1.安装Eclipse
1》下载Eclipse
可以以多种方式下载Eclipse,下面介绍直接从eplise官网下载和从中国镜像站点下载,下载把eclipse上传到Hadoop环境中。
第一种方式从elipse官网下载:
http://www.eclipse.org/downloads/?osType=linux
我们运行的环境为CentOS 64位系统,需要选择eclipse类型为linux,然后点击linux 64bit链接下载
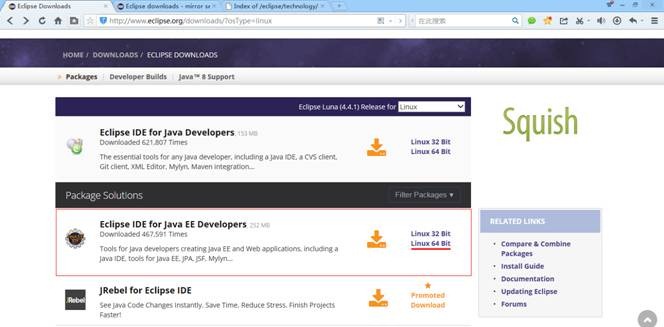
会根据用户所在地,推荐最佳的下载地址
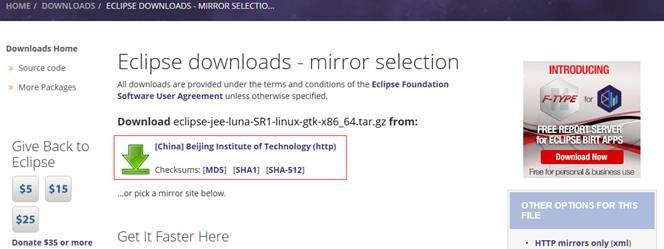
在该页面的下部分也可以根据自己的情况选择合适的镜像站点进行下载

第二种方式从镜像站点直接下载elipse:
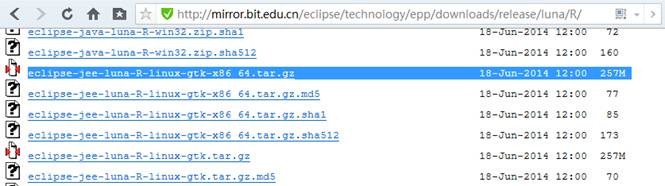
http://mirror.bit.edu.cn/eclipse/technology/epp/downloads/release/luna/R/
在镜像站点选择 eclipse-jee-luna-R-linux-gtk-x86_64.tar.gz进行下载
(http://mirror.bit.edu.cn/eclipse/technology/epp/downloads/release/luna/R/eclipse-jee-luna-R-linux-gtk-x86_64.tar.gz)
2》解压elipse
在/home/hadoop/Downloads/目录中,使用如下命令解压elipse并移动到/usr/local目录下:
cd /home/hadoop/Downloads
tar -zxvf eclipse-jee-luna-SR1-linux-gtk-x86_64.tar.gz
sudo mv eclipse /usr/local/
cd /usr/local
ls


3》启动eclipse
登录到虚拟机桌面,进入/usr/local/eclipse目录,通过如下命令启动eclipse:
cd /usr/local/eclipse
./eclipse
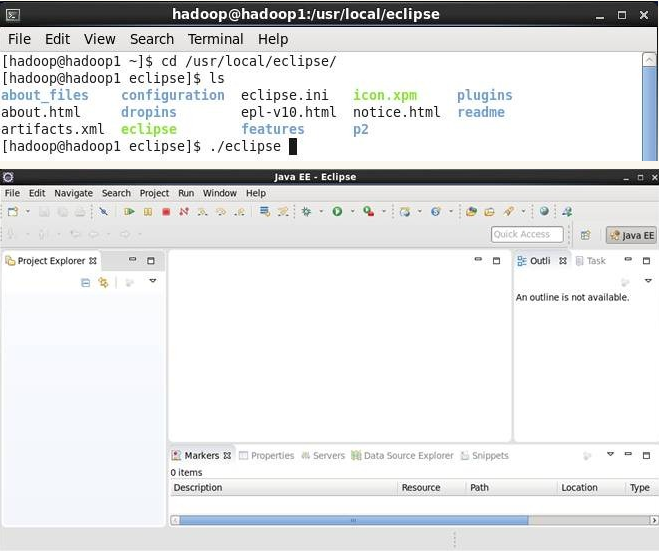
为了方便操作,可以在虚拟机的桌面上建立elipse的快捷操作
2.在Eclipse中安装hadoop插件
Hadoop2.7.1插件下载:http://download.csdn.net/download/gaoyunbo007/9973198
1、将下载好的插件移动到eclipse安装目录下的plugins文件夹下。
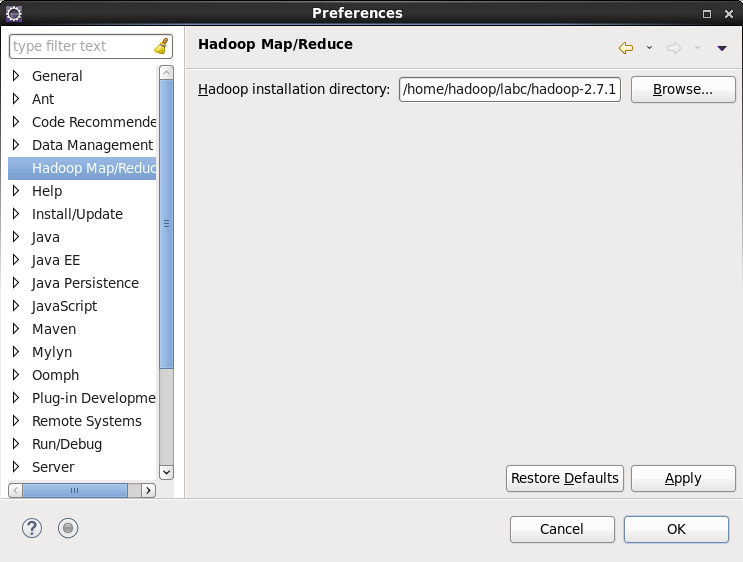
2、重新启动eclispe,配置hadoop安装目录和hdfs端口。
如果插件安装成功,打开【Windows】—>【Preferences】后,在窗口左侧会有Hadoop Map/Reduce选项,点击此选项,在窗口右侧设置hadoop安装路径,然后点击【OK】。
打开【Windows】–>【Perspective】–>【Open perspective】–>【Other】,选择【Map/Reduce】,点击【OK】。

点击【Map/Reduce Location】选项卡,点击右边小象图标,打开Hadoop Location配置窗口:
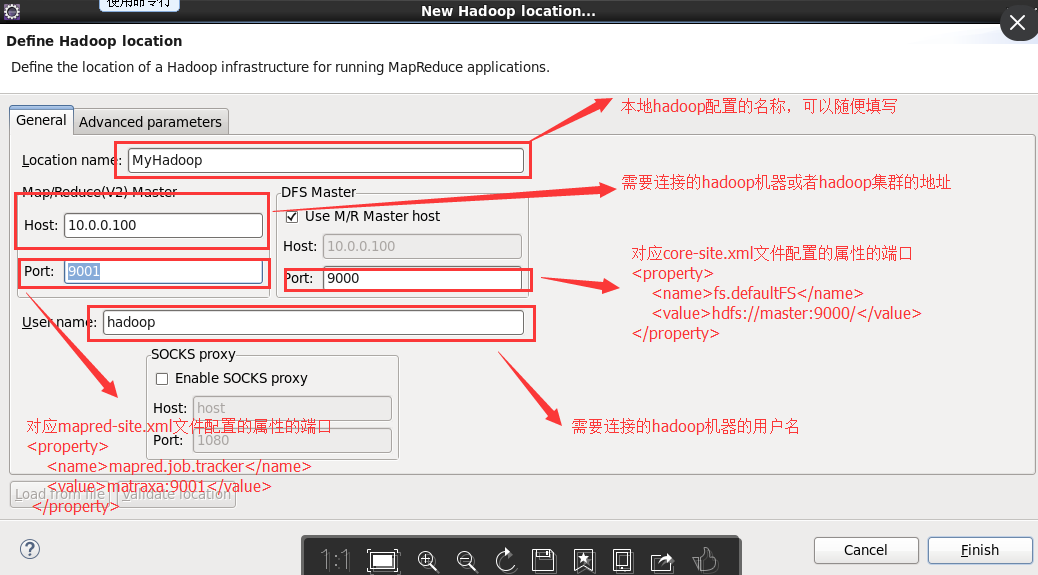
输入Location Name,任意名称即可。配置Map/Reduce Master,Host和Port配置成与mapred-site.xml的设置一致和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致,点击【Finish】。
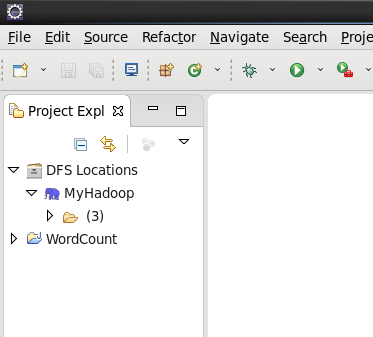
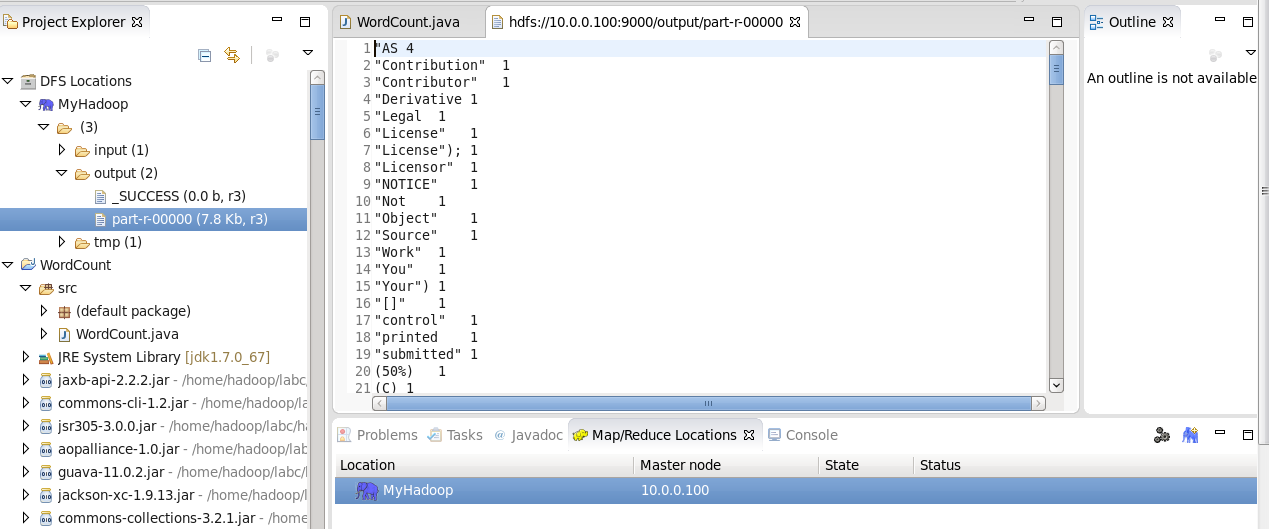
点击左侧的DFSLocations—>MyHadoop(上一步配置的location name),如果不报错,表示安装成功。
注意:这里和Hadoop1.x不一样,1.x版本这里会有user文件夹,2.x以后没有,如果你是新装的hadoop,这里显示的文件数为0,此时并不是报错。
3.测试插件是否配置成功
新建WordCount项目
1、点击【File】—>【Project】,选择【Map/Reduce Project】,输入项目名称WordCount,一直回车。
在WordCount项目里新建class,名称为WordCount,代码如下:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}2、在HDFS上创建目录input
hadoop fs -mkdir /input
3、拷贝本地README.txt到HDFS的input里
hadoop fs -copyFromLocal /home/hadoop/labc/hadoop/README.txt /input
4、点击WordCount.java,右键,点击【Run As】—>【Run Configurations】,配置运行参数,即输入和输出文件夹
hdfs://Master:9000/input hdfs://Master:9000/output
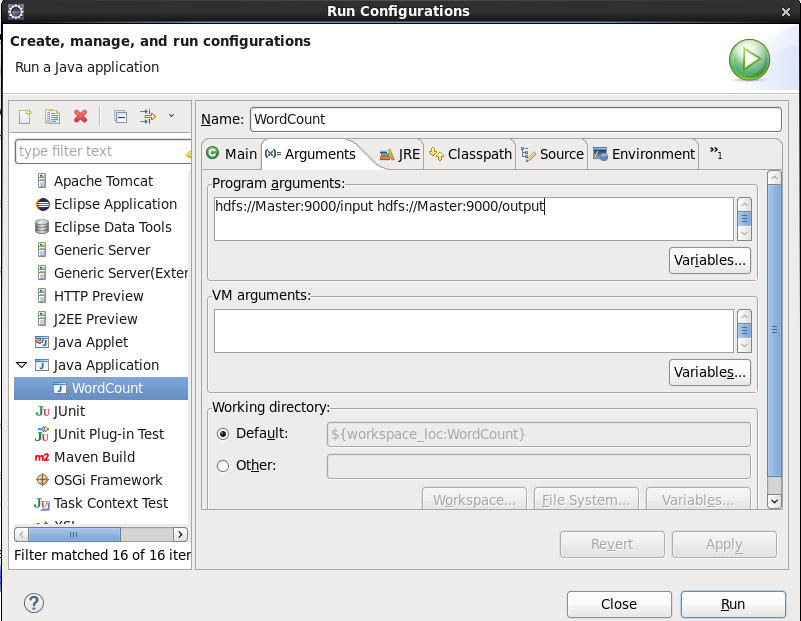
5、点击【Run】,运行程序。
查看运行结果:
1> 在控制台输入:
hadoop fs -cat /output/part-r-00000
2>展开【DFS Locations】