一、存储引擎
1、InnoDB引擎
设计目标是面向在线事务(OLTP)处理的应用。
支持事务、行级锁、通过多版本并发控制(MVCC)支持高并发、提供一致性非锁定读、next-key locking避免幻读、主键聚集索引
2、MyISAM引擎
设计目标是面向OLAP应用。
不支持事务、不支持行锁、表锁设计、支持全文索引
3、其他存储引擎
略
二、InnoDB体系结构
1、线程模型
InnoDB存储引擎是多线程模型,后台有多个不同的线程,用于处理不同的任务。
- Master Thread:核心线程,将缓冲池中的数据异步刷新到磁盘
- IO Thread:负责io请求的回调处理
- Purge Thread:负责undo页的回收
- Page Cleaner Thread:负责脏页的刷新
1.1、Master Thread
内部由多个循环组成。包括主循环(loop),后台循环(background loop)
主循环每隔一秒的操作
- 把日志缓冲刷新到磁盘,即使这个事务还没有提交。很好的解释了再大的事务提交时间也很短
- 合并插入缓冲
- 至多刷新n(可配置,自动调整,1.2版本之后)个脏页到磁盘
- 没有用户活动,切换到background loop
主循环每隔10秒的操作
- 合并最多5个插入缓冲
- 缓冲日志刷新到磁盘
- 删除无用的undo页
- 刷新脏页到磁盘(超过70%,刷新100页,没超过70%,刷新10页)
2、内存模型
2.1、缓冲池
InnoDB是基于磁盘的存储系统,为了弥补cpu和磁盘性能的差距,将从磁盘读出的数据保存在内存中,下次读取先从缓冲池中读取。有数据更新也先更新缓冲池的数据,通过checkpoint机制写回磁盘。缓冲池中包括索引页、数据页、undo页、插入缓存、锁信息等
2.2、缓冲池管理(LRU List)
最近做少使用算法,最频繁使用的页在List前端,最少使用的页在List末尾。当缓冲池容量不足容纳新数据时,先从尾部释放数据页。新数据插入在List的midpoint(List的5/8,对朴素LRU的优化,朴素LRU插入List头部。避免大量一次性查询把频繁使用的页刷出缓冲池)
2.3、脏页管理(Flush List)
当数据被更新,缓冲池中的数据首先被更新,修改之后的页称为脏页。脏页会保存到Flush List中,通过checkpoint机制把脏页数据写回磁盘
2.4、重做日志(redo log)缓冲
首先把重做日志信息存入缓冲区,然后按照一定频率同步到重做日志文件中。以下三种情况都会触发重做日志缓存同步到重做日志文件:
- Master Thread 每隔一秒刷新
- 每个事务提交时
- 重做日志缓冲池容量达到阈值,一般是1/2
2.5、check point技术
为了防止宕机导致事务未提交信息丢失,在事务提交时,先把数据保存到重做日志(redo log)中,再修改页。保证了持久性(D)
发生宕机,重启之后自动从重做日志中恢复数据。
但是这里有以下问题:
- 重做日志过大,宕机重启恢复数据太慢
- 重做日志不能无限扩容,需要循环利用
- 重做日志不可用怎么办
check point就是为了解决这些问题:
- 缩短数据库恢复时间
- 重做日志不可用,刷新脏页
- 缓冲池不够用,将脏页刷新到磁盘
check point触发时机:
- Master Thread check point。每隔一秒触发一次
- LRU List check point。保证LRU List中有100个空闲页,如果清理的页中有脏页,触发check point 强制刷新脏页数据到磁盘
- Dirty Page too mush check point。脏页太多,超过阈值,触发check point 强制刷新脏页数据到磁盘
3、关键特性
3.1、插入缓存
(1)为什么需要插入缓存?
我们知道索引分为聚集索引和非聚集索引。
聚集索引一般是自增的唯一id,页中的数据记录按顺序存放,写入的时候不需要随机读取其他页中的数据,写入速度很快(如果用UUID作为主键,写入速度会很慢,每次写入都需要随机读)
实际应用中,一张表往往还有非聚集索引的存在。非聚集索引叶子节点的插入不是顺序的,需要离散的访问非聚集索引页,随机读取导致了插入数据的性能下降。插入缓存就是为了优化这种场景下的插入速度
(2)什么场景会触发插入缓存?
- 索引是辅助索引
- 索引不是唯一索引
对于非聚集索引的插入,会先判断非聚集索引页是否在缓冲池中,如果在缓冲池中,直接插入索引页,如果没在,先放入到insert buffer对象中,然后再以一定的频率把insert buffer中的数据和非聚集索引的叶子节点进行数据合并
(3)实现原理
insert buffer 的数据结构也是B+树,有记录要插入的时候,会对记录进行封装,按照记录的插入顺序进行编号,是顺序写入
3.2、两次写
(1)为什么需要插入两次写?
如果InnoDB正在写入某个页的数据到磁盘,正好写了一部分的时候宕机了。这种情况称为部分写失效,会导致数据丢失
(2)实现原理
double write由两部分组成。一部分是double write缓冲,一部分是物理磁盘连续共享空间。在刷新脏页数据的时候,先复制一份脏页数据到两次写缓存中,在顺序写入共享磁盘中(因为是顺序写性能影响不大)。最后写入数据存储磁盘中(离散写)
3.3、自适应hash索引优化
hash是非常快的查询方式,时间负责度为O(1)。而B+树的查找次数取决于树的高度。
如果一个页被频繁的访问,而且访问模式也相同(联合索引使用最左原则)。会自动针对这页数据根据缓冲池中的索引建立Hash索引提高查询速度
3.4、异步IO
可以在发出一个IO请求后,在发出另外的IO请求,没必要等待上一次的IO请求处理完成。把全部IO请求都发出,等待所有IO操作的完成,这就是AIO(Aysnc IO)
三、文件
MySQL据库和InnoDB存储引擎有很多类型的文件,每种文件用处不同。主要有参数文件、sokcet文件、pid文件、日志文件、表结构文件、存储引擎文件
1、日志文件
- 错误日志:记录启动运行以及关闭遇到的错误信息
- 查询日志:记录所有的查询记录
- 二进制文件(binlog):记录所有的数据更改记录。用于数据恢复和数据复制。事务中未提交的二进制日志会存放到缓冲中,等事务提交时直接将缓冲中的日志同步到二进制文件中。通过配置可以指定写缓冲多少次之后同步到磁盘,如果值设置大于1,当发生宕机时可能会丢失数据
- 慢查询日志:查询时间超过指定阈值的记录
2、InnoDB存储引擎文件
- 表空间文件:存储数据
- 重做日志文件:存储事务日志
四、表
1、索引组织表
InnoDB中,表数据都是按照主键顺序组织存放的。每张表都有主键,如果没有显示的定义主键,会把唯一索引作为主键。如果唯一索引也没有,会自动创建6字节大小的指针作为主键
2、存储结构
所有数据都存放在表空间中,表空间又由段、区、页组成
- 段:表空间由各个段组成。段的管理由引擎自身完成
- 区:每个区大小为1M,由连续页组成
- 页:磁盘管理的最小单位,默认每个页大小16k
- 行:数据是按行进行存放的,一个页最多存放16k/2-200=7992行
五、索引
数据库的索引结构是B+树,高度一般在2-4层,一次查找只需要2-4次的io。索引分为聚集索引和非聚集索引
1、聚集索引
按照每张表的主键构建的B+树,叶子节点中存储着整张表的行记录数据,每个叶子节点通过双向链表进行连接。因为实际的数据页只能按照一个聚集索引进行排列,每张表只能拥有一个聚集索引
聚集索引对于主键的范围查找和排序查找速度非常快。
2、非聚集索引(辅助索引)
叶子节点不包含行记录的全部数据,叶子节点只存储了键值和指向聚集索引的书签
3、索引创建和删除
3.1、Online Scheme Change(OSC)
在线架构改变,通过php脚本实现,在索引的创建或删除过程中,可以有读写事务对表进行操作。过程如下:
- 创建和原表结构一样的新表
- 对新表进行alter table操作
- 创建临时表
- 对原表添加触发器,把新产生的数据变化同步到临时表
- 把原表的数据同步到新表
- 将临时表的数据同步到新表
- 对新表创建辅助索引
- 再次回放临时表的数据到新表
- 新表和旧表交换名字rename
3.2、mysql5.6开始支持online DDL
通过新的alter语法,可以选择索引的创建方式
4、什么样的数据适合创建辅助索引?
Cardinality表示索引中唯一值的数据的估计值(不是实时更新,使用采样法延迟更新),应尽可能接近表中数据总行数。
5、联合索引
联合索引也是一棵B+树,不同的是索引键值的数量大于等于2。联合索引的第二个好处是已经对第二个键值做了排序处理,减少了一次额外的排序操作

六、锁
1、MyISAM引擎
MyISAM引擎的锁是表锁设计,并发情况下读没有问题,但是写的性能会比较低
2、InnoDB引擎
2.1、锁的类型
- 共享锁(S Lock)
- 排它锁(X Lock)
2.2、一致性非锁定读
实现原理是通过MVCC机制实现,如果读取的行正处于update或delete中,读操作不会去等待行上X锁的释放,而是去读取行的快照数据。
一致性非锁定读可以极大的提高并发性能
不同的事务隔离级别,读取的快照版本是有差别的
- 读已提交隔离级别,总是读取最新的快照版本。可能会产生幻读
- 可重复读隔离级别,总是读取事务开始后第一次读取的快照版本。可以避免幻读的产生
2.3、一致性锁定读
默认配置下,采用可重复读的隔离级别,读取数据采取的是一致性非锁定读。
但是某些场景下需要对读取操作加锁来保证严格的数据一致性,这时候可以显式的对读取的记录进行加锁:
- select *** for update(对读取记录加X锁)
- select *** lock in share model(对读取记录加S锁)
2.4、锁的算法
- record lock:单个记录的锁。
- gap lock:间隙锁,锁定一个范围,不包括记录本身
- next-key lock:gap lock+record lock
默认隔离级别(可重复读)下,默认加的是next-key lock(为了解决幻读问题),当索引中含有唯一属性时,会降级为record lock。
在读已提交隔离级别下,加的是record lock
举个例子:
现在表z,有a,b两列,a是主键索引,b建立辅助索引。现在记录如下:(1,1)(3,1)(5,3)(7,6)(10,8)
select * from z where b=3 for update
因为锁是通过对索引加锁实现的。所以这里需要对主键索引和辅助索引加锁,主键索引加的锁是record lock,辅助索引加的锁是next-key lock,锁定范围是(1,3)、3、(3,6)
七、事务
1、事务的分类
- 扁平事务(所有操作原子性,要么全提交,要么全回滚)
- 带有保存点的扁平事务(允许事务执行过程中回滚到同一事务中较早的状态)
- 嵌套事务(顶层事务控制着各个层次的事务)
- 分布式事务(分布式环境下的扁平事务)
2、事务的实现
隔离性通过锁来实现,原子性、一致性、持久性通过redo日志和undo日志实现,事务提交时,必须将事务的所有日志写入重做日志进行持久化,并且当事务提交后才算成功
2.1、binlog 的写入机制
写入步骤:
- 1、先把日志写到 binlog cache
- 2、write,把日志写入到文件系统的 page cache,并没有把数据持久化到磁盘,所以速度比较快
- 3、fsync,将数据持久化到磁盘。一般情况下,我们认为 fsync 才占磁盘的IOPS。
write 和 fsync 的时机,是由参数 sync_binlog 控制的:
- 1)sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
- 2)sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
- 3)sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
每个线程有自己 binlog cache,但是共用同一份 binlog 文件。
2.2、redo log写入机制
写入步骤:
- 1)写入到 redo log buffer 中,物理上是在 MySQL 进程内存中
- 2)写到磁盘 (write),但是没有持久化,物理上是在文件系统的 page cache 里面
- 3)持久化到磁盘(fsync)
为了控制 redo log 的写入策略,InnoDB 提供了 innodb_flush_log_at_trx_commit 参数,它有三种可能取值:
- 1)设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ;
- 2)设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;
- 3)设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache。
让一个没有提交的事务的 redolog 写入到磁盘中的三种情况:
- 1)事务执行中间过程的 redo log 也是直接写在 redo log buffer 中的,这些redo log 也会被后台线程一起持久化到磁盘。也就是说,一个没有提交的事务的 redo log,也是可能已经持久化到磁盘的。
- 2)redo log buffer 占用的空间即将达到 innodb_log_buffer_size 一半的时候,后台线程会主动写盘。注意,由于这个事务并没有提交,所以这个写盘动作只是 write,而没有调用 fsync,也就是只留在了文件系统的 page cache。
- 3)并行的事务提交的时候,顺带将这个事务的 redo log buffer 持久化到磁盘。假设一个事务 A 执行到一半,已经写了一些 redo log 到 buffer 中,这时候有另外一个线程的事务 B 提交,如果 innodb_flush_log_at_trx_commit 设置的是 1,那么按照这个参数的逻辑,事务 B 要把 redo log buffer 里的日志全部持久化到磁盘。这时候,就会带上事务A 在 redo log buffer 里的日志一起持久化到磁盘。
2.3、如何提高磁盘的写入能力?
- 1) redo log 和 binlog 都是顺序写,磁盘的顺序写比随机写速度要快;为了避免磁盘页面的随机写,只需要保证事务的redo log写入磁盘即可,这样可以通过redo log的顺序写代替页面的随机写
- 2)组提交机制,可以大幅度降低磁盘的 IOPS 消耗。
2.4、组提交
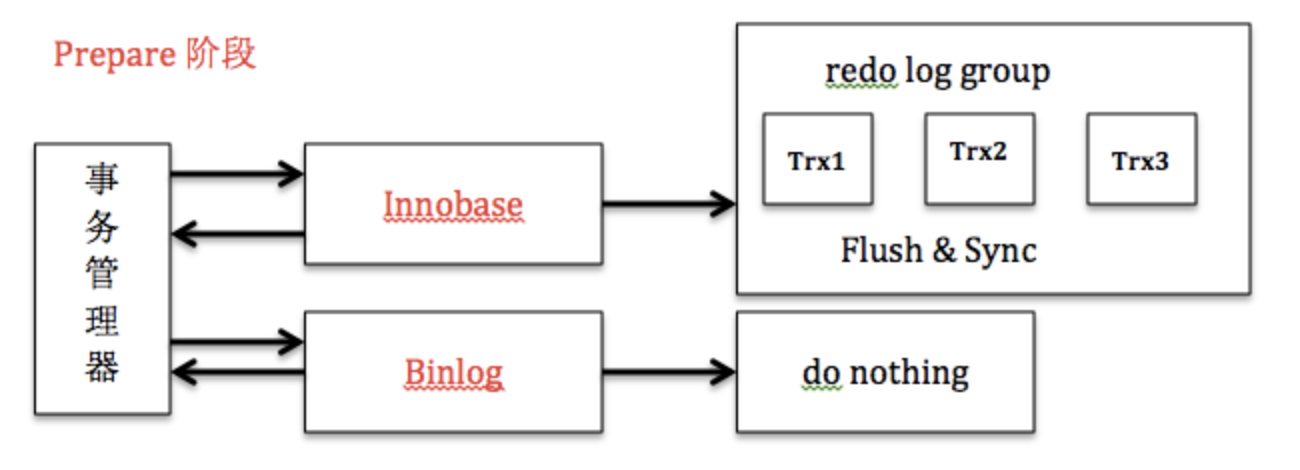
日志逻辑序列号(log sequence number,LSN),是单调递增的,用来对应 redo log 的一个个写入点。每次写入长度为 length 的 redo log, LSN的值就会加上 length
三个并发事务 (trx1, trx2, trx3) 在 prepare 阶段,都写完 redo log buffer,持久化到磁盘的过程,对应的 LSN 分别是 50、120 和 160。
如果Trx3日志先获取到log_mutex进行落盘,它就可以顺便把[LSN1---LSN3]这段日志也刷了,这样Trx1和Trx2就不用再次请求磁盘IO
- 获取 log_mutex
- 若flushed_to_disk_lsn>=lsn,表示日志已经被刷盘,跳转5
- 若 current_flush_lsn>=lsn,表示日志正在刷盘中,跳转5后进入等待状态
- 将小于LSN的日志刷盘(flush and sync)
- 退出log_mutex
所以,一次组提交里面,组员越多,节约磁盘 IOPS 的效果越好
如果你想提升 binlog 组提交的效果,可以通过设置binlog_group_commit_sync_delay 和
binlog_group_commit_sync_no_delay_count 来实现。
- 1)binlog_group_commit_sync_delay 参数,表示延迟多少微秒后才调用 fsync;
- 2)binlog_group_commit_sync_no_delay_count 参数,表示累积多少次以后才调用 fsync。
这两个条件是或的关系,只要有一个满足条件就会调用 fsync。
2.5、事务提交时序
两阶段提交:
- Prepare阶段,记录undo log,innodb刷redo log到磁盘,并将回滚段设置为Prepared状态,binlog不作任何操作。
- commit阶段,innodb释放锁,释放回滚段,设置提交状态,binlog刷binlog日志到磁盘。
出现异常,需要故障恢复时,若发现事务处于Prepare阶段,并且binlog存在则提交,否则回滚。通过两阶段提交,保证了redo log和binlog在任何情况下的一致性。

通常我们说 MySQL 的“双 1”配置,指的就是 sync_binlog 和innodb_flush_log_at_trx_commit 都设置成 1。也就是说,一个事务完整提交前,需要等待两次刷盘,一次是 redo log(prepare 阶段),一次是 binlog。
2.6、关于事务提交时序的优化
将prepare阶段的刷redo动作移到了commit(flush-sync-commit)的flush阶段之前,保证刷binlog之前,一定会刷redo。
移到commit阶段的好处是,可以不用每个事务都刷盘,而是leader线程帮助刷一批redo。
如何实现,很简单,因为log_sys->lsn始终保持了当前最大的lsn,只要我们刷redo刷到当前的log_sys->lsn,就一定能保证,将要刷binlog的事务redo日志一定已经落盘。通过延迟写redo方式,实现了redo log组提交的目的,而且减少了log_sys->mutex的竞争。
目前这种策略已经被官方mysql5.7引入。