https://study.163.com/course/courseMain.htm?courseId=1006383008&share=2&shareId=400000000398149(博主录制)

https://www.cnblogs.com/gasongjian/p/8670925.html参考
reportgen v0.1.8 更新介绍
这段时间,我对 reportgen 进行了大工程量的修改和更新。将之前在各个文章中出现的函数进行了封装,同时也对现有工具包的一些逻辑进行了调整。
1、reportgen 简介
reportgen 的底层是 pptx 文件生成接口,它能非常方便的将DataFrame等数据导出为pptx上的图表。你可以自定义图表的类型(条形图、饼图、折线图等),也可以全部交给工具包来自动化。另外不排除后期会增加其他文件形式(如可交互的 html 等)接口的可能性,但短期内估计比较难。
在这些接口上是一些辅助函数,包括特征类型的判断、sklearn中缺少的预处理函数、一些特殊的度量函数、模型评估报告函数、关联分析函数等。工具包的愿景是对数据的自动分析,自动出报告,这期间缺乏的函数我都可能加进去。这次更新,主要就是完善了这一层。
工具包的最外层就是各类数据的分析报告生成。目前已经完成的是问卷型数据和通用性数据。其中问卷型数据已经很完善,基本只需要修bug了,单独作为一个子包放在 reportgen中,大家可以 import reportgen.questionnaire as ques 来使用。至于通用性数据,目前已经完成了第一步,即描述统计型的分析报告,大家可以用rpt.AnalysisReport 来实现。第二步准备实现给定目标变量后的分析,包含交叉分析、各特征的重要性、监督学习模型等。
另外,这次我放了一些案例在github上,用于大家下载后的测试和学习用,网址是 https://github.com/gasongjian/reportgen/tree/master/example
2、通用数据的分析
在这个分析报告中,我会对DataFrame数据的每一个字段进行分析,判断它们的类型,然后画出合适的图表。对于因子变量,自动绘制柱状图或条形图;对于数值型变量,自动绘制出拟合的分布图;对于一般的文本,自动绘制词云。同时也会给出一个统计表格,内含各个变量的场景统计数据,如最大值、最小值、均值、标准差、唯一数个数、缺失率等。下面是一个例子,代码和数据可在我的github中寻找。
import pandas as pd
import reportgen as rpt
# 数据导入
# 数据的网址:https://github.com/gasongjian/reportgen/tree/master/example/datasets/LendingClub_Sample.xlsx
data=pd.read_excel('.\datasets\LendingClub_Sample.xlsx')
# 数据预览
rpt.AnalysisReport(data.copy(),filename='LendingClub 数据预览');它会生成如下 pptx 文件

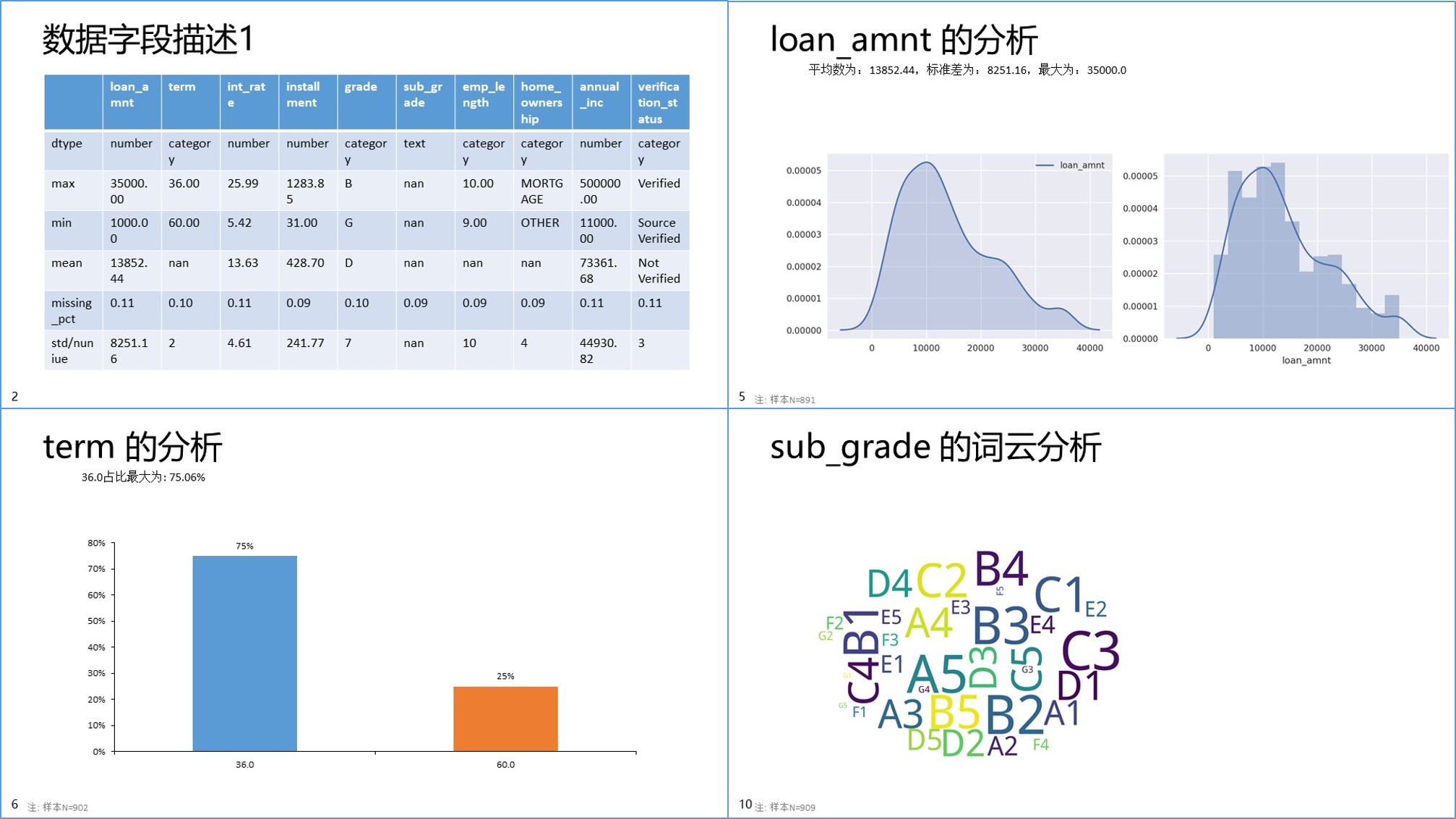
另外这里有一些过程函数也推荐给大家
特征统计分析
# 返回各个特征的数据类型
var_type=rpt.type_of_var(data)
#返回一个统计表格,内含数据各个特征的一些统计值
summary=rpt.describe(data)数据预处理
# 只作工具包测试,所以不区分训练集和测试集
y=data['target']
X=data.drop(['target'],axis=1)
categorical_var=list(set(X.columns[X.apply(pd.Series.nunique)<30])|set(X.select_dtypes(include=['O']).columns))
continuous_var=list(set(X.columns)-set(categorical_var))
# ===========【WOE 编码】=============
woe=rpt.preprocessing.WeightOfEvidence(categorical_features=categorical_var,encoder_na=False)
X=woe.fit_transform(X,y)
# ===========【离散:卡方分箱】=============
dis=rpt.preprocessing.Discretization(continous_features=continuous_var)
X2=dis.fit_transform(X,y)信息论相关度量函数
# 离散因子变量的熵
rpt.metrics.entropy.entropy(p)
# 连续数值变量的熵(基于k近邻算法的近似估计)
rpt.metrics.entropyc.kl_div(p,q)机器学习模型辅助建模函数
clfs={'LogisticRegression':LogisticRegressionCV(),
'RandomForest':RandomForestClassifier(),'GradientBoosting':GradientBoostingClassifier()}
y_preds,y_probas={},{}
for clf in clfs:
clfs[clf].fit(X, y)
y_preds[clf] =clfs[clf].predict(X)
y_probas[clf] = clfs[clf].predict_proba(X)[:,1]
# 函数会输出一个或多个二分类模型的性能评估结果,包含ROC曲线、PR曲线、密度函数、auc等统计指标、混淆矩阵等
models_report,conf_matrix=rpt.ClassifierReport(y,y_preds,y_probas)
print(models_report)3、问卷型数据分析
问卷数据涉及到各种题型,包括单选题、多选题、填空题、矩阵多选题、排序题等等。不管是
频数统计还是交叉分析,单选题都很好处理, 但其他题目就相对复杂的多,比如单选题和多选题
之间的交叉统计,多选题和多选题之间的交叉统计等。
为了能使用统一的函数进行常规分析,本工具包使用专门针对问卷设计的数据类型(或者说编码方式)。在这种类型中,每一份问卷都有两个文件,data 和 code ,它们的含义如下:
1). data:按选项序号编码的数据(csv、xlsx等都可以)。具体的示例如下:
| Q1 | Q2 | Q3_A1 | Q3_A2 | Q3_A3 | Q3_A4 |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 1 | 0 |
| 1 | 2 | 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 0 | 0 | 1 |
| 2 | 3 | 0 | 1 | 1 | 0 |
| 1 | 2 | 1 | 0 | 1 | 0 |
| 1 | 4 | 0 | 1 | 0 | 1 |
| 2 | 2 | 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 | 0 | 1 |
| 2 | 2 | 1 | 0 | 1 | 0 |
其中 Q1、Q2是单选题,在Q1中,1代表男,2代表女。Q3是多选题,一共有四个选项,分别代表 Q3_A1:'旅游',Q3_A2:'健身',Q3_A3:'艺术',Q3_A4:'养生'. 多选题常用这种01矩阵存储。
2). code:编码文件( json格式,就是 python中的字典类型), 给定每道题的题号、选项编码等信息。
每一个题目都有如下字段:
content: 题目内容code: 题目对应的编码code_r: 题目对应的编码(矩阵单选题专有)qtype: 题目类型,单选题、多选题、矩阵单选题、排序题、填空题等qlist: 该题的索引,如多选题的 ['Q1_A1','Q1_A2',..]code_order: 非必须,题目类别的顺序,用于PPT报告的生成[一般后期添加]name: 非必须,特殊题型的标注weight: 非必须,dict,每个选项的权重,用于如月收入等的平均数统计
具体示例如下:
code={'Q1':{
'content':'性别',
'code':{
1:'男',
2:'女'
}
'qtype':'单选题',
'qlist':['Q1']
},
'Q2':{
'content':'年龄',
'code':{
1:'17岁以下',
2:'18-25岁',
3:'26-35岁',
4:'36-46岁'
},
'qtype':'单选题',
'qlist':['Q2']
},
'Q3':{
'content':'爱好',
'code':{
'Q3_A1':'旅游',
'Q3_A2':'健身',
'Q3_A3':'艺术',
'Q3_A4':'养生'
},
'qtype':'多选题',
'qlist':['Q3_A1','Q3_A2','Q3_A3','Q3_A4']
}
}该工具包包含如下函数:
文件 IO
read_code, 从本地读取code数据,支持excel文件和json文件save_code, 将code 保存为 xlsx 或json数据load_data, 支持打开文件窗口来选择问卷数据read_data, 读取本地的数据,自适应xlsx、csv等save_data, 将问卷数据(data和code)保存到本地wenjuanwang, 编码问卷网平台的问卷数据,输入为问卷网上下载的三个文件wenjuanxing, 编码问卷星平台的问卷数据,输入为问卷星网站上下载的两个xls文件(按选项序号和按选项文本)
数据处理
spec_rcode: 对问卷中的一些特殊题型进行处理,如将城市题分类成省份、城市、城市级别等dataText_to_code:dataCode_to_text:var_combine: 见data_mergedata_merge: 合并两份问卷数据,常见于多个推动渠道的问卷合并clean_ftime: 根据用户填写时间来筛选问卷,会根据填问卷累计时间曲线的拐点来给出剔除的时间点data_auto_code:qdata_flatten: 将问卷数据展平,便于将多份问卷数据存储在同一个数据库中
统计检验等
sample_size_cal: 样本量计算公式confidence_interval: 置信区间计算公式gof_test: 拟合优度检验chi2_test: 卡方检验fisher_exact: 卡方检验,适用于观察频数过少的情形anova: 方差分析
数据分析
mca: 对应分析,目前只支持两个变量cluster: 态度题的聚类分析,会根据轮廓系数自动选择最佳类别数association_rules: 关联分析,用于多选题的进一步分析
统计
contingency: 列联表分析,统一给出列联表的各种数据,包含fo、fop、TGI等qtable: 单个题目的统计分析和两个题目的交叉分析,给出频数表和频率表
可视化
summary_chart: 整体统计报告,针对每一道题,选择合适的图表进行展示,并输出为pptx文件cross_chart: 交叉分析报告,如能将年龄与每一道题目进行交叉分析,并输出为pptx文件onekey_gen: 综合上两个,一键生成scorpion: 生成一个表格,内含每个题目的相关统计信息scatter: 散点图绘制,不同于matplotlib的是,其能给每个点加文字标签sankey: 桑基图绘制,不画图,只提供 R 需要的数据
python实践
import reportgen.questionnaire as ques
# 导入问卷星数据
datapath=['.\datasets\[问卷星数据]800_800_0.xls','.\datasets\[问卷星数据]800_800_2.xls']
data,code=ques.wenjuanxing(datapath)
# 导出
ques.save_data(data,filename='data.xlsx')
ques.save_data(data,filename='data.xlsx',code=code)# 会将选项编码替换成文本
ques.save_code(code,filename='code.xlsx')
# 对单变量进行统计分析
result=ques.qtable(data,code,'Q1')
print(result['fo'])
# 两个变量的交叉分析
result=ques.qtable(data,code,'Q1','Q2')
print(result['fop'])
# 聚类分析,会在原数据上添加一列,类别题
#ques.cluster(data,code,'态度题')
# 在.\out\下 生成 pptx文件
ques.summary_chart(data,code,filename='整体统计报告');
ques.cross_chart(data,code,cross_class='Q4',filename='交叉分析报告_年龄');
ques.scorpion(data,code,filename='详细分析数据')
ques.onekey_gen(data,code,filename='reportgen 自动生成报告');4、pptx 文件生成接口 Report
在 reportgen 中,一个分析报告被拆解成四个部分:title、summary、footnote和body data,
title: slide 的标题summary: slide的副标题或一些简要结论data: slide的可视化数据footnote: slide的脚注,如数据来源、样本量等说明
它们的位置见下图。其中body data 可以是一个或多个chart/表格/文本框/图片的组合。抛弃latex和pptx自带那种精细的排版,Report 只需你提供这四个部分的数据,剩下的排版你就不用管啦,函数会帮你来完成。
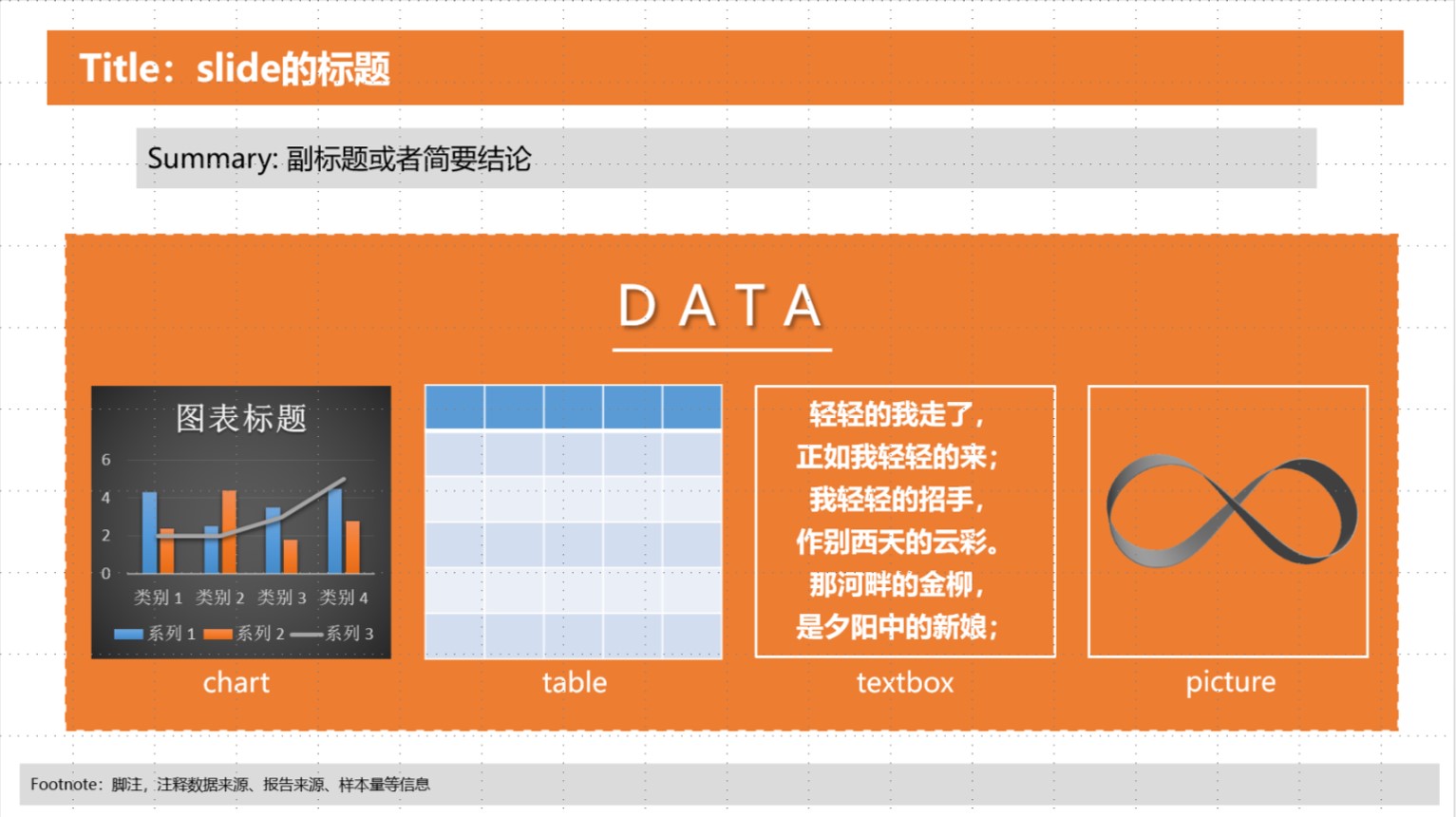
Report 是一个类,可以打开 pptx文件从中获取信息并新建 slide.
首先是初始化,
import reportgen as rpt
# 导入分析报告
prs=rpt.Report()
#prs = rpt.Report(filename='分析报告.pptx')函数默认会打开reportgen自带的模板文件(路径是 ~
eportgen emplate emplate.pptx), 大家也可以自己指定其他文件。
对于存在内容的 pptx,Report能轻松实现获取所有的文本和图片
#获取分析报告中所有的文本
prs.get_texts()
#获取分析报告中所有的图片
prs.get_images()同时你也能很简单的创建一页新的 slide
data=pd.DataFrame(np.random.randint(100,1000,size=(3,4)),index=['品牌A','品牌B','品牌C'],columns=['Q1','Q2','Q3','Q4'])
slide_data={'data':data,'slide_type':'chart','type':'COLUMN_CLUSTERED'}
prs.add_slide(data=slide_data,title='品牌销量',summary='品牌销量',footnote='')在上面的脚本中,我们添加了一张各品牌的销量分布图,图表类型是柱状图。
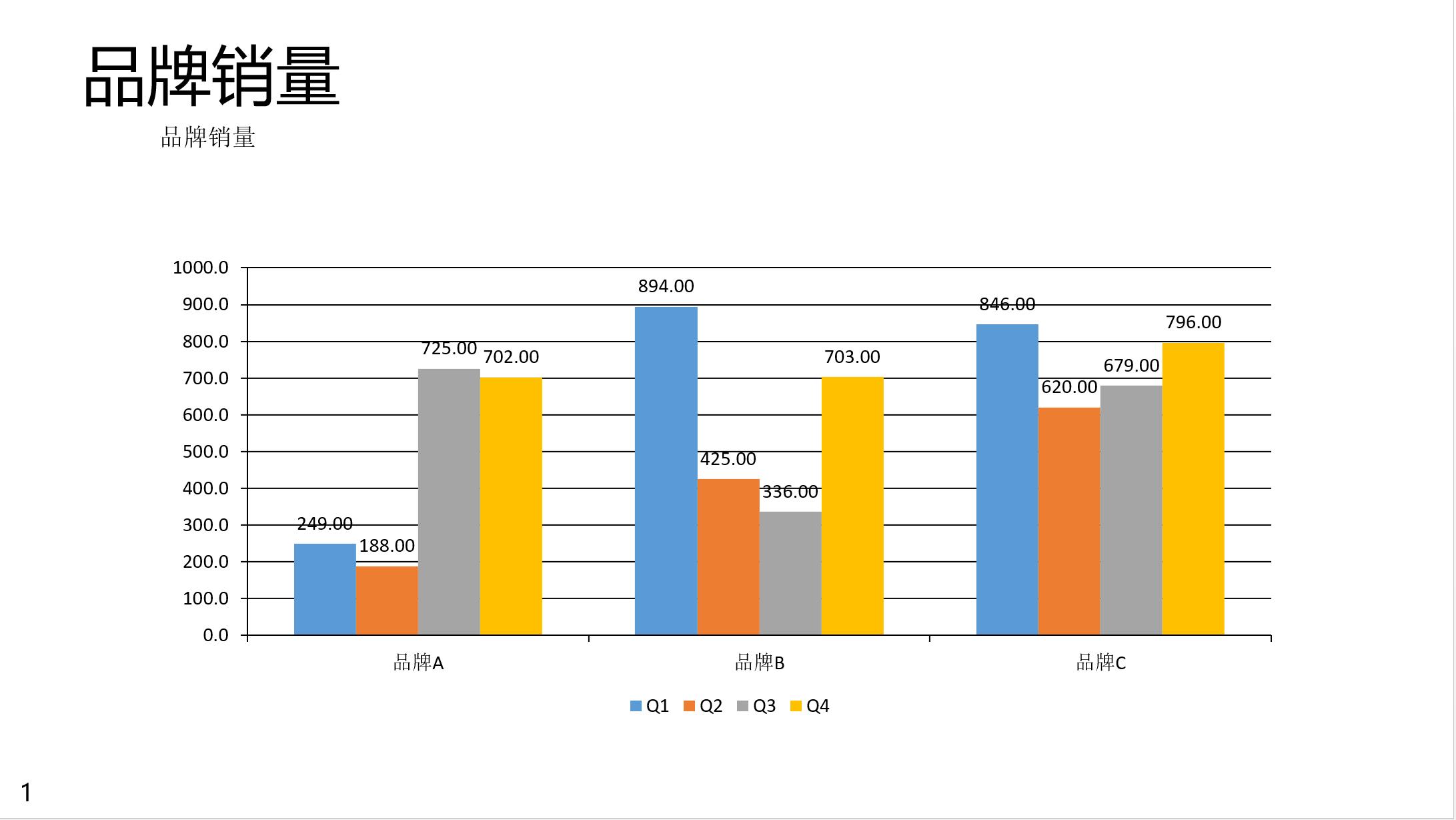
slide_type 目前支持的类型有四种:
- chart: office 软件自带的图表,详细的类型由 type 指定
- table: 表格,表格数据由 data 给定
- picture: 图片,图片的路径由 data 给定
- textbox: 文本框,文字内容由 data 给定
当slide_type是非 table 类型时,函数参数也可以直接给定 data ,如
prs.add_slide(data=data,title='品牌销量',summary='品牌销量')另外,如前文所介绍,一张slide可以添加多个图表:
slide_data1={'data':data,'slide_type':'chart','type':'COLUMN_CLUSTERED'}
slide_data2={'data':data,'slide_type':'table'}
slide_data3={'data':'测试
测试','slide_type':'textbox'}
prs.add_slide(data=[slide_data1,slide_data2,slide_data3],title='品牌销量',summary='品牌销量')当所有slide都建好了后,用 prs.save(filename='text.pptx') 保存就可以
另外Report还提供了两个有用的函数:
prs.add_cover(): 利用三角剖分算法提供了一种很极客的封面版式,详细可参见上面第二节的图片prs.add_slides(): 根据一组数据,给分析报告快速添加一系列的slides.
最后说下reportgen的安装方法,很简单,工具包已经上传到pypi上了,直接 pip install reportgen 即可,当然也可以到作者的github官网上下载使用 https://github.com/gasongjian/reportgen
