一、执行Spark任务: 客户端
1、Spark Submit工具:提交Spark的任务(jar文件)
(*)spark提供的用于提交Spark任务工具
(*)example:/root/training/spark-2.1.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.0.jar
(*)SparkPi.scala 例子:蒙特卡罗求PI
bin/spark-submit --master spark://bigdata11:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 100
Pi is roughly 3.1419547141954713
bin/spark-submit --master spark://bigdata11:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 300
Pi is roughly 3.141877971395932
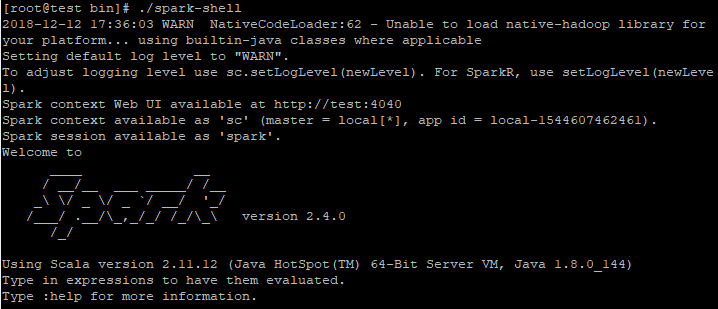
2、Spark Shell 工具:交互式命令行工具、作为一个Application运行
两种模式:(1)本地模式
在spark解压目录/bin下执行:./spark-shell
日志:
创建一个文件hellospark.txt
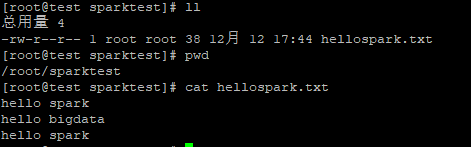
读文件:

(2)集群模式
bin/spark-shell --master spark://bigdata11:7077
日志:
Spark context available as 'sc' (master = spark://bigdata11:7077, app id = app-20180209210815-0002).
对象:Spark context available as 'sc'
Spark session available as 'spark' ---> 在Spark 2.0后,新提供
是一个统一的访问接口:Spark Core、Spark SQL、Spark Streaming
sc.textFile("hdfs://bigdata11:9000/input/data.txt") 通过sc对象读取HDFS的文件
.flatMap(_.split(" ")) 分词操作、压平
.map((_,1)) 每个单词记一次数
.reduceByKey(_+_) 按照key进行reduce,再将value进行累加
.saveAsTextFile("hdfs://bigdata11:9000/output/spark/day0209/wc")
多说一句:
.reduceByKey(_+_)
完整
.reduceByKey((a,b) => a+b)
3、开发WordCount程序
http://spark.apache.org/docs/2.1.0/api/scala/index.html#org.apache.spark.package
(1)Scala版本: 在IDEA中
package mydemo /* 提交 bin/spark-submit --master spark://bigdata11:7077 --class mydemo.MyWordCount /root/temp/MyWordCount.jar hdfs://bigdata11:9000/input/data.txt hdfs://bigdata11:9000/output/spark/day0209/wc1 */ import org.apache.spark.{SparkConf, SparkContext} //开发一个Scala版本的WordCount object MyWordCount { def main(args: Array[String]): Unit = { //创建一个Config val conf = new SparkConf().setAppName("MyScalaWordCount") //核心创建SparkContext对象 val sc = new SparkContext(conf) //使用sc对象执行相应的算子(函数) sc.textFile(args(0)) .flatMap(_.split(" ")) .map((_,1)) .reduceByKey(_+_) .saveAsTextFile(args(1)) //停止SparkContext对象 sc.stop() } }
分析WordCount程序执行的过程

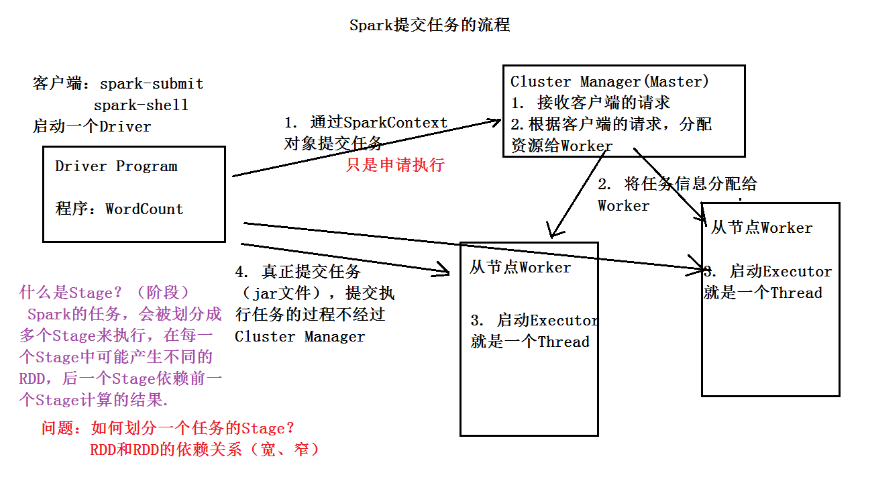
Spark 提交任务的流程