常用的引擎是:Innodb和Myiasm这两种引擎:
innodb:
提供了对事务的ACID操作,还提供了行级锁和外键约束,,他的优势就是处理大量数据,在msql启动的时候,首先会建立一个缓存池,主要是缓存数据和索引,但是操作大规模的数据查找时很慢,所以建议当需要数据库的事务操作时,使用这个,还有就是在写的时候不会锁定全表,所以在大规模并发操作的时候会提高效率;
Myiasm:
这个是默认的引擎,不提供事务和行级锁和外键约束,当在insert和update时会锁定全表,所以在执行写操作对的时候效率会很慢,
和innodb不同的是,myiasm保留了行数,所以在执行select count(*) from 的时候会很快,不需要扫描全表,当我们执行的读操作多于写操作的时候,并且不需要事务的支持,我们可以使用myisam这个引擎。
这两种引擎的数据结构都是B+树
存储的不同:
mysisam树节点存储得是数据的地址,指向实际的数据;
innodb树节点存储得是实际的数据;这种索引也被称为聚集索引
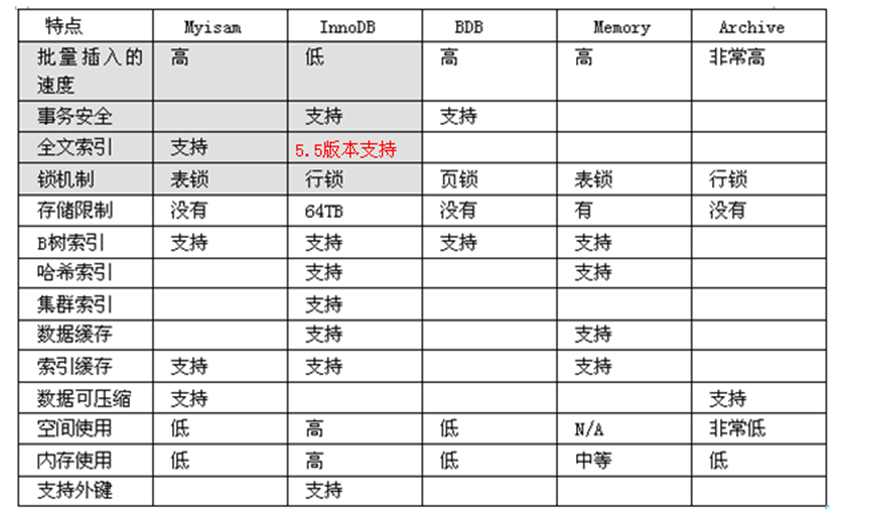
常见的引擎
InnoDB MyISAM Memory/Heap BDB Merge Example CSV MaxDB Archive
MyISAM:Mysql 5.0之前的默认数据库引擎,最为常用。拥有较高的插入,查询速度,但不支持事务
InnoDB:事务型速记的首选引擎,支持ACID事务,支持行级锁定,MySQL5.5成为默认数据库引擎
BDB:源自Berkeley DB,事务型数据库的另一种选择,支持Commit和Rollback等其他事务特效
Memory: 所有数据置于内存的存储引擎,拥有极高的插入,更新和查询效率。但是会占用和数据量成正比的内存空间。并且其内容会在MYSQL重新启动是会丢失。
Merge:将一定数量的 MyISAM 表联合而成一个整体,在超大规模数据存储时很有用
Archive :非常适合存储大量的独立的,作为历史记录的数据。因为它们不经常被读取。Archive 拥有高效的插入速度,但其对查询的支持相对较差
Federated :将不同的 MySQL 服务器联合起来,逻辑上组成一个完整的数据库。非常适合分布式应用
Cluster/NDB :高冗余的存储引擎,用多台数据机器联合提供服务以提高整体性能和安全性。适合数据量大,安全和性能要求高的应用
CSV :逻辑上由逗号分割数据的存储引擎。它会在数据库子目录里为每个数据表创建一个 .csv 文件。这是一种普通文本文件,每个数据行占用一个文本行。CSV 存储引擎不支持索引。
BlackHole: 黑洞引擎,写入的任何数据都会消失,一般用于记录 binlog 做复制的中继
EXAMPLE :存储引擎是一个不做任何事情的存根引擎。它的目的是作为 MySQL 源代码中的一个例子,用来演示如何开始编写一个新存储引擎。同样,它的主要兴趣是对开发者。EXAMPLE: 存储引擎不支持编索引。
另外,MySQL 的存储引擎接口定义良好。可以通过阅读文档编写自己的存储引擎。
MyISAM引擎特点
1、不支持事务(事务是指逻辑上的一组操作,组成这组操作的各个单元,要么全成功,要么全失败)
2、表级锁定(数据更新时锁整个表):其锁定机制是表级锁定,这虽然可以让锁定的实现成本很小但是也同时大大降低了其并发性能。
3、读写互相阻塞:不仅会在写入的时候阻塞读取,MyISAM还会在读取的时候阻塞写入,但读本身并不会阻塞另外的读。
4、只会缓存索引:MyISAM可以通过key_buffer_size缓存索引,以大大提高访问性能减少磁盘io,但是这个缓存区只会缓存索引,而不会缓存数据。
5、读取速度较快,占用资源相对少
6、不支持外键约束,但支持全文索引
7、MyISAM引擎是mysql5.5.5前缺省的存储引擎
MyISAM引擎适用的生产环境
1、不需要事务支持的业务(例如转账就不行,充值付款)
2、一般为读数据比较多的应用,读写都频繁场景不合适,读多或者写少的都合适。
3、读写并发访问相对较低的业务(纯读纯写高并发也可以)(锁定机制问题)
4、数据修改相对较少的业务(阻塞问题)。
5、以读为主的业务,例如:www,blog,图片信息数据库,用户数据库,商品库等业务
6、对数据一致性要求不是非常高的业务。
7、硬件资源比较差的机器可以用MyISAM。
单一对数据库的操作都可以使用MyISAM,所谓单一就是尽量纯读,或纯写(insert,update,delete)等。
MyISAM引擎调优
1、设置合适的索引(缓存机制)
2、调整读写优先级,根据实际需求确保重要操作更优先执行。
3、启用延迟插入改善大批量写入性能(降低写入频率,尽可能多条数据一次性写入)
4、尽量顺序操作让insert数据都写入到尾部,减少阻塞。
5、分解大的时间长的操作,降低单个操作的阻塞时间。
6、降低并发数(减少对mysql访问),某些高并发场景通过应用进行排队队列机制Q队列
7、对于相对静态(更改不频繁)的数据库数据,充分利用Query Cache或memcached缓存服务可以极大的提高访问效率。
grep query my.cnf
query_cache_size = 2M
query_cache_limit = 1M
query_cache_min_res_unit = 2k
8、MyISAM的count只有在全表扫描的时候特别高效,带有其他条件的count都需要进行实际的数据访问
select count(*) from oldboy.zizeng;
9、可以把主从同步的主库使用innodb,从库使用myisam引擎(但是在为了主从切换的时候还是要用innodb,所以这个不现实。)
InnoDB引擎特点
1、支持事务:支持4个事务隔离级别,支持多版本读。
2、行级锁定(更新时一般是锁定当前行):通过索引实现,全表扫描仍然会是表锁,注意间隙锁的影响。
3、读写阻塞与事务隔离级别相关。
4、具有非常高效的缓存特性:能缓存索引,也能缓存数据。
5、整个表和主键以cluster方式存储,组成一颗平衡树。
6、所有secondary index都会保存主键信息。
7、支持分区,表空间,类似oracle数据库。
8、支持外键约束,5.5以前不支持全文索引,以后支持了。
9、和Myisam引擎相比,innodb对硬件资源要求比较高。
innodb引擎适用的生产环境
1、根据事务支持的业务(具有较好的事务特性)
2、行级锁定对高并发有很好的适应能力,但需要确保查询是通过索引完成的。
3、数据读写及更新都较为频繁的场景,如:BBS,SNS,微博,微信等。
4、数据一致性要求较高的业务,例如:充值转账,银行卡转账。
5、硬件设备内存较大,可以利用innodb较好的缓存能力来提高内存利用率,尽可能减少磁盘io。
共享表空间对应物理数据文件
独立表空间对应物理数据文件
6、相比myisam,innodb更消耗资源,速度没有myisam快
innodb引擎的调优
1、主键要尽可能小,避免给secondary index带来过大的空间负担。
2、避免全表扫描,因为会使用表锁
3、尽可能缓存所有的索引和数据,提高响应速度,减少磁盘io消耗。
4、在大批量小插入的时候,尽量自己控制事务而不要使用autocommit自动提交,有开关可以控制提交方式。
5、合理设置innodb_flush_log_at_trx_commit参数值,不要过度追求安全性。
如果innodb_flush_log_at_trx_commit的值为0,log buffer 每秒就会被刷写日志文件到磁盘,提交事务的时候不做任何操作。
6、避免主键更新,因为这会带来大量的数据移动。
更改引擎
alter table oldboy engine = INNODB;
alter table oldboy engine = MyISAM;