Kaggle房价预测
作为Kaggle竞赛中的经典入门题目,我主要在kernels中学习其他人分析和处理数据的流程,首先是通过各类plt的图表,分析数据特征和房价之间的相关性
载入数据集
df_train = pd.read_csv('./input/train.csv')
df_test = pd.read_csv('./input/test.csv')
房价整体分布概率直方图
print(df_train['SalePrice'].describe())
sns.distplot(df_train['SalePrice'])
plt.show()
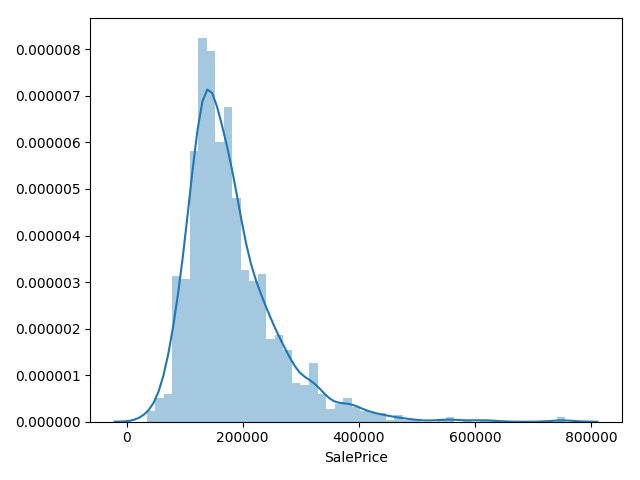
根据直方图可以看出整体房价大致的区间分布
总平方英尺,散点图
var = 'GrLivArea'
# axis: 需要合并链接的轴,0是行,1是列
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
data.plot.scatter(x=var, y='SalePrice', ylim=(0, 800000))
plt.show()
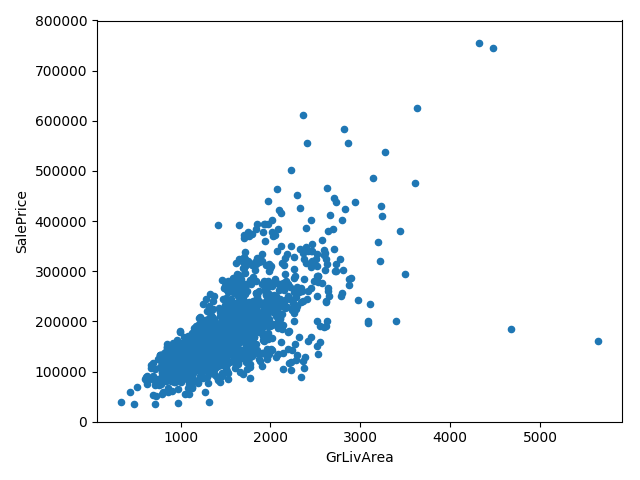
在常规印象中,面积越大房价越贵,根据散点图可以看出基本符合规律,除了少数离群点。
建造年份,箱线图
var = 'YearBuilt'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
f, ag = plt.subplots(figsize=(16, 8))
fig = sns.boxplot(x=var, y="SalePrice", data=data)
fig.axis(ymin=0, ymax=800000)
plt.xticks(rotation=90)
plt.show()

一般规律是房屋的建造年份越新,房价越高。根据箱线图的走势,基本符合预期。但也有部分年份比较旧的房屋房价特别高,推测可能是历史老屋,或者古董别墅之类的。
相关系数,热点图
corrmat = df_train.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True)
plt.show()

在前面单独分析了几个属性后,我们现在查看train训练集中所有属性相关系数的热点图。
相关系数矩阵,获取相关性最高的前10个特征
k = 10
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(df_train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10},
yticklabels=cols.values, xticklabels=cols.values)
plt.show()

在热点图大致了解所有属性的相关性后,接着按照相关系数排序,取前10个特征输出相关矩阵
特征筛选
根据Kaggle官方提供的字段说明里,GarageCars和GarageArea描述的是车库容纳车辆数量和车库面积,描述的基本是同一件事情,而且相关系数分别是0.64和0.62,因此只取其中的GrLivArea
离群点检测
观察GrLivArea的散点图,最右侧2个点明显不符,因此在训练数据集中删除掉
df_train.sort_values(by='GrLivArea', ascending=False)[:2]
print("drop 2 outliers")
print(df_train.sort_values(by='GrLivArea', ascending=False)[:2])
df_train = df_train.drop(df_train[(df_train['GrLivArea'] > 4000) & (df_train['SalePrice'] < 300000)].index)
随机森林,建模,预测
# 根据相关度选择特征
predictor_cols = ['OverallQual', 'GrLivArea', 'GarageCars', 'TotalBsmtSF', 'TotRmsAbvGrd', 'YearBuilt']
train_X = df_train[predictor_cols]
my_model = RandomForestRegressor()
my_model.fit(train_X, train_y)
# GarageCars,TotalBsmtSF存在空值,
df_test['GarageCars'] = df_test['GarageCars'].fillna(0)
df_test['TotalBsmtSF'] = df_test['TotalBsmtSF'].fillna(0)
test_X = df_test[predictor_cols]
predicted_prices = my_model.predict(test_X)
# 取整
print(predicted_prices)
my_submission = pd.DataFrame({'Id': df_test.Id, 'SalePrice': predicted_prices})
my_submission.to_csv('./submission.csv', index=False)