
2.1.6 XLNet
XLNet (Yang et al., 2019)的提出是为了解决BERT中存在的两个问题:1)BERT认为Mask的单词之间是独立的;2)BERT使用了实际不存在的[MASK]符号,这会导致训练与微调出现差异。因此XLNet基于排列语言建模(PLM)提出了一个自回归的方法,并引入了双流自注意力机制和Transformer-XL实现模型。
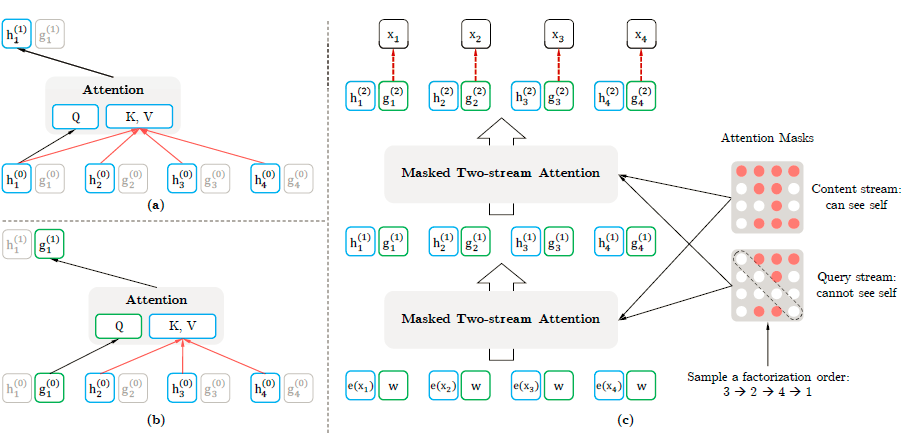
2.1.7 UniLM
UniLM (Dong et al., 2019)模型将语言建模,Mask语言建模和序列到序列语言建模结合进行预训练。
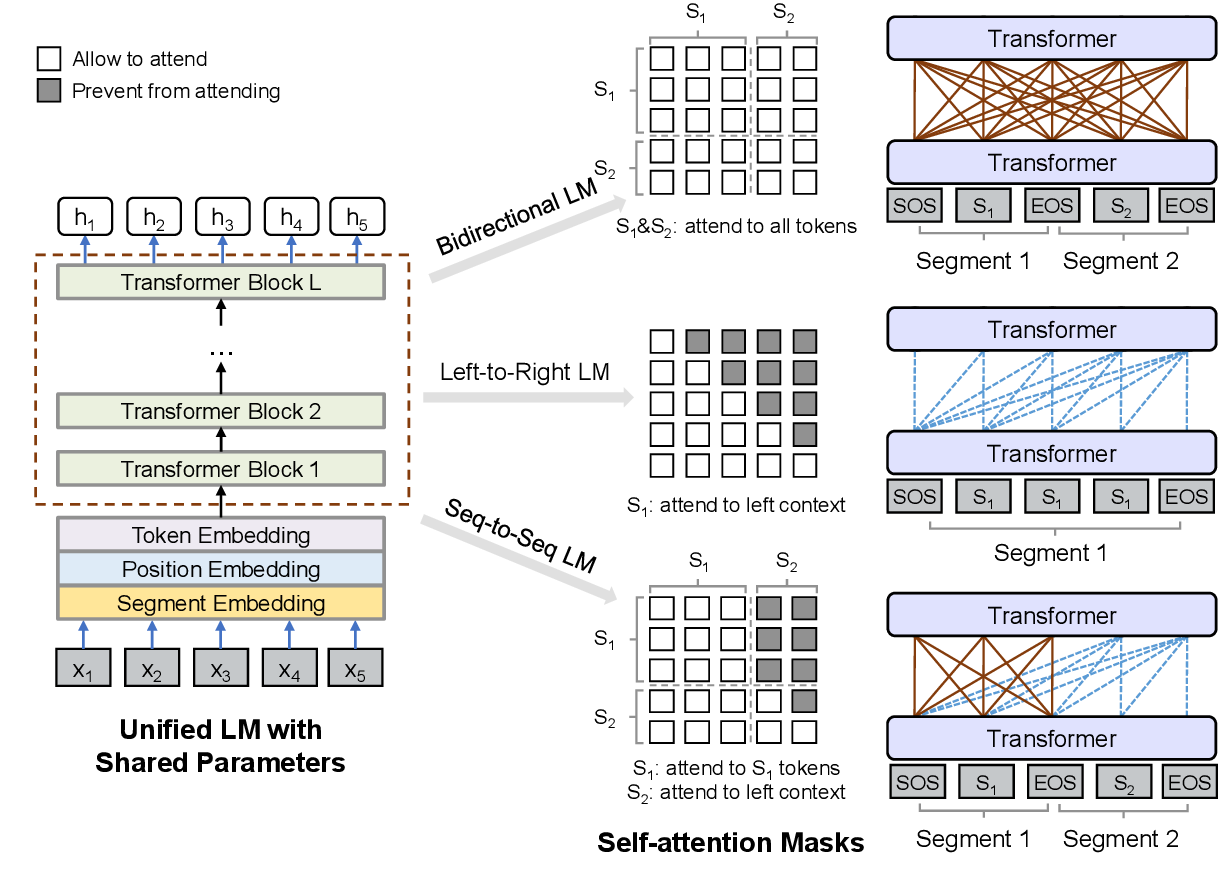
2.1.8 ELECTRA
与BERT相比,ELECTRA (Clark et al., 2019)提出了一种更有效的预训练方法。ELECTRA使用生成器生成的单词替换文本的某些位置,同时训练判别器判断每个位置的单词是否是被生成器替换的。
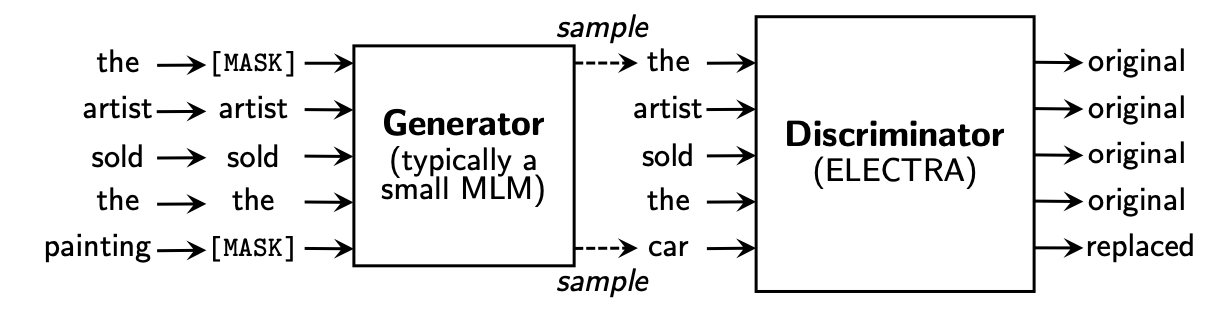
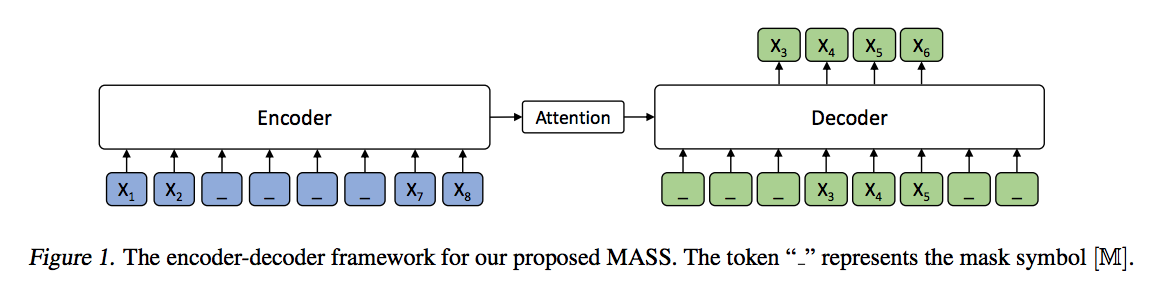
2.1.9 MASS
BERT无法进行自然语言生成,因此MASS (Song et al., 2019)使用Mask序列的方式来预训练序列到序列模型。具体地说,MASS采用了编码器-解码器框架。编码器输入一个序列,其中连续的单词被Mask,解码器自回归地预测这些被Mask的连续单词。
2.1.10 T5
Raffel et al., (2019)提出了T5(Text-to- Text Transfer Transformer),通过将数据转换为文本到文本格式并应用编码器-解码器框架来统一自然语言的理解和生成。

2.1.11 BART
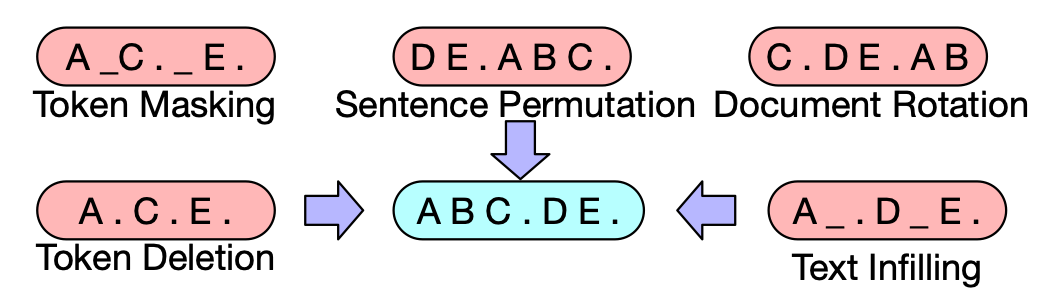
BART (Lewis et al., 2019)引入了除MLM之外的其他噪声方法,用于预训练序列到序列模型。首先,使用任意的噪声方法扰乱输入序列。然后,扰乱的输入由使用teacher forcing训练的Transformer网络重建。BART尝试了各种噪声方法,包括token masking, token deletion, text infilling, document rotation, and sentence shuffling (randomly shuf-fling the word order of a sentence)。
以上无监督预训练方法的比较如下表所示:
2.2 有监督预训练
受到计算机视觉领域有监督预训练的启发,NLP领域也有许多工作在数据丰富的任务上有监督地学习可迁移表示。
CoVe (McCann et al., 2017)提出了从机器翻译中学习到的上下文嵌入可以用于其它下游任务。InferSent (Conneau et al., 2017)从预训练的自然语言推理模型中获得上下文化表示。Subramanian et al., (2018)使用多任务学习来预训练序列到序列模型以获取上下文嵌入。
3 跨语言预训练
跨语言多语种预训练旨在学习联合多语言向量表示,使知识能够从数据丰富的语言(如英语)转移到数据稀缺的语言(如罗马尼亚语)。 基于是否使用联合训练和共享词汇,先前的工作可以分为三类。
3.1 联合训练和共享词汇
这类方法在多种语言上同时训练,并且多种语言共享一份词汇。典型的方法有Artetxe and Schwenk (2019)、Rosita (Mulcaire et al., 2019)、multi-lingual BERT、XLM (Lample and Conneau, 2019)和XLM-R (Conneau et al., 2019)。
3.2 联合训练和独立词汇
这类方法对多种语言同时训练,但是不同语言具有不同的词汇表。Wu et al. (2019)发现即使在多种语言之间没有共享的词汇,并且在不同语言的嵌入空间中存在普遍的潜在对称性时,也可以进行跨语言的转移。
3.3 独立训练和独立词汇
这类方法每次只在一种语言上训练,同时每种语言有自己的词汇表。典型方法有Artetxe et al. (2019)。
4 下游任务学习
一旦获得了上下文词嵌入,我们就能将之应用于各种下游任务,比如情感分析、机器阅读理解等。
4.1 在下游任务种使用上下文嵌入
4.1.1 基于特征的方法
ELMo的应用就是典型的基于特征方法。在使用时,ELMo的预训练模型层权重将会被冻结,每层的输出通过线性组合后输出为下游任务的特征。
4.1.2 基于微调的方法
这种方式一般在预训练语言模型之上再添加任务相关的模型,两部分同时进行训练,但通常预训练模型部分只做微小的调整。一种典型的方式是在BERT上使用全连接层做文本分类。
4.1.3 适配器方法
这类方法将适配器作为小模块添加到预训练模型各层之间。训练时,预训练模型参数固定不动,只调整适配器的参数。与为每种任务单独微调相比,这种方法通过共享适配器有效减少参数。典型模型有Rebuffi et al., (2017)和Stickland and Murray, (2019)。
4.2 对抗灾难性遗忘
在下游任务上学习容易覆盖预训练模型中的信息,这被称为“灾难性遗忘”。目前有以下三类方法改进。
4.2.1 冻结网络层
通过对神经网络进行分层训练,在训练某些层的同时冻结其他层,可以减少微调过程中的遗忘。已有多种不同的逐层训练方法被研究,比如:Long et al., (2015)冻结除顶层以外的所有层;Howard and Ruder (2018)从上到下逐层冻结等等。
4.2.2 自适应学习率
通常就是在更低的层中使用更小的学习率,因为更低的层往往蕴含的是不同任务之间的公共知识。
4.2.3 正则化
通过正则化让微调的参数和预训练参数不至于相差太大,比如可以使用欧氏距离或者Fisher信息矩阵进行约束(Kirkpatrick et al., 2017) 。
4.3 多任务微调
对下游任务进行多任务学习可以获得跨任务的一般表示,并在每个单独的任务上均实现出色的性能。比如,MT-DNN (Liu et al., 2019b)在所有GLUE任务上微调BERT,将GLUE基准提高到82.7%。T5(Raffel et al., 2019)研究了多任务学习的各种设置,发现在对每个任务进行微调之前使用多任务学习表现最佳。
5 模型压缩
预训练语言模型通常参数数目十分庞大,因此模型压缩研究也获得了诸多关注,主要方法有以下三类。
5.1 低阶近似
该类方法试图将满秩模型权重矩阵压缩为低秩矩阵,从而减少模型参数的有效数量。ALBERT就是一个例子。
5.2 知识蒸馏
Hinton et al., (2015)提出了一种称为“知识蒸馏”的方法,将教师网络中编码的“知识”转移到学生网络。DistilBERT (Sanh et al., 2019)使用MLM、蒸馏损失、以及教师和学生网络的嵌入矩阵之间的余弦相似度来训练较小的BERT模型。类似的模型还有BERT-PKD (Sun et al., 2019)和TinyBERT (Jiao et al., 2019)。
5.3 权重量化
量化方法的重点是将权重参数映射到低精度整数和浮点数。 Q-BERT (Shen et al., 2019)提出了一种基于组的量化方案。其中,基于注意力头将参数分为几组,并使用基于Hessian的混合精度方法压缩模型。
6 上下文嵌入分析
尽管上下文嵌入方法在多种自然语言任务中具有出色的性能,但通常不清楚为什么它们如此有效。为了对此进行研究,目前的方法主要有两类:1)探针分类器;2)可视化。
6.1 探针分类器
大量的研究工作使用探针(probe)研究上下文嵌入。探针分类器是受约束的分类器,旨在探索上下文表示是否编码了句法和语义信息。
比如,Jawahar et al., (2019)使用了十个句子级别的探测任务(例如SentLen,TreeDepth),发现BERT在较低的层中捕获了短语级别的信息,并在较深的层中捕获了远程依赖信息。
6.2 可视化
另一类工作是使用可视化来分析注意力机制或者和微调等过程。
比如,Kovaleva et al., (2019)对BERT的注意力头进行可视化,发现了不同注意力头之间共有一部分注意力模式集合,这说明了BERT的注意力头非常冗余。手动禁用某些注意力头后,与使用所有注意力头的微调BERT模型相比,可以获得更好的性能。
7 当前挑战
目前上下文表示学习仍存在许多挑战,主要有:1)设计更好的预训练目标;2)预训练模型的可解释性;3)模型鲁棒性;4)更细粒度的序列生成。
