1 内聚
模块
语义上连续的一系列语句, 由边界符界定, 并且有一个聚集标识符
常见的模块
在面向对象中的 类, 方法
在面向过程的 函数
模块功能单一, 内部交互程度最大, 模块之间交互程度为最小
模块的内聚: 模块内部的交互程度
模块的耦合: 模块之间的交互程度
模块的内聚性从低到高分为7种:
偶然内聚 --> 逻辑内聚 --> 时间内聚 --> 过程内聚 --> 通信内聚 --> 功能内聚 --> 信息内聚
软件模块的内聚性越低越差, 越高越好
1) 偶然内聚: 模块内部的内容毫不相干
问题: 可读性低, 可维护性低, 可重用性低
解决: 拆分成不同的模块
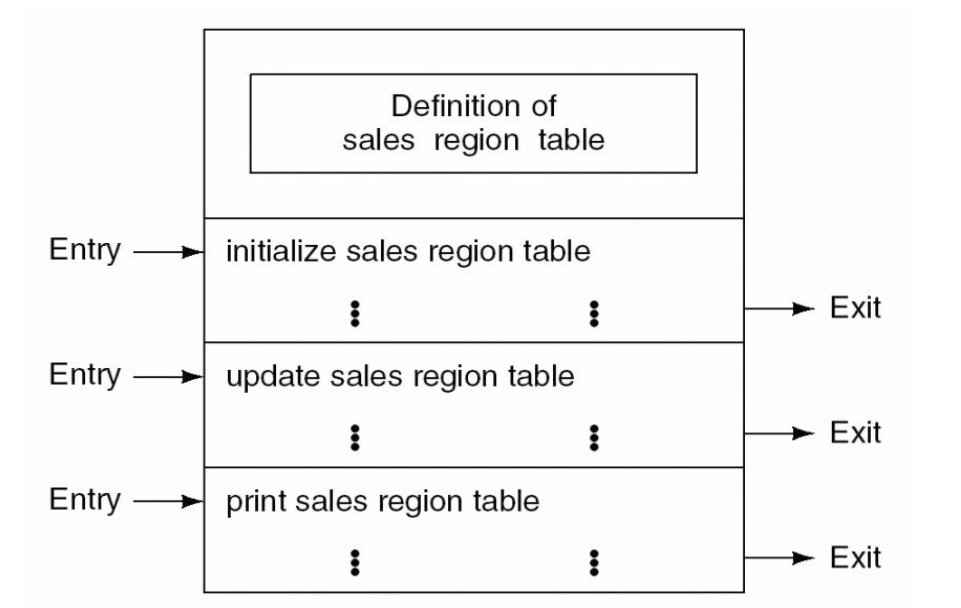
2) 逻辑内聚: 合并后的EFG就是逻辑性内聚

问题: 接口复杂, 内部复杂, 内部难以修改, 效率低, 增加了调用模块和被调用模块的耦合度
3) 时间性内聚: 在相同时间需要做的一些操作, 但是可能在本质上没有什么关联性
问题: 模块内部关联度比较弱, 但是和别的模块可能关联性较强, 一般不可重用
4) 过程内聚: 模块内部操作必须有先后顺序
问题: 内部之间多个操作不是相互关联的, 只是有先后顺序, 因此该代码不容易被重用
5) 通信内聚: 模块内部可能有多个操作, 这些操作是基于相同的输入数据或者输出数据
问题: 主要是重用性较低
6) 功能内聚:只具有一个功能或者一个操作
将之前的内容进行拆分形成的
具有较高的重用性
纠错修改也比较容易, 减少更少的回归错误
更加容易扩展
7) 信息内聚: 执行多个任务, 每个任务都有自己的入口点,相对独立的代码, 并且在相同的数据结构进行操作
2 耦合
模块的耦合, 模块之间的交互程度, 越低越好
内容耦合 --> 公共耦合 --> 控制耦合 --> 印记耦合 --> 数据耦合
1) 内容耦合: 一个模块可以直接访问另一个模块内部内容
实例: 在一个类中, 可以直接访问类中某个变量并且可以进行一系列的操作
class A:
name = 'a'
class B:
mA = A()
def setItem(self):
self.mA.name = 'aa'
2) 公共耦合: 两个模块存取相同的变量(常见的是全局变量)
尽量减少公共耦合, 尽量减少全局变量的使用, 防止全局变量在多个模块被修改
3) 控制耦合: 一个模块向另一个模块传递控制参数, 最常见的就是传递开关变量, 而且必然导致被调用模块的逻辑内聚

解决办法, 把逻辑判断模块写到A中, 将B的两个功能拆分成两个模块
4) 印记耦合: 一个模块传入另一个模块的封装数据, 但是具体在模块中只使用一部分数据
例如在类A中传入B的对象, 在A中只是使用B的两个成员变量
class A:
name = 'a'
age = 18
sex = 'male'
class B:
def setItem(self, obj):
self.name = obj.name
self.age = obj.age
b = B( A() )
问题: 接口不清晰, 如果不通读代码, 不会知道哪些数据是需要的哪些是不需要的, 降低了可读性, 非常难重用
5) 数据耦合: 所有参数都是同构的参数, 或者简单的数据, 或者是简单的数据结构且内部的数据都被使用
3 数据封装和信息隐藏
诸如操作系统的任务队列
如果对每个操作写成一个模块, 固然是好事, 但是如果操纵的数据结构更改则所有就要更改
所以形成新一个模块, 给各个操作共同使用一个数据结构
这样就形成了信息内聚, 也是对数据的一种封装
数据封装的优势:
1) 这样的数据结构+数据操作 就形成了数据抽象, 使得编写最开始专注于数据结构和操作, 而不局限于怎么实现某些操作
2) 在维护上, 数据封装可以使以后代码改动最小化, 减少出现回归错误的出现可能性
信息隐藏: 对外提供接口, 而隐藏具体的实现细节
4 类的继承
类: 抽象数据类型
对象: 类派生出来的实例
继承: 子类继承父类, 会取得父类所有的公开内容
在UML中, 继承是用一个空心箭头指向, 被指向的是父类, 指向出去的是子类
一个类基本由三部分组成, 第一部分是类名; 第二部分是由成员变量组成, 前面加上减号表示; 第三部分是成员函数, 由加号前面表示
继承之间的关系可以用 is a kind of 来表示
5 类的聚合
类的聚合是指多个类共同组成了一个大类
具体有两个例子
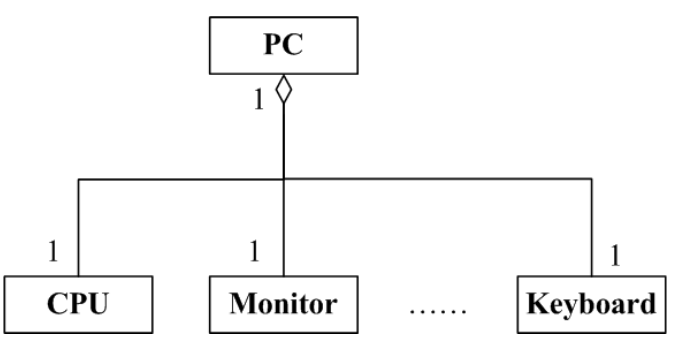
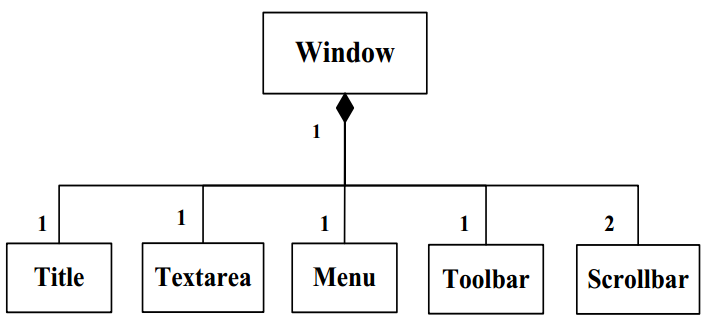
其中空心菱形表示脱离聚合的大类, 原有组成的小类可以继续存在
实心菱形表示, 脱离了聚合的大类之后, 原有组成的小类将不可继续存在
6 类的关联和多重性
类的关联关系是, 两个类之间, 既不是继承也不是聚合也不是组合关系, 两者之间可以通过一个动作来关联, 共同构成了主动宾关系
如学生上课, 顾客下订单

如果有多个动作关系, 那应该都列举出来, 例如借书的人与书之间的关系有借书, 还书, 续借, 预约

具体在代码中的表现就是, 类中包含其他类的对象
在描述类之间的关系的时候, 还需要考虑多重性
也就是一对多, 多对一,多对多等之间的关系, 具体可以查看多重性指示器

7 多态与动态绑定
在运行中, 正确的方法被激活, 这就是动态绑定
方法可以被不同的类的对象调用, 这也就是多态
8 面向对象泛型
抽象数据类型的优势: 信息隐藏, 数据抽象, 过程抽象
结构化泛型当程序超过50000行之后, 变暴露出问题了
此时使用面向对象泛型更为合适
面向对象泛型主要是基于 将数据和操作绑定到一起; 或者说形成对象, 利用对象来绑定操作
9 UML
UML 统一建模语言
UML定义了多种图, 各种图的相互之间的关系如下

用例图
类图: 分为简单类图和复杂类图(实体类,边界类等详细类图)
活动图
状态图
顺序图: 说明每个用例的具体实现过程
协作图
常见的UML工具
visio; rational rose; magicdraw; argouml等