背景:
四个同一副本控制集的Pod被频繁的重拉,数日内次数达到了百余次。
问题原因
node资源不足。
排查:
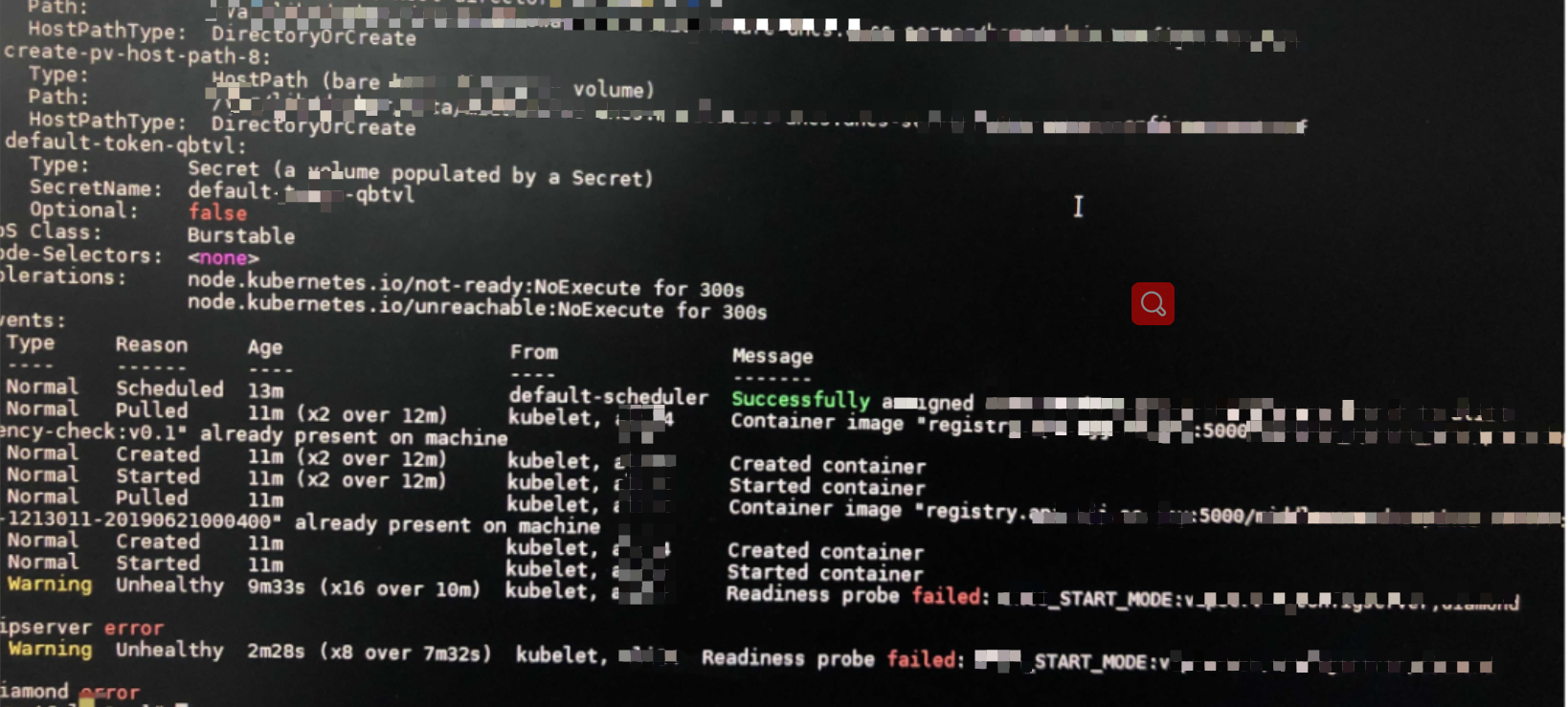
1、kubectl describe pod $pod名
输出只显示就绪探测失败。
就绪探测是当时Pod重拉时候未Running 1/1时显示的,Running 1/1后此报错就不用关注了。
输出的describe也没有报oomkill的问题
所以没有输出相关的重拉原因。
2、将此Pod的优先级调高。
kubectl edit sts pod的副本控制集名
将里面的limit与requests添加cpu 2 并且将requests的8g改为与limit相同的16g
将资源调大后两个被频繁重拉的 Pod可以快速变为1/1 Running了,能改善被频繁重拉的次数。
3、按照上步操作后部署被频繁重拉的四个pod结果有两个pod起不来报错node上的内存不足
kubectl describe pod $pod名
执行出来后有内存不足的报错。
4、kubectl get pod -owide |grep pod名 查看被频繁重拉pod所在节点名字

5、 kubectl top node 发现Pod所在的node内存使用率达到百分之60以上,pod就被自动delete重拉
6、登陆到被频繁重拉pod对应的节点上查看/var/logs/messages显示有内存不足的报错:
Mar 13 12:55:59 $主机名 systemd: Scope libcontainer-75049-systemd-test-default-dependencies.scope has no PIDs. Refusing.
Mar 13 12:55:59 $主机名 systemd: Scope libcontainer-75049-systemd-test-default-dependencies.scope has no PIDs. Refusing.
Mar 13 12:55:59 $主机名 systemd: Created slice libcontainer_75049_systemd_test_default.slice.
Mar 13 12:55:59 $主机名 systemd: Removed slice libcontainer_75049_systemd_test_default.slice.
Mar 13 12:56:00 $主机名 systemd: Scope libcontainer-75086-systemd-test-default-dependencies.scope has no PIDs. Refusing.
Mar 13 12:56:00 $主机名 systemd: Scope libcontainer-75086-systemd-test-default-dependencies.scope has no PIDs. Refusing.
Mar 13 12:56:00 $主机名 systemd: Created slice libcontainer_75086_systemd_test_default.slice.
Mar 13 12:56:00 $主机名 systemd: Removed slice libcontainer_75086_systemd_test_default.slice.
8、free -gh 查看到节点是32G内存,此问题是node内存不足导致的,需要给node扩容内存。