Stream应用:
继续举例来操练Stream,对于下面这两个集合:

需求是:将这两个集合组合起来,形成对各自人员打招呼的结果,输出的结果如:
"Hi zhangsan"、"Hi lisi"、"Hi wangwu"、"Hi zhangliu";
"Hello zhangsan"、"Hello lisi"、"Hello wangwu"、"Hello zhangliu";
"你好 zhangsan"、"你好 lisi"、"你好 wangwu"、"你好 zhangliu";
那如何实现呢?其思路应该是:首先从list1中取出1个元素,然后再跟list2集合中的每个元素进行拼接操作,而list1对应一个stream,list2也对应一个stream,等于要操作两个Stream,那肯定得要用到flatMap()将其打平成一个Stream嘛,下面具体来实现一下:
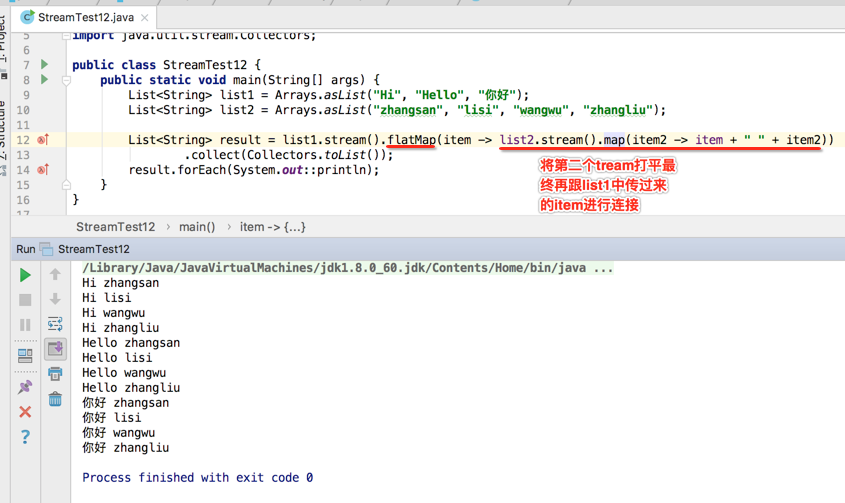
好好体会一下flatMap()的用法。
Stream分组:
之前【http://www.cnblogs.com/webor2006/p/8302401.html】也提到过Stream跟咱们数据库中的Sql很类似,都是属于描述性的语言,其中对于sql语句中可以用group by对数据进行分组,而在Stream中也有分组的功能,所以接下来举例来使用一下,以从学生中进行分组为例,首先新建一个学生类:
public class Student { /* 姓名 */ private String name; /* 分数 */ private int score; /* 年龄 */ private int age; public Student(String name, int score, int age) { this.name = name; this.score = score; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getScore() { return score; } public void setScore(int score) { this.score = score; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }
接下来构造学生集合:

接下来按姓名进行分组,对于sql语句而言比较简单,如下语句就可以达到要求:
select * from student group by name;
而对于这个需求如果采用传统的作法应该是按如下步骤进行:
1、循环列表;
2、取出学生的名字;
3、本地会一个Map<String, List<Student>>的本地map进行数据存放,然后每次遍历元素时会检测map中是否存在该名字,不存在则直接添加到map中;存在则将map中的List对象取出来,然后将该Student对象添加到该List当中;
4、返回该map对象。
可见传统方式是何等的麻烦,下面采用函数式的方式来实现,看下是何等的简单:
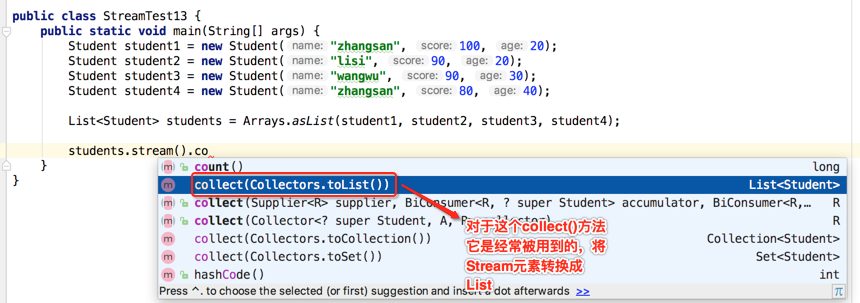
而这次分组就得再次用到这个Collectors,它是一个辅助类,之前还使用过求最大值,最小值之类的,那这次分组得用哪个方法呢?

可以看到在它里面有三个重载跟分组相关的方法,其名字跟sql语句中的基本上差不多,这里会用到第一个重载方式,接收一个Function参数的,简单看一下方法的描述:
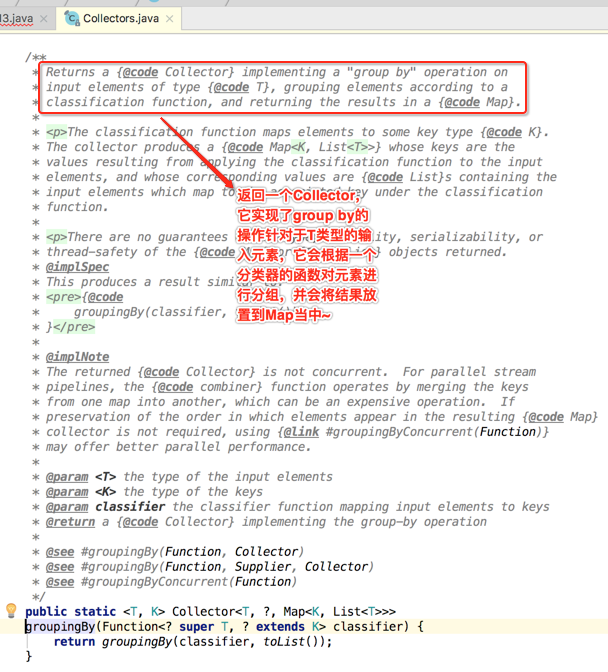
那具体怎么传参数呢?其实可以使用方法引用的方式来传,如下:
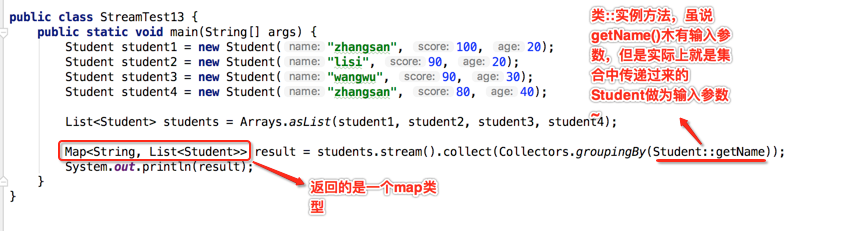
编译运行:
{lisi=[com.study.jdk8.stream.Student@b4c966a], zhangsan=[com.study.jdk8.stream.Student@2f4d3709, com.study.jdk8.stream.Student@4e50df2e], wangwu=[com.study.jdk8.stream.Student@1d81eb93]}
可见采用Stream方式实现分组是何等的简单。
接下来对分数进行分组,依葫芦画瓢呗:
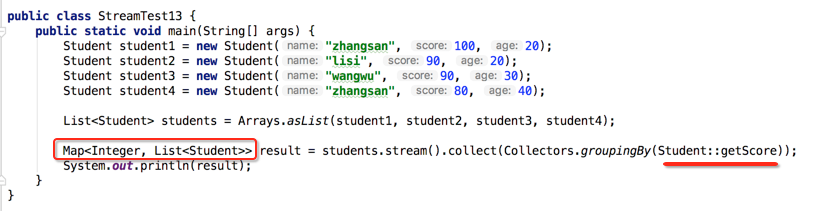
其输出:
{80=[com.study.jdk8.stream.Student@6e8cf4c6], 100=[com.study.jdk8.stream.Student@12edcd21], 90=[com.study.jdk8.stream.Student@34c45dca, com.study.jdk8.stream.Student@52cc8049]}
接下来现来更改需求,这时还是根据名字进行分组,但是输出变了,输出变成名字及它里面分组的个数了,其对应SQL语句类似于它:
select name, count(*) from student group by name;
那这时得用到另外一个重载的groupingby()方法啦,如下:

其方法原型定义如下:
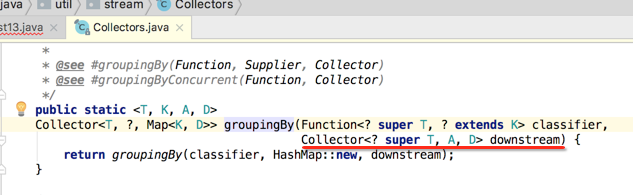
那具体怎么做呢?如下:

其中看一下counting()方法:
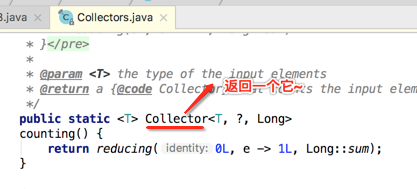
编译运行:

接下来需求进一步升级,这时以名字进行分组之后求一下各组学生成绩的平均值并打印出来,其思路跟上面求个数的类似,如下:

其中averagingDouble()方法看一眼:
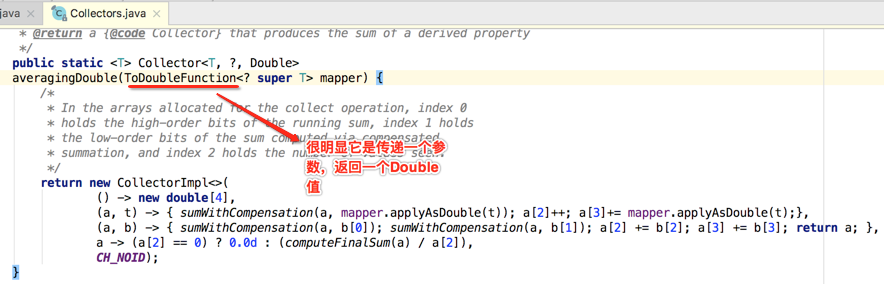
下面编译运行:

Stream分区:
对于分组可以称为"group by",那对于分区呢?可以叫"partition by",其实分区是分组的一种特例,其结果只有两组,怎么理解,比如:从学生集合中对90分及以上的以及90分以下的学生进行分区,就像考驾照上机操作时,90分及以上的为及格,而以下的则为不及格,这就是所谓的分区,那如何做呢?
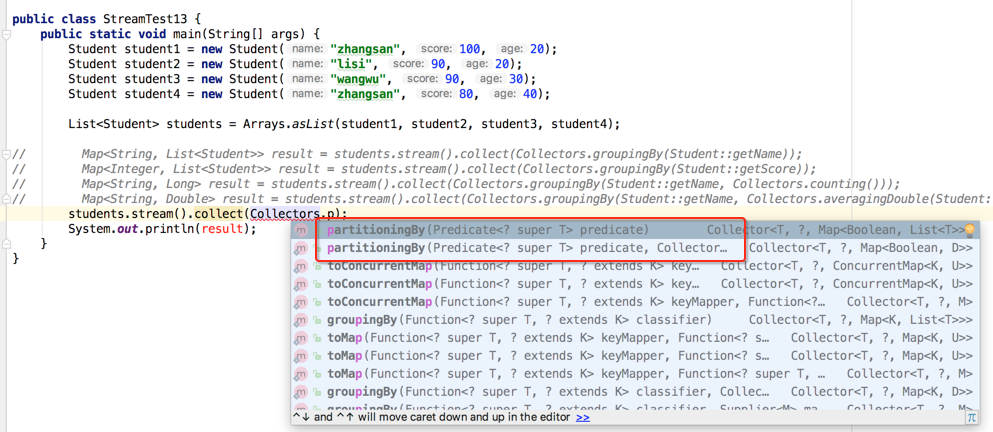
这次就不用groupingBy()方法了,而是采用partitioningBy()了,有两个方法重载,这里用第一个,如下:

编译运行:
{false=[com.study.jdk8.stream.Student@2f4d3709], true=[com.study.jdk8.stream.Student@4e50df2e, com.study.jdk8.stream.Student@1d81eb93, com.study.jdk8.stream.Student@7291c18f]}
是不是再一次体现出了Java8中的Stream是有多强大了,接下来还会不断进行探究,彻底去掌握它~