1、调优的意义
在大数据分析计算领域,Spark已经成为主流的,非常受欢迎的计算引擎之一。Spark的功能涵盖了大数据领域的批处理、类SQL处理、实时计算、机器学习、图计算等多种不同类型的计算操作,应用范围广泛、前景一片大好,今天许多公司作为主流计算引擎使用,大多数Spark使用者,最初都是想提高计算性能而选择使用Spark作为计算引擎的,可见Spark足以使大数据作业执行速度更快,性能得到惊人的提高。然而,通过Spark开发出高性能的大数据作业并不是那么简单的事情,如果没有对Spark进行合理的调优,Spark作业的执行速度很可能受到制约,这样就完全体现不出Spark作为一种快速的大数据计算引擎的优势。因此,想要用好Spark,就不需要其进行合理的调优。
Spark性能调优实际上由多部份组成,不是调节几个参数就能立竿见影。我们需要根据具体的业务场景、数据规模以及集群环境对Spark进行综合性的分析,然后进行多个方面的调节,才能获得综合最佳效果。这里我通过学习Spark的知识,以及在工作中的总结分析,总结出了一些关于Spark作业的优化方案。整套方案分为开发调优,资源调优,数据倾斜调优,shuffle调优几个部分。并发和资源调优是所有Spark作业都要注意和遵循的一些基本元组,是高性能Spark作业的基础;数据倾斜调优,主要讲述了一套完整的用来解决如恶对Spark作业的shuule运行过程以及细节进行调优。
今天介绍下Spark性能优化基础篇,主要讲解开发调优和资源调优。
2、开发调优
Spark 性能优化的第一步,就是在开发Spark作业的时候注意和应用一些性能优化的基本元组。开发调优,就是让大家了解Spark基本开发原则,包括 RDD lineage设计,算子合理使用,特殊操作优化等。在开发过程中,时刻应该注意以上原则,并将这些原则根据不同的业务应用场景,灵活的使用这些规则帮助改善Spark作业的运行效率。
2.1、原则1 避免创建重复的RDD
通常来讲,我们在开发一个Spark作业的时候,首先是基于某个数据源创建一个初始的RDD,接着对这个RDD进行某种算子操作,然后得到下一个RDD,以此类推,循环往复,指导计算出最终我们想要的结果,在这个过程中,多个RDD会通过不同的算子操作串起来,这个RDD串就是 RDD lineage,也就是平时说的RDD血缘关系。我们在开发过程中要注意,对同一份数据之创建一个RDD,不要对一份数据创建多个RDD。一些Spark新手在刚开始开发Spark作业时,可能会完了自己已经对谋一份数据创建了一个RDD,从而导致对于同一份RDD创建了多个RDD,这就意味着,我们的Spark作业进行多次重复的计算来创建多个代表相同数据的RDD,进而增加了作业的性能开销。
例子
/**
* 需要对 名为 t.txt 的文件进行一次 map 操作,在进行一次 reduce 操作,也就是说对一个文件进行两次操作,
* 错误的做法;对同一份数据进行多次算子操作,创建多个RDD
* 这里执行了 两次 textFile 方法,针对同一个文件,创建两个RDD,然后分别执行了对应的操作
* 这种请情况下,Spark需要从文件系统加载两次文件,并创建两个RDD,第二次加载文件创建RDD的开销实属浪费
*/
val rdd1: RDD[String] = sc.textFile("data/1.txt")
rdd1.map(...)
val rdd2: RDD[String] = sc.textFile("data/1.txt")
rdd2.reduce(...)
/**
* 正确的做法:对于一份数据执行多次操作的时候,只创建一个RDD
* 这种做法明显比上一种好多了,因为我们对于同一份数据只创建了一个RDD,然后对这个RDD进行两次算子操作
* 注意这里到此优化并没有结束,由rdd1被执行了两次算子操作,第二次执行reduce操作的时候,还是会再次从源头重新计算一次rdd1 的数据,还是由重复加载数据的开销的
* 要想彻底解决这个问题,需要结合原则三,对多次使用的RDD进行缓存,才能保证多次调用的RDD只计算一次
*/
val rdd1: RDD[String] = sc.textFile("data/1.txt")
rdd1.map(...)
rdd1.reduce(...)
2.2、原则2 尽可能复用同一个RDD
除了避免在开发过程中对同一份数据创建多个RDD之外,在对不同的数据执行算子操作时尽可能的复用一个RDD。比如说,有一个RDD的数据时key-value类型的,另一个数据时单 value 类型,这两个RDD的 value数据完全一样,那么我们可以使用key-value类型的RDD,因为其中已经包含了另一个RDD的数据,对于类似的这种RDD的数据有重叠或者包含的情况,我们应该尽量复用一个RDD,这样尽可能减少RDD的数量,从而减少算子执行的次数,
/**
* 错误做法
* rdd1 是一个<Long,String> 格式的RDD
* 接着由于业务需要,对 rdd1 执行一次 map 操作,创建了一个 rdd2,而rdd2 中的数据仅是 rdd1的 value 而已,也就是说,rdd2 是 rdd1 的子集
*/
val rdd1: RDD[(Long,String)] = ...
val rdd2: RDD[String] = ...
//对 rdd1 rdd2进行不同的操作
rdd1.map(...)
rdd2.filter(...)
/**
* 正确做法
* rdd1 & rdd2 无非就是格式不同而已,rdd2完全是rdd1的子集,却创建了rdd2,然后各自进行操作
* 其实这种情况可以复用rdd1,我们可以使用 rdd1 进行一次操作,在执行第二次操作的时候直接使用 rdd1 的 value 部分即可
* */
rdd1.map(...)
rdd1.filter(_.2...)
2.3、原则3 对多次使用的RDD进行持久化
当在Spark代码中对同一个RDD进行多次算子操作时,那么你已经学会了优化原则的第一步了,也就是说复用RDD,此时就在此基础上进行二次优化,也就是说要保证对一个RDD进行多次操作时,这个RDD本身仅计算一次。Spark对于一个RDD执行多次算子操作的原理是这样的;每次对一个RDD进行一次算子操作时,都会重新从源头处计算一遍那个RDD来,然后在对这个RDD进行算子操作,这种方式很影响作业效率。因此对于这种情况,我建议:对于多次使用的RDD进行持久化。此时Spark会根据你的持久化策略,将RDD的数据保存到内存或磁盘中,以后每次对RDD进行操作时,会从持久化的数据中读取RDD数据,。然后执行算子,而不是冲源头重新计算一遍RDD,再执行算子。
/**
* 如果要对RDD进行持久化,只要调用对这个RDD调用 cache() Huo persist() 方法
* 正确做法
* cache() 使用非序列化方式将RDD持久化到内存中,,此时再对RDD进行两次算子操作时,只有在第一次执行map() 算子时,才会对rdd 从源头处计算一次
* 第二次执行算子时,就会直接从内存中提取数据进行计算,不会重复计算一个rdd
*/
val rdd1: RDD[String] = sc.textFile("data/1.txt").cache()
rdd1.map(...)
rdd1.reduce(...)
/**
* persist() 方法表示 手动选择持久化级别,并使用指定的方式进行持久化
* 比如说,StorageLevel.MEMORY_AND_DISK_SER表示,内存充足时优先持久化到内存中,内存不充足时持久化到磁盘文件中。
* 而且其中的_SER后缀表示,使用序列化的方式来保存RDD数据,此时RDD中的每个partition都会序列化成一个大的字节数组,然后再持久化到内存或磁盘中。
* 序列化的方式可以减少持久化的数据对内存/磁盘的占用量,进而避免内存被持久化数据占用过多,从而发生频繁GC。
*/
val rdd2: RDD[String] = sc.textFile("data/1.txt").persist(StorageLevel.MEMORY_AND_DISK_SER)
rdd2.map(...)
rdd2.reduce(...)
对于persist()方法而言,可以根据不同的业务场景选择不同的持久化级别。
Spark 持久化级别
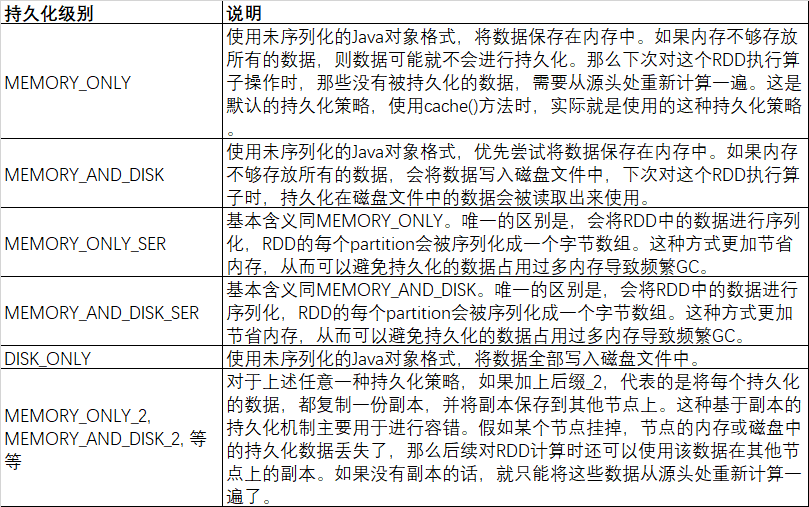
持久化级别怎么选择;
1、默认情况下,性能最高的当然时 MEMORY_ONLY,但是前提内存必须足够大,可以绰绰有余存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避免了这部分性能开销,对这个RDD的后续算子操作,都是基于内存中的数据操作的,不需要从磁盘文件中读取数据,性能也很高 ,而且不需要复制一份副本,并远程传送到其它节点,当时必须要注意,在实际生产环境,恐怕能够直接使用这种测类的场景还是非常有限的,如果RDD的数据比较大,使用这种方式进行持久化,会导致OOM。
2、如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议使用MEMORY_ONLY_SER,这种级别会将RDD数据序列化后在进行持久化到内存中,此时每个分区仅仅是一个字节数组,大大减少了对象数量,并降低了内存占用,这种级别比MEMORY_ONOLY 多出来的内存开销,主要就是序列化与反序列化的开销,当时后算子可以基于纯内存进行操作,因此性能总体来说比较高,此外,可能发生的事情也是OOM。
3、如果村内存的级别无法使用,那么建议使用MEMORY_AND_DISK_SRE ,而不是 MEMORY_AND_DISK策略,因为既然到了这一步,说明RDD数据非常大,内存放不下了,序列化后的数据比较少,可以节省内存*磁盘的空间开销,同时该策略会优先尝试将数据持久化到内存中,内存放不下才会持久化到磁盘。
3、通常不建议使用DISK_ONLY 和后缀为_2 的持久化级别,因为完全基于磁盘的数据读写,会导致性能急剧降低,有时候还不如重新计算一次所有的RDD。后缀为_2 的级别,必须将所有数据都复制一份,并发送到其它几点进行备份,数据复制以及会导致网络IO的较大开销,除非是要求作业的极高可靠性,否则不建议使用。
2.4、原则4 尽量避免使用shuffle类算子
如果有可能的话,尽量避免使用shuffle类算子,在Spark作业运行中,最消耗资源的就是shuffle 过程,shuffle 过程简单来说就是将分布在集群中的多个节点上的同一个key,拉取到一个节点上,比如reduceBykey 和 join 都是会触发shuffle 操作。shuffle 过程中,每个节点上的相同key都会先写入本地磁盘文件,然后其它节点需要通过网络传输拉取各个节点上的磁盘文件中相同key ,而且相同key都拉取到相同的一个节点进行聚合曹祖时,还有可能因为key 分布不均,导致某节点上处理的key较多,导致内存不不够存放,进而溢写到磁盘文件中,因此shuffle过程中,可能会发生大量的磁盘文件读写和IO操作,以及数据的网络IO ,磁盘和网络IO也是shuffle性能较差的主要原因。因此在开发Spark中,能避免使用 reduceBykey,join,distinct,repartition 等会进行shuffle的算子,尽量使用map类非shuffle算子,这样的话,没有shuffle或者只有少量的shuffle 算子的spark作业,可以大大减少性能开销。
/**
* 传统 join 会导致 shuffle,因为两个RDD中,相同的key都需要通过网络拉取到一个节点上,由一个task进行join 操作
*/
val rdd3 = rdd1.join(rdd2)
//此时使用 broadcast + map 不会导致shuffle
var rdd2Data=rdd2.collect()
val rdd2DataBroadcast = sc.broadcast(rdd2Data)
var rdd3= rdd1.map(rdd2DataBroadcast....)
//注意使用广播变量,建议仅仅在 rdd2 数据量较少的场景下使用,<2G ,因为每个 Executor 的内存。都会驻留一份 rdd2 的全量数据
2.5、原则5 使用map-side预聚合的shuffle操作
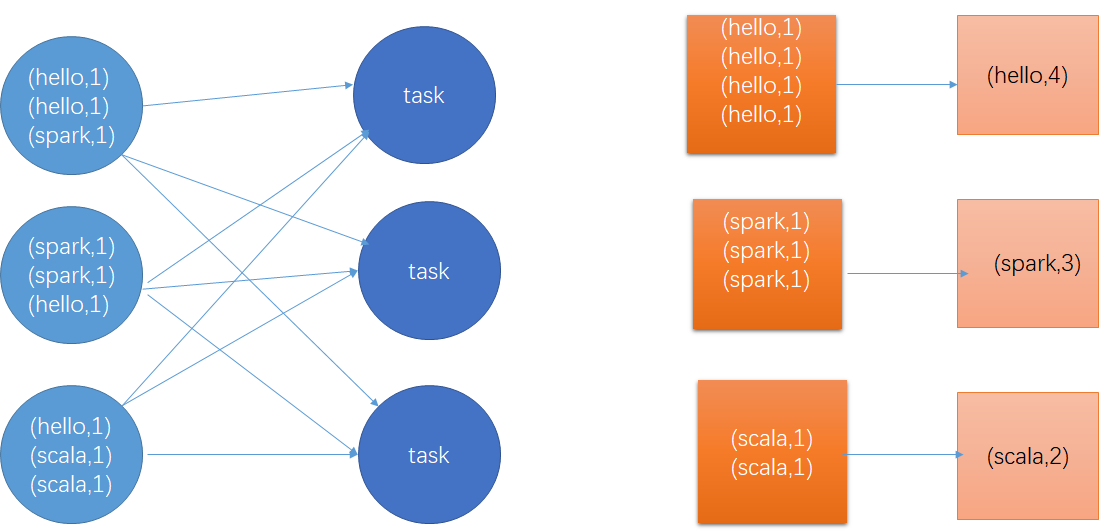
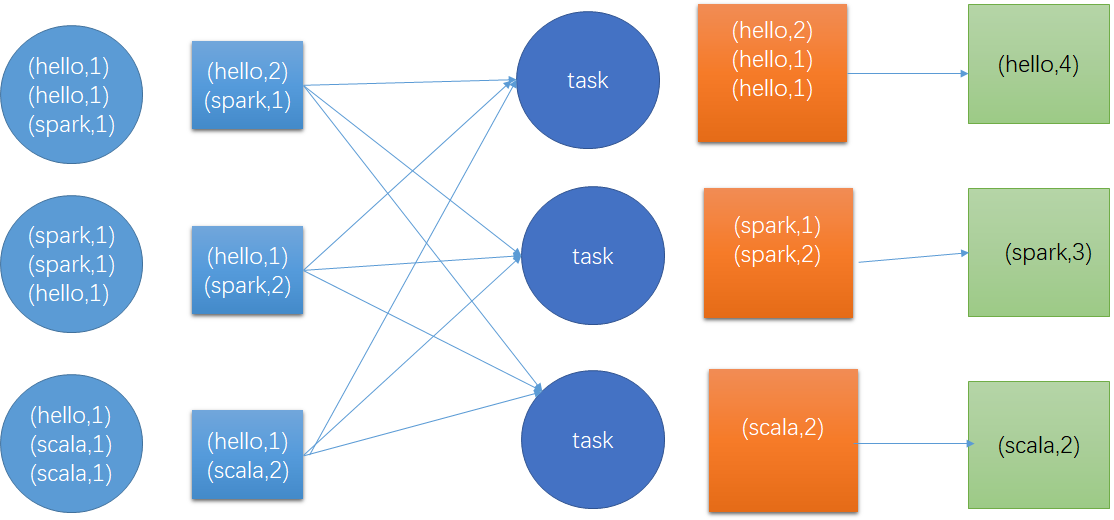
如果因为业务场景需要一定需要shuffle操作,无法使用map类算子迭代,那么尽量使用map-suide预聚合类算子。map-side预聚合指的是每个节点本地相同key进行一次聚合操作,类似于MR的本地combiner,map-side预聚合之后,每个节点本地只有一条相同的key,因为多条相同key被聚合起来了,其它节点在拉取所有节点相同key的数据时,就会大大减少所需拉取的数据量,从而减少磁盘/网络 IO,通常来说,在可能的情况下,建议使用reducebykey/aggrebykey算子来替代groupByKey,因为groupByKey算子不会进行预聚合,全量数据会在集群各个节点之间进行分发传输,性能相对较差。比如下,下面两个图,分别基于reducebykey和groupByKey 进行wordcount,其中第一个图是 groupByKey的执行逻辑,可以看到,没有进行仁和==任何本地预聚合,所有数据都在集群之间传输,第二张图是reducebykey,可以看到,每个节点本地进行相同key的预聚合操作,然后才传输到其它节点上进行全局聚合。
2.6、原则6 使用高性能算子
2.6.1、使用 reduceByKey/aggregateByKey 替代 groupByKey
详见原则5
2.6.2、使用 mapPartition 替代 map
mapPartition类算子,一次函数调用会处理整个partition内部所有数据,而不是像map那样只处理一条数据,性能上相对高出一些,但是有的时候,使用mapPartition会出现OOM,因为单词函数调用就处理整个分区的数据,如果内存不足,垃圾回收时无法回收太多的对象,很可能发生OOM异常,所以使用mapPartitio时要注意当前RDD数据大侠以及当前集群内存情况。
2.6.3、使用 foreachPartition 替代 foreach
原理类似于 “使用mapPartiti 代替 map”,也是一次函数调用处理整个partition的所有数据,而不是一次函数调用处理一条数据。在工作中,foreachPartition 类的算子,对性能提升很有帮助,比如在foreach 函数中,将RDD的所有数据写入MYSQL,那么如果是普通的foreach算子,就会一条数据一条数据的写入,每次函数调用可能会创建一个数据库链接,此时势必频繁的创建和消费数据库链接,性能是非常低的。但是使用foreachPartition算子一次处理一个分区的数据,那么对于每个partition,只要创建一个数据库链接就行了,然后执行数据批量写入,此时性能是比较高的。对于1W条左右数据量写入MySQL ,使用foreachP和使用foreach,性能有30%的提升。
2.6.4、使用 filter 之后在进行 coalesce
通常对一个RDD执行filter算子过滤掉RDD中较多的数据后,比如需要过滤掉三分之一的数据,建议使用coalesce算子,手动减少RDD的partition数量,将RDD中数据压缩到更少的partitio中,因为filter之后,RDD的每个partition中都会有很多数据被过滤掉,此时如果照常进行后续的计算。其实每个task处理的partition中的数据并不是很多,有一点资源浪费,而且此时处理的task越多,速度越慢,因此coalesce减少partition的数量,将RDD中的数据压缩到更少的partition之后,只要使用更少的task即可处理完所有的partition,在某些场景下,对于性能提升是有帮助的。
2.6.5、使用 repartitionAndSortWithinPartition 代替 repartition与sort
repartitionAndWithinPartition是Spark官网推荐的一个算子,官方建议,如果要在repartition重分区之后,还需要进行排序,建议直接使用repartitionAndSortWithinPartition算子。因为该算子可以一边进行重分区shuffle操作,一边进行进行排序,shuffle和sort操作同时进行。比先shuffle在sort来说,性能有很大提升。
2.7、合理使用广播变量
在平时工作中,会遇到在算子函数中用到外部变量的场景(尤其是大变量,100M~2G的集合或其他数据),那么此时就应该使用Spark的广播变量(Brocast)来提升性能。在算子中使用外部变量时,默认情况下,Spark会将该变量复制多个副本,通过网络传输到task中,此时每个task都有一个变量副本,如果变量本身比较大的话,那么大量的副本在网络中传输的性能开销,以及在各个节点的Executor中占有的内存导致频繁GC,都会较大的制约Spark的整体性能。因此对于上述情况,如果使用外部变量比较大时,见识使用Spark的广播变量,对变量进行广播,广播后的变量,会保证每个Executor都有一份变量副本,而Executor中的task执行共享该Executor的那份变量副本,这样的话可以大大的减少变量副本,从而减少网路传输的性能开销,减少对Executor的内存开销,降低GC频率,从而提升Spark作业执行效率。
//以下代码中算子函数中使用外部变量,没有特殊操作,每个task都会有一份list的副本
var list=...
rdd1.map(list)
/**
* 以下代码中将list封装成了 Broadcast 类型的广播变量,在算子函数中,使用广播变量时,首先判断当前task所在的Executor内存中是否有变量副本
* 如果有就直接使用,如果没有则从Driver或者其他Executor节点上远程拉取一份放到本地Executor 内训中,每个Ex而粗头儿内存只保留一份广播变量
*/
var list1=...
val broadCastList = sc.broadcast(list1)
rdd1.map(broadCastList)
2.8、使用 Kryo 序列化改善序列化性能
在spark中,涉及序列化的地方主要有三个
- 在算子函数中使用外部变量,该变量会序列化后进行网络传输。
- 将自定义的类型作为RDD的泛型类型时(比如JavaRDD,Student是自定义类型),多有自定义类型的对象,都会进行序列化,因此这种场景下也要求自定义类要实现Serializable接口。
- 使用可序列化的持久化策略时(MEMORY_AND_DISK_SER),Spark 会将RDD中的每个Partition都序列化成一个字节数组。
对于这三种序列化的地方,我们都可以使用Kryo序列化库,来优化序列化和反序列化的性能。Spark 默认使用的是Java序列化机制,也就是ObjectOutputStream/ObjectInputStream API 进行序列化和反序列化操作,但是Spark同时支持使用Kryo序列化库,Kryo序列化类库的性能比Java的序列化类库的性能高很多,官方介绍,Kryo序列化机制比Java序列化机制性能高出10倍左右,Spark之所有没有使用Kryo作为默认序列化机制的原因是,kryo 要求最好能注册所欲需要进行序列化的自定义类型,因此对于使用者来说有很大麻烦。以下是使用Kryo的代码示例,我们只要设置序列化类,在注册系列化的自定义类型即可(比如算子函数中使用到的外部变量类型,作为RDD泛型类型的自定义类型)。
private val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
//设置序列化为KryoSerializer
conf.set("spark.serializer","org.apach.spark.serializer.KryoSerializer")
//注册要序列化的自定义类型
conf.registerKryoClasses(Array(classOf[MyStudent],classOf[Person]))
2.9、优化数据结构
java中,有三种类型比较消耗内存
- 对象:每个java对象都有对象头,引用等额外信息,因此比较占用内存空间。
- 字符串:每个字符串都一个字符数组和额外信息。
- 集合类型:比如HashMap.LinkedList,因为集合类型内部通常会使用一些内部类来封装集合元素,比如 Map.Entry
因此 Spark 官方建议,在Spark开发中,特别是对于算子函数中的代码,尽量不要使用上述的数据结构,尽量使用字符串代替对象,使用原始类型(Int,Long)代替字符串,使用数组代替集合对象,这样尽可能减少内存占用。从而降低GC频率,提升Spark效率。但是我在工作发现,要做到该原则其实很难,因为我们需要考虑代码的可维护性,如果一个代码中,完全没有任何对象抽象,全是字符串拼接的方式,那么对于后续的代码维护,无疑是宜昌艰难的事情。同理所有操作都是数组实现,而不使用HashMap或者LinkedList等集合类型,那么对于我们的开发难度和代码维护也是一个极大的考研,因此我建议,在可能和适当的情况下,使用占用内存较少的数据结构,但是前提是保证代码的可维护性。