20182330《程序设计与设计结构》 第六周学习总结
教材学习内容总结
面向对象设计技术
solid原则:
面向对象的原则是面向对象设计的核心, 面向对象五大原则有SRP、OCP、LSP、DIP、ISP
SRP(Single Responsibility Princple单一职责原则)一个设计元素只做一件事。之前一直在讨论这件事,(上帝类与小类)小类容易复用.
高内聚低耦合:与自己无关的拿出去,使用时调用,灵活
OCP(Open Close Princple)
“Closed for Modification; Open for Extension”:对扩充开放 对修改封闭
OCP背后的机制:抽象和多态
软件实体(类。模块。函数)应该对
LSP:(Liskov Substitution Principle 里氏替换原则)Liskov是这个原则的提出者。理解起来就像大于5的数一定大于2,子能存在的地方父一定可以。
DIP(Dependence Inversion Principle 依赖倒置原则)要依赖于抽象,不要依赖于具体。
子类可以被基类替代 不能滥用继承
ISP:(Interface Segregation Principle 接口分隔原则)一个接口相当于剧本中的一种角色,而此角色在一个舞台上由哪一个演员来演则相当于接口的实现。因此一个接口应当简单的代表一个角色,接口隔离原则讲的就是同一个角色提供宽、窄不同的接口,以对付不同的客户端。
字节流与字符流输入与输出:
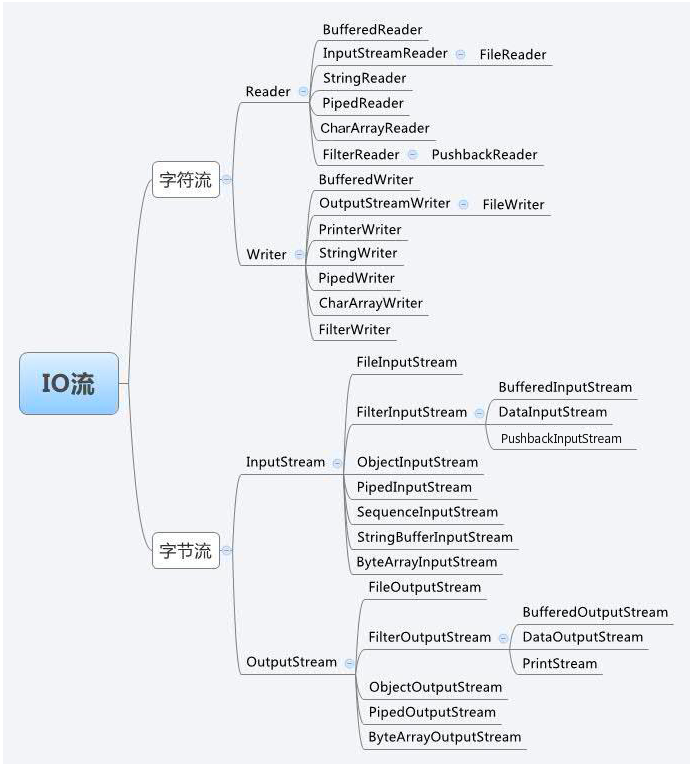
教材学习中的问题和解决过程
-
问题1:什么是流?
-
问题1解决方案:流是个抽象的概念,是对输入输出设备的抽象,输入流可以看作一个输入通道,输出流可以看作一个输出通道。
输入流是相对程序而言的,外部传入数据给程序需要借助输入流。
输出流是相对程序而言的,程序把数据传输到外部需要借助输出流。 -
问题2:inputStream1.available是什么意思
-
问题2解决方案:要一次读取多个字节时,经常用到InputStream.available()方法,这个方法可以在读写操作前先得知数据流里有多少个字节可以读取。
-
需要注意的是,如果这个方法用在从本地文件读取数据时,一般不会遇到问题,但如果是用于网络操作,就经常会遇到一些麻烦。比如,Socket通讯时,对方明明发来了1000个字节,但是自己的程序调用available()方法却只得到900,或者100,甚至是0,感觉有点莫名其妙,怎么也找不到原因。其实,这是因为网络通讯往往是间断性的,一串字节往往分几批进行发送。本地程序调用available()方法有时得到0,这可能是对方还没有响应,也可能是对方已经响应了,但是数据还没有送达本地。对方发送了1000个字节给你,也许分成3批到达,这你就要调用3次available()方法才能将数据总数全部得到。
-
问题3:BufferWriter中 writer()与append()的区别
-
问题3解决方案:write是重写,不论原来有没有内容,内容是什么,都覆盖掉。append是追加,在原来的基础上继续写。
代码调试中的问题和解决过程
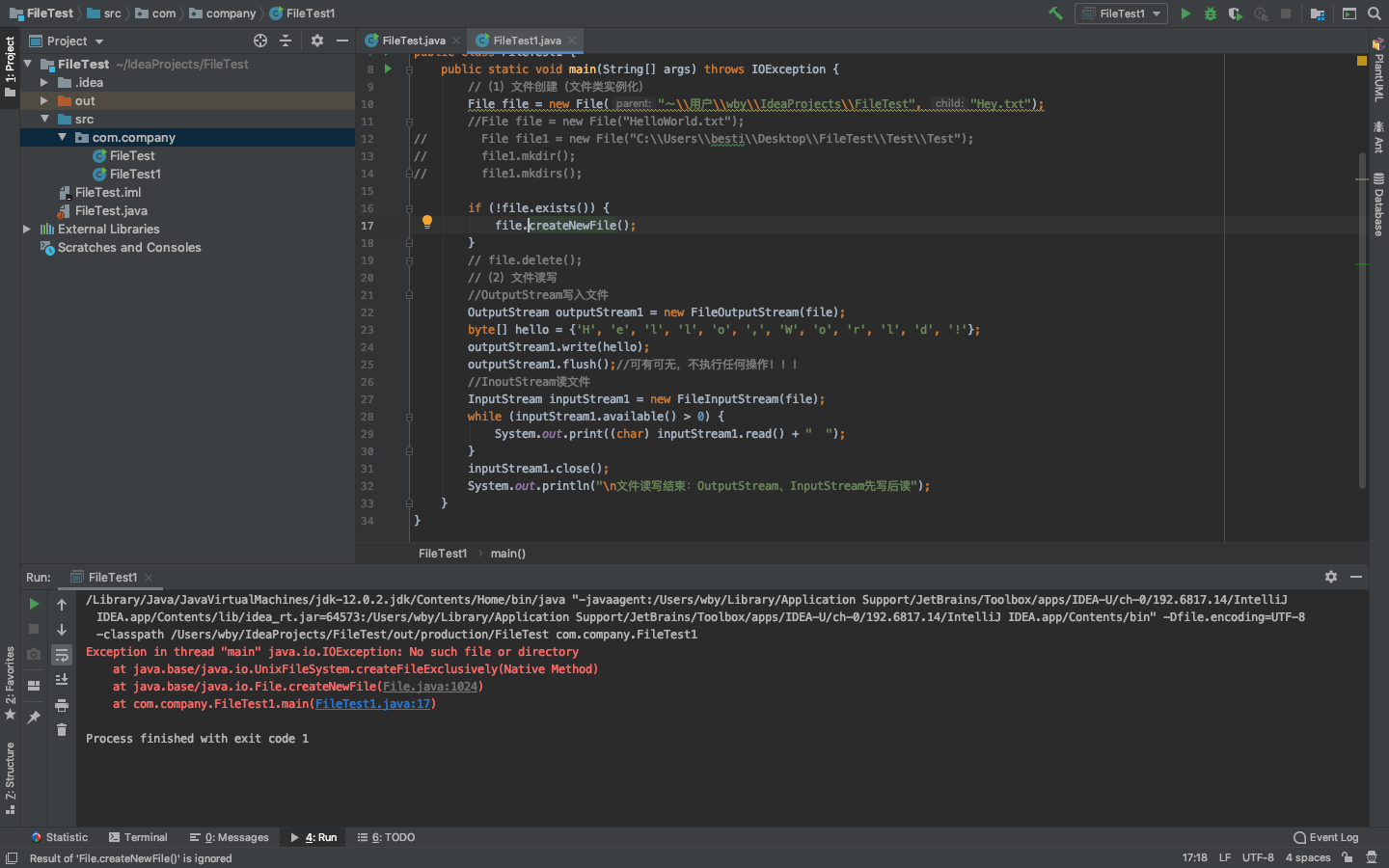
- 问题1:文件创建不了,一直报错。
-
问题1解决方案:报错的原因原来是文件的路径不对,使用了各种方式改才知道路径中不能有中文。这些细节值得注意。
-
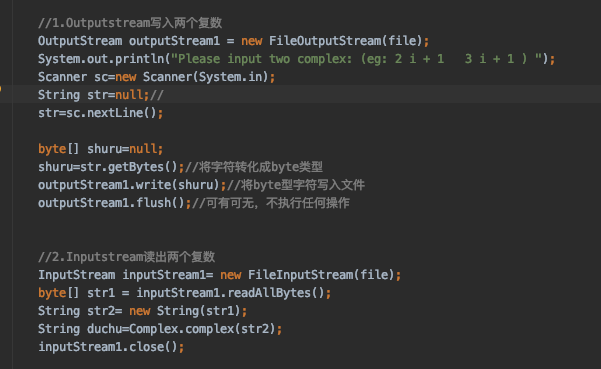
问题2:不太理解什么是byte类型,为什么只有Byte类型才能通过字节流传输。
-
问题2解决方案:因为计算机处理数据的单位就是字节。所以,当我们处理磁盘文件和内存数据的时候,就正好选择和计算机处理数据单位等大的数据类型来存储数据。而且,我们调用的类库中的API也都是使用这样类型的参数。所以,我们就必须在编写程序的时候使用byte类型的数组。
代码托管

上周考试错题总结
- 错题1
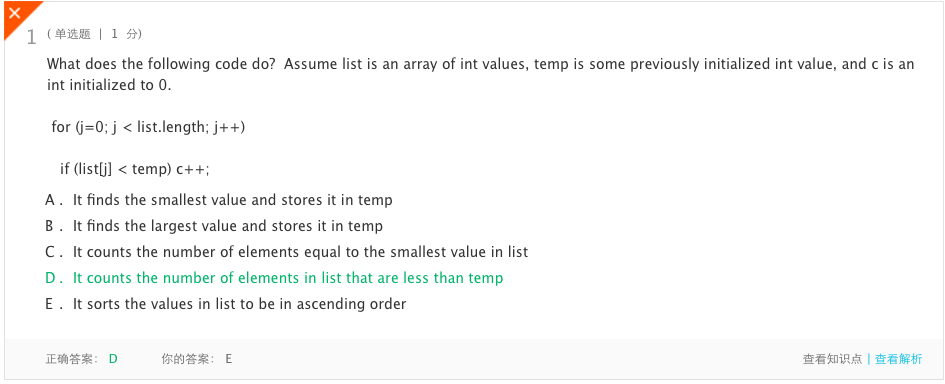
- 分析:语句if (list[j] < temp) c++;将list中的每个元素与temp进行比较,并仅在元素小于temp时将一个元素添加到c中,因此它计算list中小于temp的元素数量,并将结果存储在c中。
- 错题2

- 分析:选择排序和插入排序都可以“就地”实现。这意味着不需要额外的内存,排序后的数据只是在数据数组中进行重新排列。排序还没有学到。
- 错题3

-
分析:向上转换是完全安全的——它是Java支持的单一继承结构的产物。相比之下,向下转换必须由程序员显式地完成。Java只在一个方向自动进行数据类型转换。上抛和下抛的规则不以任何方式依赖于使用的可见性修饰符。
-
错题4
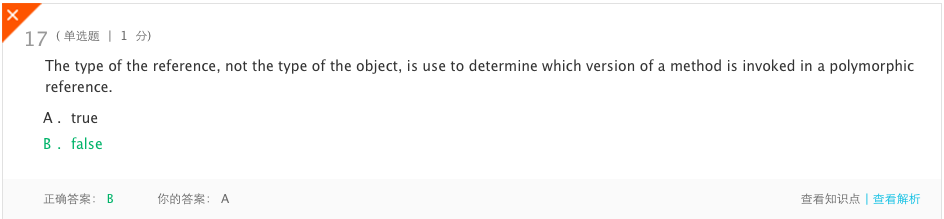
-
分析:决定调用哪个方法的是对象的类型,而不是引用的类型。
-
错题5
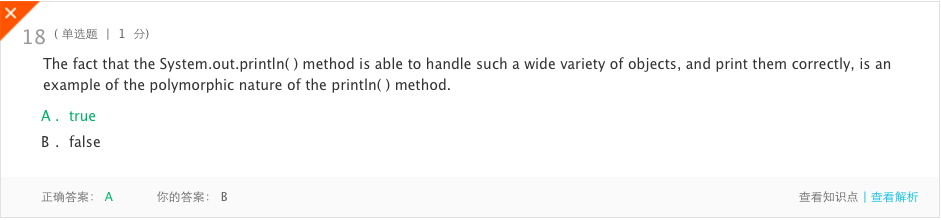
- 分析:由于println()本质上是高度多态的,所以它能够正确地打印各种预定义(库)和内置(原语)数据。
- 错题6
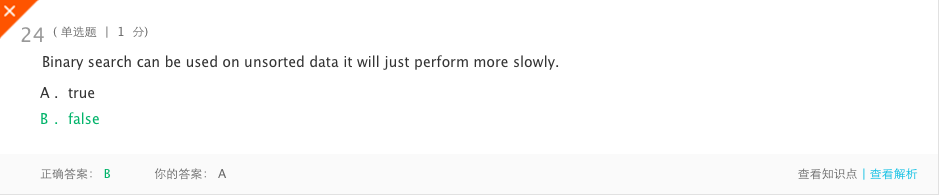
- 分析:只在数据排序的情况下有效。每对数据元素之间存在严格的升序或降序关系。没有学,就先学一下。
- 错题7
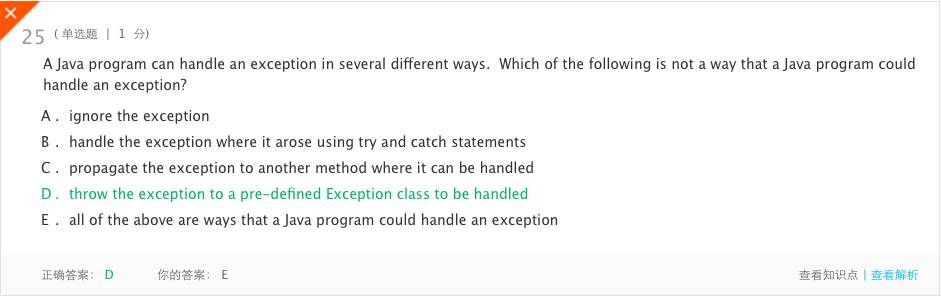
- 分析:抛出异常是被当前的代码如果代码包含在一个try语句和适当的catch语句实现,否则是传播的方法调用的方法引起的异常,在一个合适的声明,否则继续传播通过相反的顺序的方法,这些方法被调用。但是,一旦到达主方法,这个过程就会停止。如果没有被捕获,异常将导致程序终止(这将是答案a,异常被忽略)。但是,不会将异常抛出给异常类。概念不清。
- 错题8

- 分析:调用堆栈跟踪提供存储在运行时堆栈中的方法的名称。方法名称从堆栈中删除以相反的顺序放置,也就是说,最早的方法是先放在这里,下一个方法其次,等等,所以最近调用的方法是在堆栈上最后一项,这是第一个删除。堆栈跟踪然后显示所有活动方法的调用顺序(最近一次)。
- 错题9
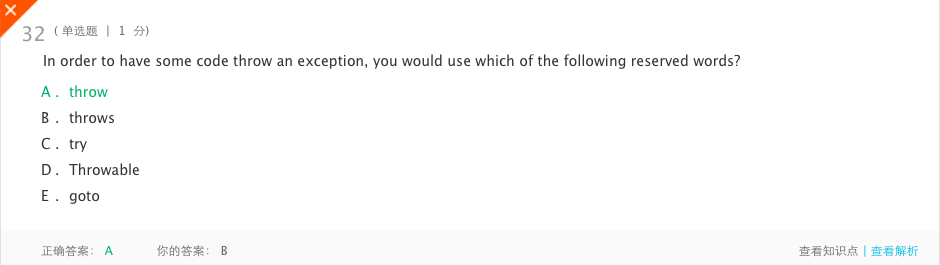
-
分析:throws出现在方法函数头;而throw出现在函数体。
throws表示出现异常的一种可能性,并不一定会发生这些异常;throw则是抛出了异常,执行throw则一定抛出了某种异常对象。
两者都是消极处理异常的方式(这里的消极并不是说这种方式不好),只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。 -
错题10

- 分析:B、C和D中的答案都是正确的,runtimeexception是可抛出的对象,不属于Error类,有两种类型的runtimeexception是arithomeexception和NullPointerException。非runtimeexception的异常包括各种已检查的异常,但runtimeexception不是已检查的异常。
- 错题11

- 分析:数据流表示特定的源或目标流,用于输入或输出。处理流类似于数据流,其中一些附加的流程被添加到输入或输出中。例如,处理字节流可能会从文件中输入所有项,并删除任何非数字的ASCII字符,以便预期为数字的输入不会引发NumberFormatException。
- 错题12
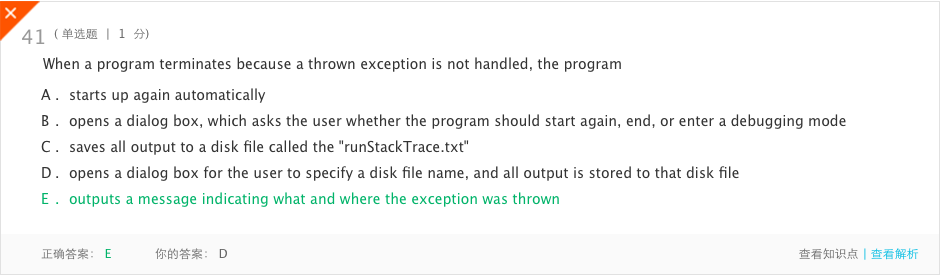
- 分析:如果在程序的任何地方都没有捕捉到抛出的异常,则程序终止,显示运行堆栈跟踪的内容。运行堆栈跟踪的第一项是抛出的异常及其抛出位置(抛出异常的类的方法的行号)。
- 错题13

- 分析:选中的异常必须被捕获,或者必须在一个抛出子句中列出。未检查的异常不需要抛出子句。这两种异常都遵循异常传播的规则。
- 错题14
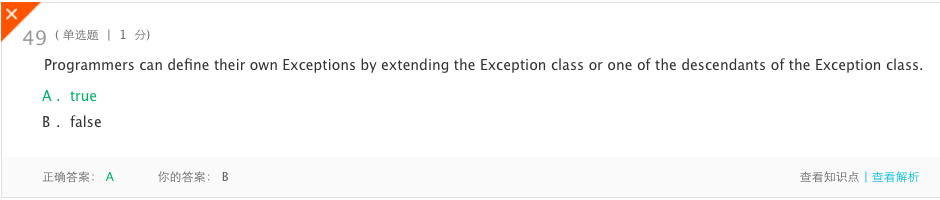
- 分析:Java预先定义了许多异常类,以便能够处理许多可能导致程序终止的异常类型。然而,Java允许程序员通过为他们可能遇到的任何独特情况定义他们自己的异常来添加到语言中。这些新的异常或者是Exception类的子异常,或者是子类的子异常,或者是Exception的后代异常。
结对及互评
点评过的同学博客和代码
-
本周结对学习情况
- 20182314
- 点评:知识点总结的较为详细,错题总结深入。但是代码的问题理解不深。
基于评分标准,我给本博客打分:14分。得分情况如下:
感想,体会不假大空的加1分
排版精美的加一分
结对学习情况真实可信的加1分
正确使用Markdown语法
模板中的要素齐全(加1分)
错题学习深入的加1分
点评认真,能指出博客和代码中的问题的加1分
教材学习中的问题和解决过程, 加5分
代码调试中的问题和解决过程,加2分
-
上周博客互评情况
其他(感悟、思考等,可选)
就这样匆忙进入Android的学习,步伐更加紧张了,之前没有搞懂的知识要继续学习,并且一遍更进新的内容。希望能学得务实和认真。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 42/42 | 2/2 | 20/20 | |
| 第三周 | 394/471 | 2/4 | 25/45 | |
| 第四周 | 394/471 | 2/4 | 25/45 | |
| 第五周 | 1668/2139 | 2/6 | 35/80 | |
| 第六周 | 2388/4527 | 1/7 | 30/110 |
-
计划学习时间:25小时
-
实际学习时间:30小时
-
改进情况:希望提高效率