sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程)

QQ:231469242
欢迎喜欢nltk朋友交流
https://www.pythonprogramming.net/text-classification-nltk-tutorial/?completed=/wordnet-nltk-tutorial/
Text Classification with NLTK
Now that we're comfortable with NLTK, let's try to tackle text classification. The goal with text classification can be pretty broad. Maybe we're trying to classify text as about politics or the military. Maybe we're trying to classify it by the gender of the author who wrote it. A fairly popular text classification task is to identify a body of text as either spam or not spam, for things like email filters. In our case, we're going to try to create a sentiment analysis algorithm.
To do this, we're going to start by trying to use the movie reviews database that is part of the NLTK corpus. From there we'll try to use words as "features" which are a part of either a positive or negative movie review. The NLTK corpus movie_reviews data set has the reviews, and they are labeled already as positive or negative. This means we can train and test with this data. First, let's wrangle our data.
import nltk
import random
from nltk.corpus import movie_reviews
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
print(documents[1])
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
print(all_words.most_common(15))
print(all_words["stupid"])
It may take a moment to run this script, as the movie reviews dataset is somewhat large. Let's cover what is happening here.
After importing the data set we want, you see:
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
Basically, in plain English, the above code is translated to: In each category (we have pos or neg), take all of the file IDs (each review has its own ID), then store the word_tokenized version (a list of words) for the file ID, followed by the positive or negative label in one big list.
Next, we use random to shuffle our documents. This is because we're going to be training and testing. If we left them in order, chances are we'd train on all of the negatives, some positives, and then test only against positives. We don't want that, so we shuffle the data.
Then, just so you can see the data you are working with, we print out documents[1], which is a big list, where the first element is a list the words, and the 2nd element is the "pos" or "neg" label.
Next, we want to collect all words that we find, so we can have a massive list of typical words. From here, we can perform a frequency distribution, to then find out the most common words. As you will see, the most popular "words" are actually things like punctuation, "the," "a" and so on, but quickly we get to legitimate words. We intend to store a few thousand of the most popular words, so this shouldn't be a problem.
print(all_words.most_common(15))
The above gives you the 15 most common words. You can also find out how many occurences a word has by doing:
print(all_words["stupid"])
Next up, we'll begin storing our words as features of either positive or negative movie reviews.
导入corpus语料库的movie_reviews 影评
all_words 是所有电影影评的所有文字,一共有150多万字
#all_words 是所有电影影评的所有文字,一共有150多万字
all_words=movie_reviews.words()
'''
all_words Out[37]: ['plot', ':', 'two', 'teen', 'couples', 'go', 'to', ...] len(all_words) Out[38]: 1583820
'''
影评的分类category只有两种,neg负面,pos正面
import nltk
import random
from nltk.corpus import movie_reviews
for category in movie_reviews.categories():
print(category)
'''
neg
pos
'''
列出关于neg负面的文件ID
movie_reviews.fileids("neg")
'''
'neg/cv502_10970.txt',
'neg/cv503_11196.txt',
'neg/cv504_29120.txt',
'neg/cv505_12926.txt',
'neg/cv506_17521.txt',
'neg/cv507_9509.txt',
'neg/cv508_17742.txt',
'neg/cv509_17354.txt',
'neg/cv510_24758.txt',
'neg/cv511_10360.txt',
'neg/cv512_17618.txt'
.......
'''
列出关于pos正面的文件ID
movie_reviews.fileids("pos")
'pos/cv989_15824.txt',
'pos/cv990_11591.txt',
'pos/cv991_18645.txt',
'pos/cv992_11962.txt',
'pos/cv993_29737.txt',
'pos/cv994_12270.txt',
'pos/cv995_21821.txt',
'pos/cv996_11592.txt',
'pos/cv997_5046.txt',
'pos/cv998_14111.txt',
'pos/cv999_13106.txt'
输出neg/cv987_7394.txt 的文字,一共有872个
list_words=movie_reviews.words("neg/cv987_7394.txt")
'''
['please', 'don', "'", 't', 'mind', 'this', 'windbag', ...]
'''
len(list_words)
'''
Out[30]: 872
'''
tuple1=(list(movie_reviews.words("neg/cv987_7394.txt")), 'neg')
'''
Out[32]: (['please', 'don', "'", 't', 'mind', 'this', 'windbag', ...], 'neg')
'''
#用列表解析最终比较方便
#展示形式多条(['please', 'don', "'", 't', 'mind', 'this', 'windbag', ...], 'neg')
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
一共有2000个文件
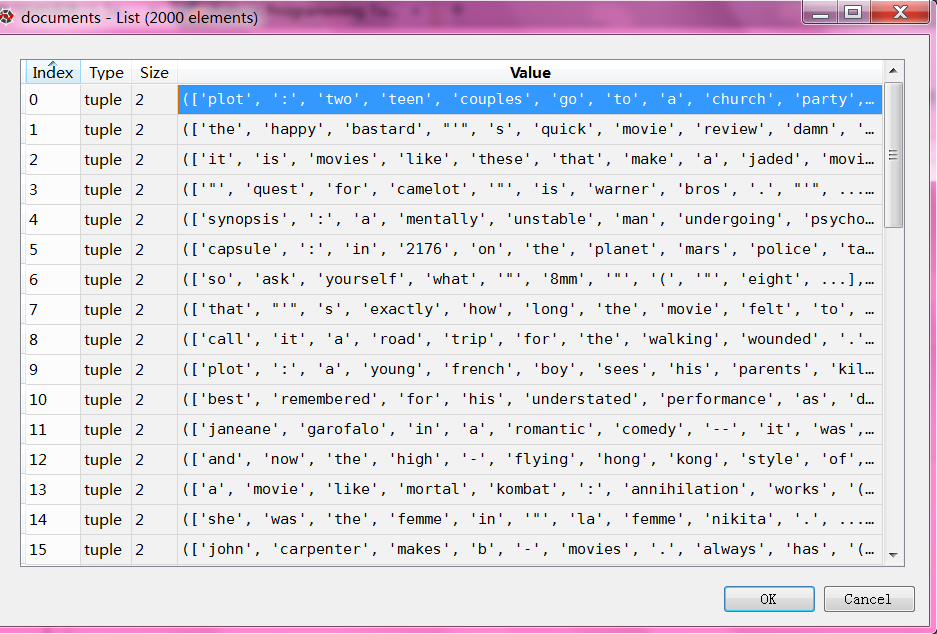
每个文件由一窜单词和评论neg/pos组成
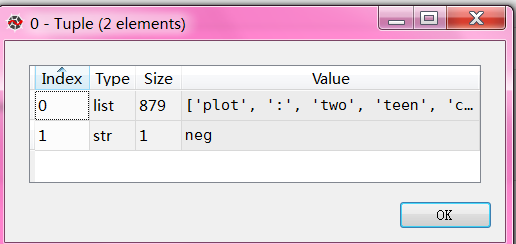
完整测试代码
# -*- coding: utf-8 -*-
"""
Created on Sun Dec 4 09:27:48 2016
@author: daxiong
"""
import nltk
import random
from nltk.corpus import movie_reviews
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
#print(documents[1])
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
#print(all_words.most_common(15))
print(all_words["stupid"])
