使用数据传输DTS可以实现两个RDS实例间的数据迁移。对于支持增量迁移的存储引擎,还可以使用DTS在源RDS实例不停服的情况下,将数据迁移到目标RDS实例。目前对于RDS不同存储引擎,只支持同构迁移(例如RDS For MySQL迁移到RDS For MySQL),不支持异构迁移(例如RDS For MySQL迁移到RDS For SQLServer)。
本小节简单介绍使用DTS进行两个RDS实例之间的数据迁移的任务配置流程。
迁移权限要求
当使用DTS进行两个RDS实例间的数据迁移时,不同迁移类型,对源跟目标数据库的迁移帐号权限要求如下表:
| 迁移类型 | 结构迁移 | 全量迁移 | 增量迁移 |
|---|---|---|---|
| 源RDS实例 | 读写权限 | 读写权限 | 读写权限 |
| 目的MySQL | 读写权限 | 读写权限 | 读写权限 |
迁移任务配置
下面详细介绍下用户如何使用DTS实现两个RDS MySQL实例间的数据迁移。源RDS跟目标RDS实例可以不同也可以相同,即用户可以使用DTS实现一个RDS实例内部的数据迁移。
RDS实例数据库创建
在数据迁移过程中,如果待迁移的数据库在目标RDS实例中不存在,那么DTS自动会创建。但是对于如下两种情况,用户需要在配置迁移任务之前,手动创建数据库。
- 数据库名称不符合:RDS定义规范(由小写字母、数字、下划线、中划线组成,字母开头,字母或数字结尾,最长64个字符)。
- 待迁移数据库,在本地PostgreSQL跟目标RDS For PostgreSQL实例中存储名称不同。
对于这两种情况,用户需要在配置迁移任务之前,先在RDS控制台完成数据库创建。具体参考RDS数据库创建流程。
迁移帐号创建
迁移任务配置时,需要提供源RDS实例及目的RDS实例的迁移账号。迁移账号的相关权限详见上面的 迁移权限要求 一节。如果尚未创建迁移账号,那么可以参考 RDS实例账号创建需要先在源及目的RDS实例中创建迁移帐号,并将要迁移的库表的读写权限授权给上面创建的帐号。在RDS控制台中创建帐号,并将迁移库的读写权限授权给这个帐号。
迁移任务配置
当上面的所有前置条件都配置完成后,就可以开始正式的数据迁移了。下面详细介绍迁移任务配置流程。
- 进入数据传输DTS控制台,点击右上角的创建迁移任务,开始迁移任务配置。
-
源及目的实例连接信息配置。
这个步骤主要配置 迁移任务名称,源RDS连接信息及目标RDS实例连接信息。其中:
-
任务名称
DTS为每个任务自动生成一个任务名称,任务名称没有唯一性要求。您可以根据需要修改任务名称,建议为任务配置具有业务意义的名称,便于后续的任务识别。
-
源实例信息
- 实例类型:选择 RDS实例
- RDS实例ID: 配置迁移的源RDS实例的实例ID。DTS支持经典网络、VPC网络的RDS实例
- 数据库名称: 如果RDS实例的存储引擎为PostgreSQL或PPAS, 那么需要配置数据库名称。这个数据库名称为连接RDS实例使用的默认数据库
- 数据库账号:连接RDS实例的账号
- 数据库密码:上面数据账号对应的密码
-
目标实例信息
- 实例类型:选择 RDS实例
- RDS实例ID: 配置迁移的目标RDS实例的实例ID。 DTS支持经典网络、VPC网络的RDS实例
- 数据库名称:如果RDS实例的存储引擎为PostgreSQL或PPAS, 那么需要配置数据库名称。这个数据库名称为连接RDS实例使用的默认数据库
- 数据库账号:连接RDS实例的账号
- 数据库密码:上面数据账号对应的密码
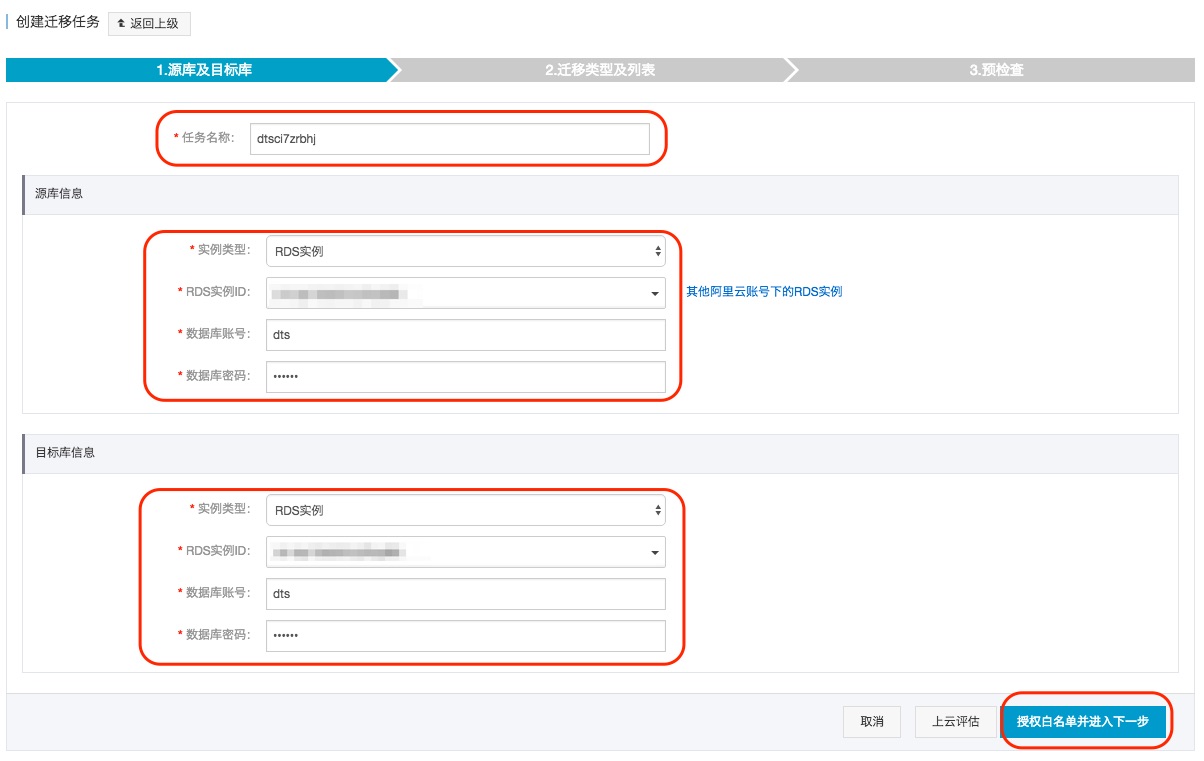
当配置完连接信息后,点击右下角 授权白名单并进入下一步 进行白名单授权。这个步骤DTS会将DTS服务器的IP地址添加到目标RDS实例的白名单中,避免因为RDS实例设置了白名单,导致DTS服务器连接不上RDS实例导致迁移失败。
-
-
选择迁移对象及迁移类型。
-
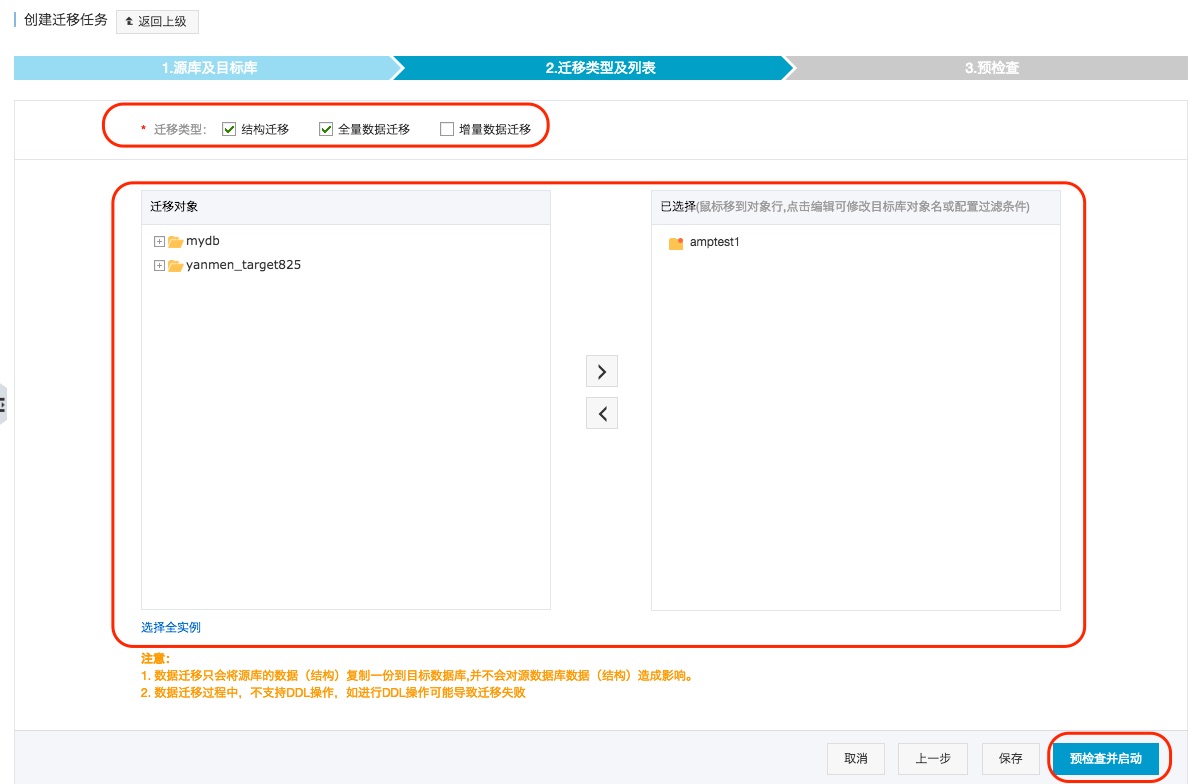
迁移类型
DTS迁移类型支持结构迁移、全量数据迁移及增量迁移。
如果只需要进行全量迁移,那么迁移类型选择:结构迁移+全量数据迁移。
如果需要进行不停机迁移,那么迁移类型选择:结构迁移+全量数据迁移+增量数据迁移。
-
迁移对象
这个步骤选择要迁移的对象。迁移对象的选择粒度细化为:库、表、列三个粒度。默认情况下,对象迁移到目标RDS实例后,对象名跟源RDS实例一致。如果您迁移的对象在源实例跟目标实例上名称不同,那么需要使用DTS提供的对象名映射功能,详细使用方式可以参考库表列映射。
-
-
预检查。
在迁移任务正式启动之前,会先进行前置预检查,只有预检查通过后,才能成功启动迁移。
如果预检查失败,那么可以点击具体检查项后的按钮,查看具体的失败详情,并根据失败原因修复后,重新进行预检查。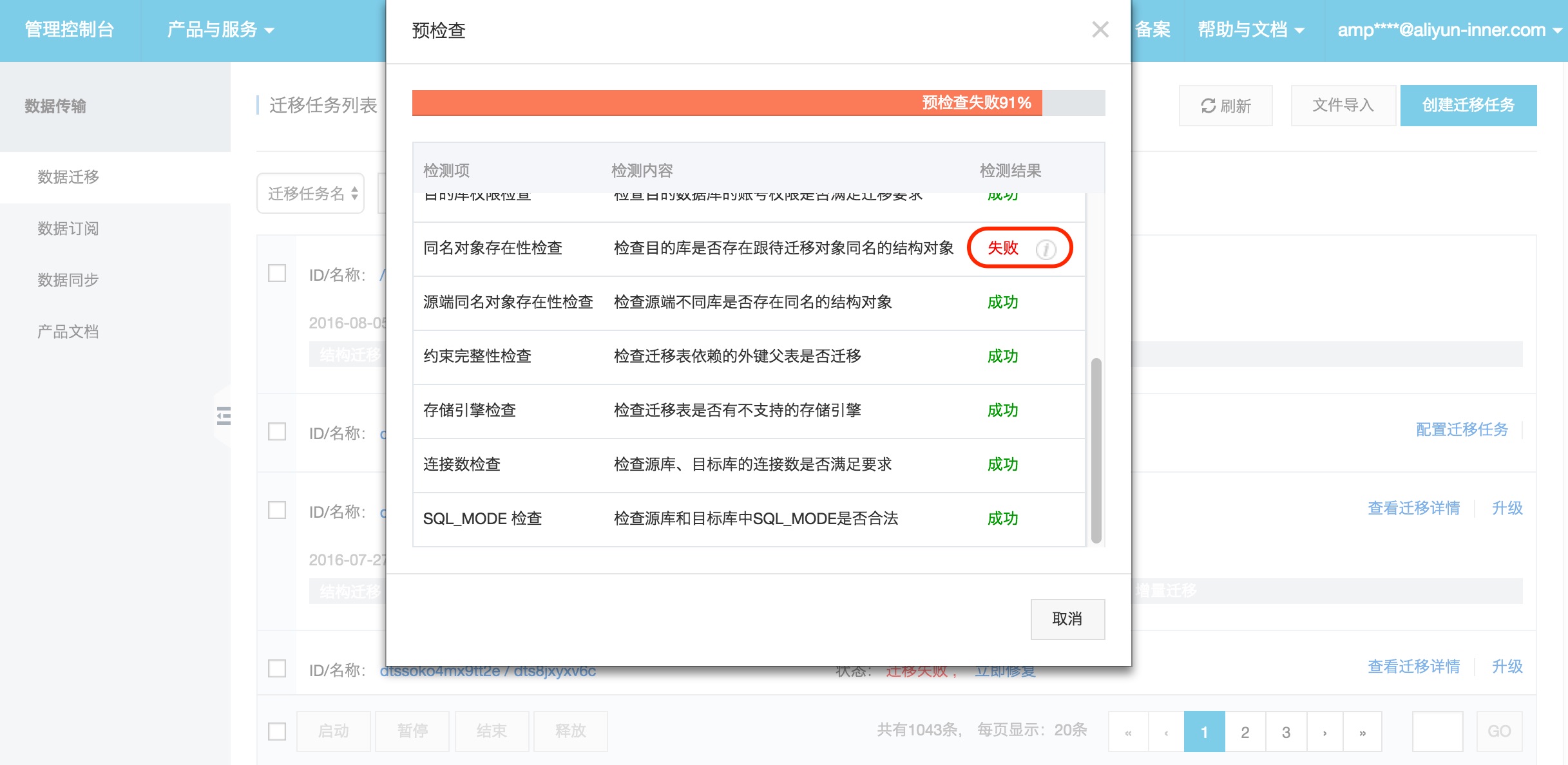
-
迁移任务。
当预检查通过后,可以启动迁移任务,任务启动成功后,可以在任务列表中查看迁移的具体状态及迁移进度。
如果选择了增量迁移,那么进入增量迁移阶段后,源库的更新写入都会被DTS同步到目标RDS实例。迁移任务不会自动结束。如果用户只是为了迁移,那么建议在增量迁移无延迟的状态时,源库停写几分钟,等待增量迁移再次进入无延迟状态后,停止掉迁移任务,直接将业务切换到目标RDS实例上即可。
至此,完成两个RDS实例的数据迁移任务配置。
实际过程:


