1.安装lxml库
pip install lxml
2.lxml用法
例子:
首先我们利用它来解析 HTML 代码,先来一个小例子来感受一下它的基本用法。
1 from lxml import etree
2
3 text = '''
4 <div>
5 <ul>
6 <li class="item-0"><a href= "link1.html">first item</a></li>
7 <li class="item-1"><a href= "link2.htm2">second item</a></li>
8 <li class="item-inactive"><a href= "link3.html">third item</a></li>
9 <li class="item-1"><a href= "link4.html">fourth item</a></li>
10 <li class="item-0"><a href= "link5.html">fifth item</a>
11 </ul>
12 </div>
13 '''
14 html = etree.HTML(text)
15 result = etree.tostring(html)
16 print result
首先我们使用 lxml 的 etree 库,然后利用 etree.HTML 初始化,然后我们将其打印出来。
其中,这里体现了 lxml 的一个非常实用的功能就是自动修正 html 代码,大家应该注意到了,最后一个 li 标签,其实我把尾标签删掉了,是不闭合的。不过,lxml 因为继承了 libxml2 的特性,具有自动修正 HTML 代码的功能。
所以输出结果不仅补全了 li 标签,还添加了 body,html 标签,如下:

文件读取
除了直接读取字符串,还支持从文件读取内容。比如我们新建一个文件叫做 lzc.html,内容为:
1 <div>
2 <ul>
3 <li class="item-0"><a href= "link1.html">first item</a></li>
4 <li class="item-1"><a href= "link2.htm2">second item</a></li>
5 <li class="item-inactive"><a href= "link3.html">third item</a></li>
6 <li class="item-1"><a href= "link4.html">fourth item</a></li>
7 <li class="item-0"><a href= "link5.html">fifth item</a></li>
8 </ul>
9 </div>
利用 parse 方法来读取文件:
1 html = etree.parse('lzc.html')
2 result = etree.tostring(html,pretty_print=True)
3 print result
这种情况下lxml 没有自动修正 html 代码,且大如果标签不完整,会报错:

XPath实例测试
(1)获取所有的 <li> 标签:
1 html = etree.parse('lzc.html') 2 print type(html) 3 result= html.xpath('//li') 4 print result 5 print len(result) 6 print type(result) 7 print type(result[0])
运行结果:

可见,etree.parse 的类型是 ElementTree,通过调用 xpath 以后,得到了一个列表,包含了 5 个 <li> 元素,每个元素都是 Element 类型
(2)获取 <li> 标签的所有 class:
html = etree.parse('lzc.html') result = html.xpath('//li/@class') print result
运行结果
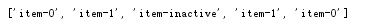
(3)获取 <li> 标签下 href 为 link1.html 的 <a> 标签
html = etree.parse('lzc.html') result1= html.xpath('//li/a[@href="link1.html"]') print result1
运行结果

(4)获取 <li> 标签下的所有 <span> 标签
注意这么写是不对的
result2=html.xpath('//li/span')
因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠
html = etree.parse('lzc.html') result2=html.xpath('//li//span') print result2
运行结果