上一节我们分析了默认标签的解析,这一节看一次自定义标签,例如:context aop 等等都是自定义标签,在
分析自定义标签之前,我们先看一下SPI机制, SPI就是一个服务的扩展机制,可以把接口的实现类配置到META-INF元数据区,
框架启动时加载到缓存,最初的版本是jdk中实现的,后来在spring、springboot、dubbo中都有相应的使用。
一:jdk的spi机制
META-INF下创建services目录,然后以接口全限定名为文件名,将实现类的全限定名放进去,这样运行程序时,会加载实现类的名称进jvm,
调用的时候会调用newInstance方法实例化对象。
创建一个IAnimal接口:
package com.hello.spi;
public interface IAnimal {
void sing();
}
创建两个实现类:
package com.hello.spi;
public class Cat implements IAnimal {
@Override
public void sing() {
System.out.println("cat sing......");
}
}
package com.hello.spi;
public class Dog implements IAnimal {
@Override
public void sing() {
System.out.println("dog sing......");
}
}

测试代码:
public class TestSPI {
public static void main(String[] args) {
ServiceLoader<IAnimal> animals = ServiceLoader.load(IAnimal.class);
for (Iterator<IAnimal> iter = animals.iterator();iter.hasNext();) {
IAnimal animal = iter.next();
animal.sing();
}
}
}
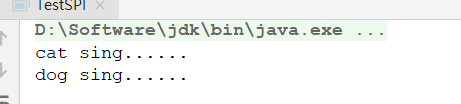
运行结果:
二:spring的spi机制
看一下spring的类DefaultNamespaceHandlerResolver这个类,会懒加载spring.handler文件内配置的实现类进内存
/**
* Load the specified NamespaceHandler mappings lazily.
*/
private Map<String, Object> getHandlerMappings() {
Map<String, Object> handlerMappings = this.handlerMappings;
if (handlerMappings == null) {
synchronized (this) {
handlerMappings = this.handlerMappings;
if (handlerMappings == null) {
if (logger.isTraceEnabled()) {
logger.trace("Loading NamespaceHandler mappings from [" + this.handlerMappingsLocation + "]");
}
try {
Properties mappings =
PropertiesLoaderUtils.loadAllProperties(this.handlerMappingsLocation, this.classLoader);
if (logger.isTraceEnabled()) {
logger.trace("Loaded NamespaceHandler mappings: " + mappings);
}
handlerMappings = new ConcurrentHashMap<>(mappings.size());
CollectionUtils.mergePropertiesIntoMap(mappings, handlerMappings);
this.handlerMappings = handlerMappings;
}
catch (IOException ex) {
throw new IllegalStateException(
"Unable to load NamespaceHandler mappings from location [" + this.handlerMappingsLocation + "]", ex);
}
}
}
}
return handlerMappings;
}
读取META-INF/spring.handlers目录下的实现类进jvm


然后缓存到handlerMappings,等待后面使用

这个是spring-context工程下spring.handlers文件内容: key为命名空间url value为类的全限定名,加载完成后会缓存到handlerMappings中
http://www.springframework.org/schema/context=org.springframework.context.config.ContextNamespaceHandler http://www.springframework.org/schema/jee=org.springframework.ejb.config.JeeNamespaceHandler http://www.springframework.org/schema/lang=org.springframework.scripting.config.LangNamespaceHandler http://www.springframework.org/schema/task=org.springframework.scheduling.config.TaskNamespaceHandler http://www.springframework.org/schema/cache=org.springframework.cache.config.CacheNamespaceHandler
三:自定义标签的解析
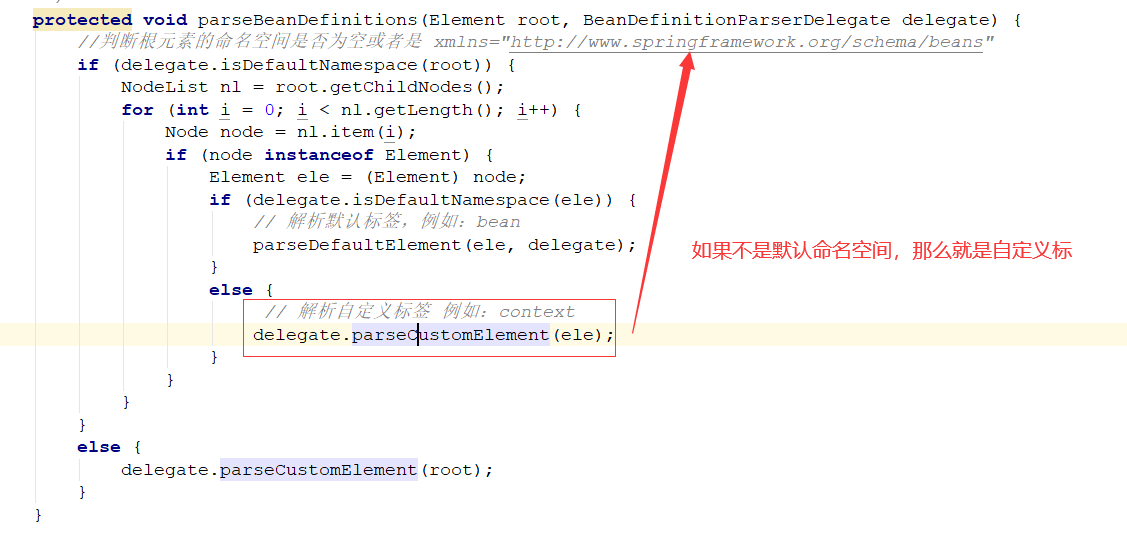
解析自定义元素:

寻找命名空间对象:

初始化,把属性和解析器缓存映射,主要的处理缓存逻辑都在父类NamespaceHandlerSupport中
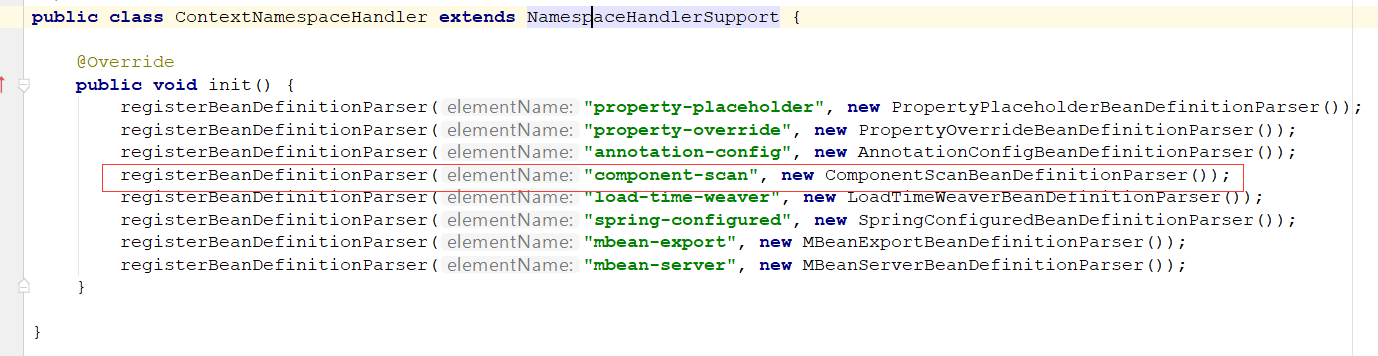

这样初始化之后,这个NamespaceHandler就包含了众多解析器。

我们来分析一下如何解析自定义标签:

根据element寻找解析器,上一步在创建命名空间handler的时候init时已经将解析器注册进命名空间handler缓存

解析器拿到之后,就要开始真正的解析工作了。

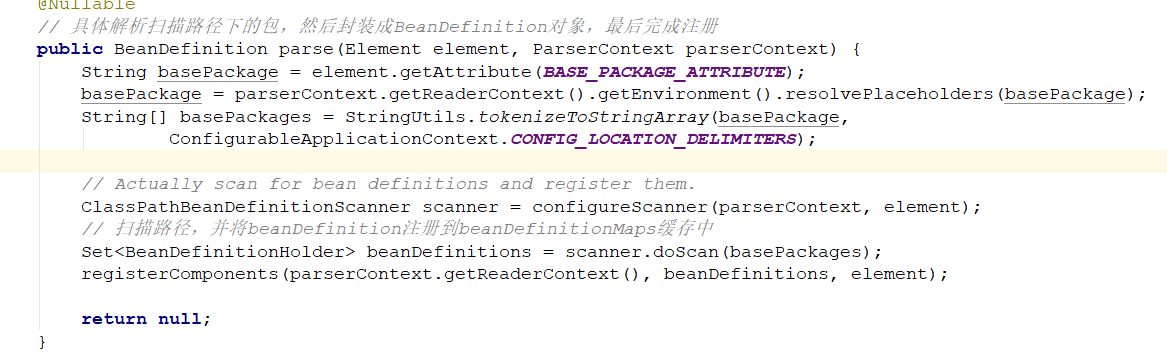
ComponentScanBeanDefinitionParser类中的parse方法:
拿到basePackage 包路径,创建ClassPathBeanDefinitionScanner的扫描器,然后根据basePackages进行doScan扫描
创建一个扫描器:

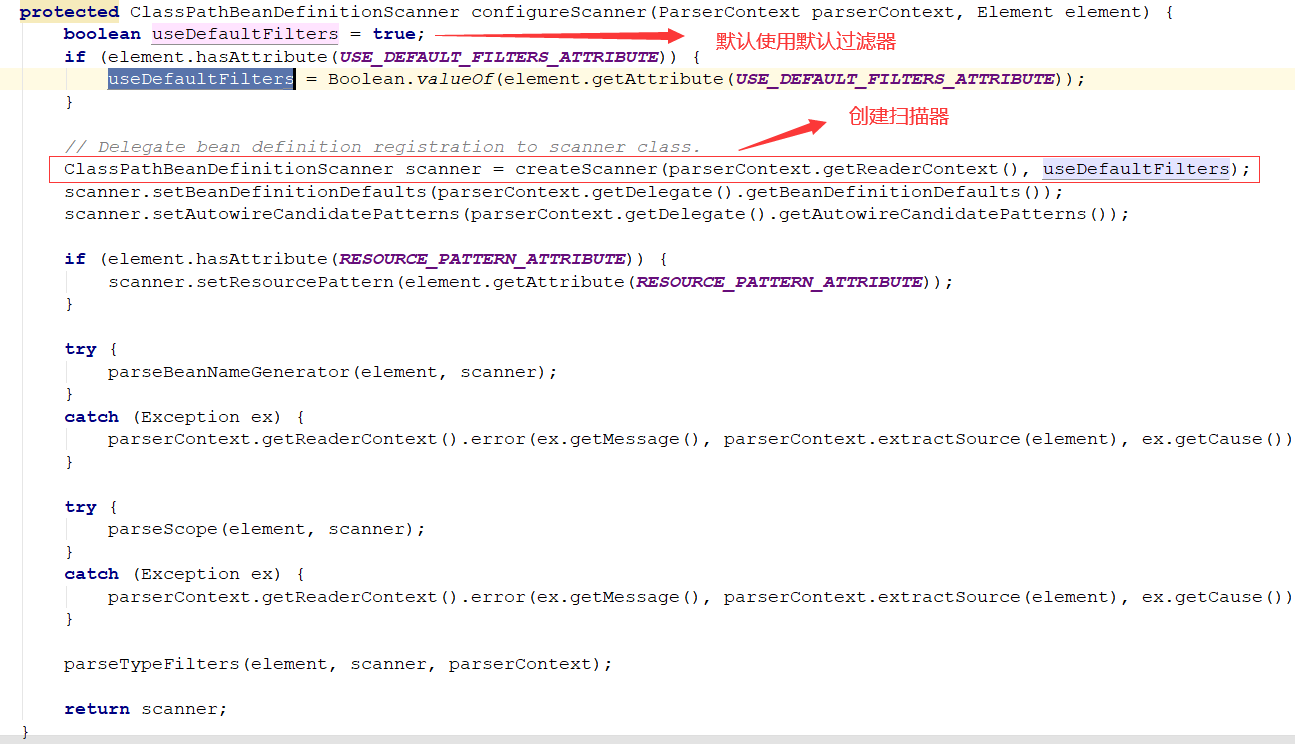

创建扫描器完成后,就可以扫描basePackages包了
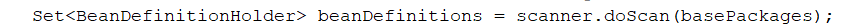
扫描逻辑:
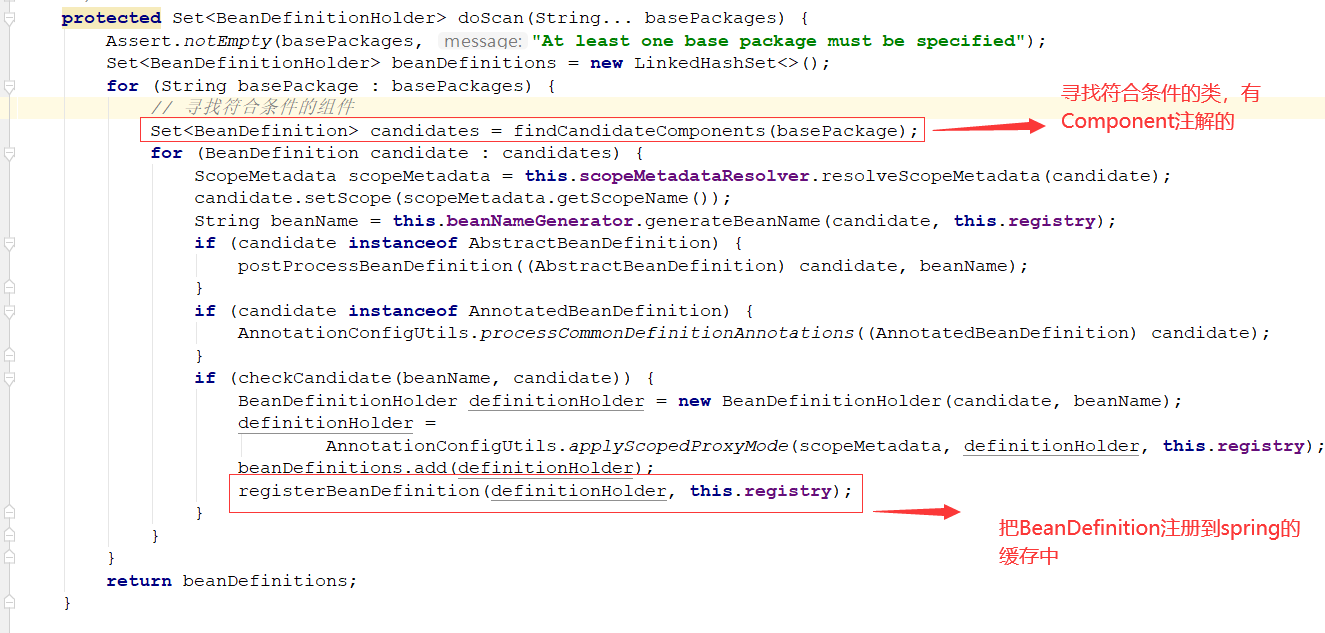
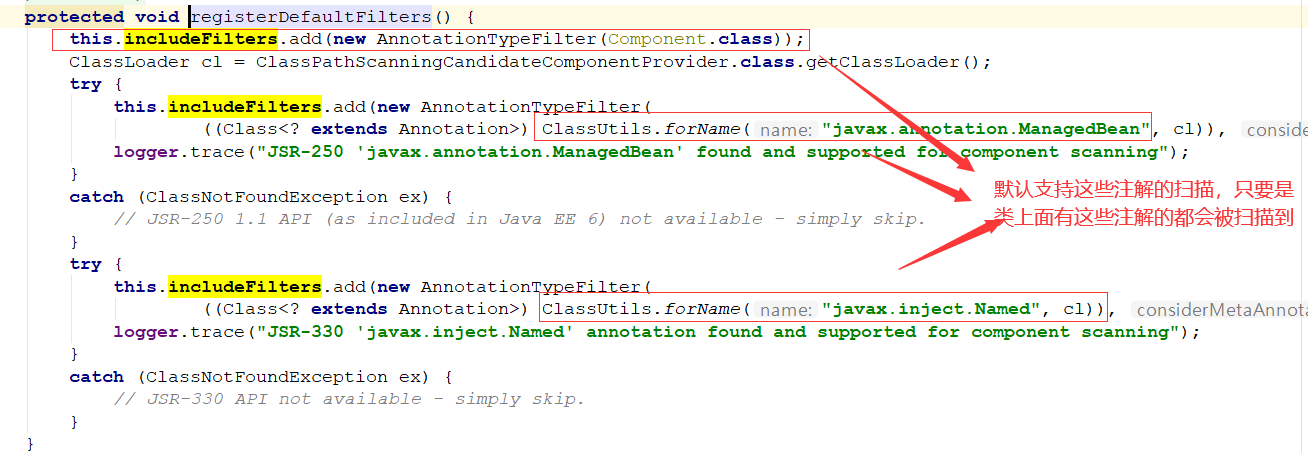
看如何寻找符合条件的class

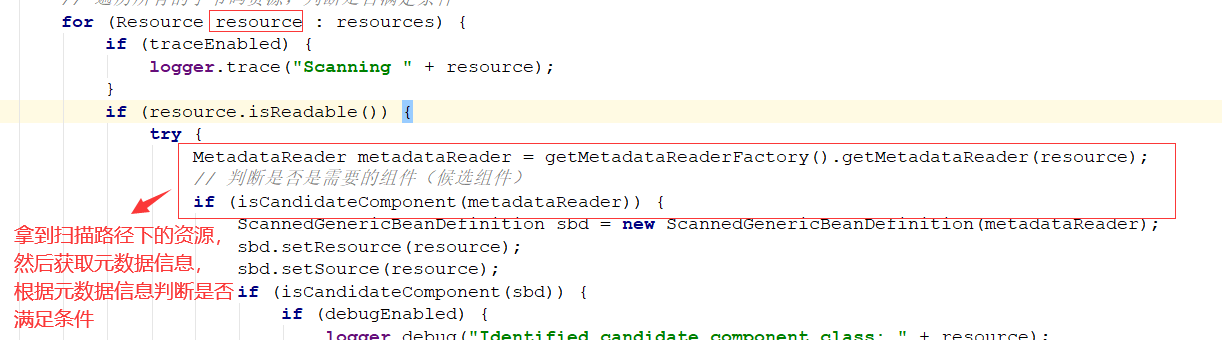
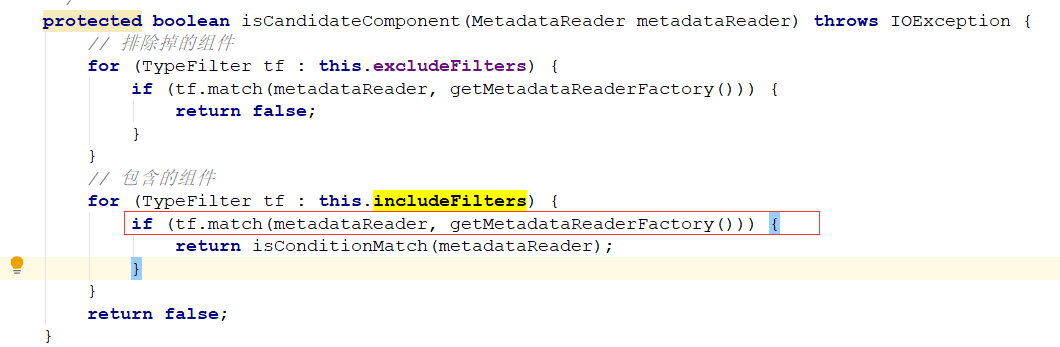


如果发现这个类上面有Component注解信息,那么就符合条件。
对于符合条件的,就会创建一个beanDefinition对象,然后将元数据信息封装进去,并放入容器中,最后返回,
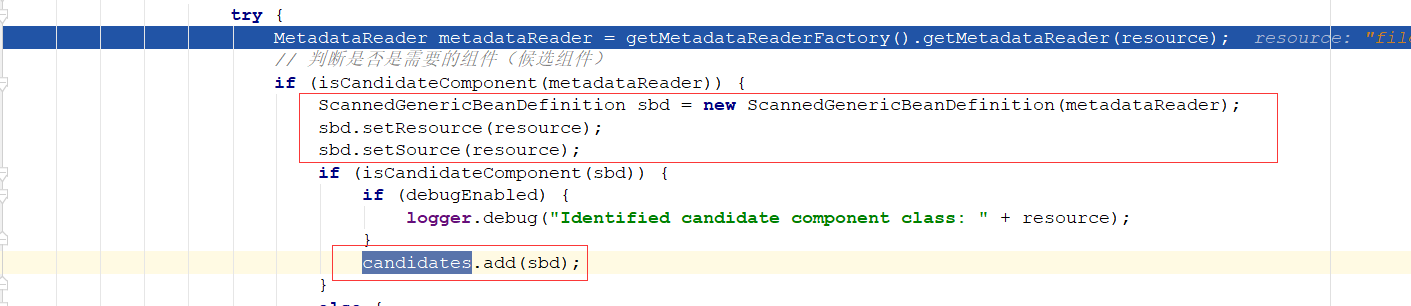
拿到candidates后,就会遍历处理,然后注册到spring容器中,这样这个context的自定义标签解析完毕。
<!--配置扫描路径--> <context:component-scan base-package="com.hello" />
四:总结
上面就是以context:component-scan这个自定义标签为例,分析了解析的流程,大概流程如下:
1:获取元素命名空间url ,nameSpaceUrl
2:根据namespaceUrl找到nameSpaceHandler,这个使用到了spi懒加载机制(初次获取会反射创建handler对象,然后缓存)
3:创建handler后,会init初始化,初始化的过程中会缓存各种解析器
4:根据元素的localname,查询到解析器,然后调用解析器的parse方法开始解析
无论是默认标签还是自定义标签,它们最终都是生成beanDefinition对象,然后注册到beanDefinitionMaps中缓存。