作者:网易智企自然语言处理专家 天晔
客服机器人的核心任务是有效回答用户各式各样的问题。而回答问题需要知识,通常客服系统所使用的知识的表现形式是问题-答案对(Question-Answer Pair),这些信息通常由了解实际业务场景的同学整理而成,在客服系统里,这些问题-答案对的集合通常被命名为知识库,下面的例子是人力资源共享服务中心场景(HRSSC)下典型知识库的一个片段。
- 问题一:员工有多少天带薪年假?
答案:7天。 - 问题二:发工资是哪一天?
答案:每月5号。 - 问题三:公司支付的公积金缴纳比例?
答案:缴费基数的12%。
可以想象,不同的场景会有完全不一样的知识库,即便某一固定场景下,因每家公司政策不同也会设置不一样的知识库,例如为员工购买了附加商业保险的公司的HRSSC系统知识库可能会有这样的问答对话:
- 问题四:公司赠送的附加商业保险怎么申请?
答案:在职期间自动生效,无须专门申请。
此外通过知识库,可以方便实现附加功能,例如一家电商公司的知识库可能有如下知识点:
- 问题一:货怎么还没送到,服务太差了!
答案:很抱歉,亲,给您带来了不好的购物体验。请您稍安勿躁,物品正向您飞奔而去。
这里的标准问法并非传统意义上的问题,而是投诉和抱怨。通过该知识点的答案,客服机器人提供了情绪安抚功能。
机器人问答匹配率是衡量客服系统智能程度的核心指标,它的定义如下:
机器人问答匹配率 = 用户问题被正确匹配到知识库中若干知识点的数量 / 用户输入的所有问题的数量
换言之,机器人问答匹配率表达的是用户发出的问题中,客服机器人能从知识库中选择正确的问题并给出答复的比率,即机器人自己能正确作答的比率。
不难理解,这个指标直接决定了客服系统的访客满意度。
这个指标达到较高值对客服系统是极具挑战的,原因是针对相同含义,博大精深的汉语具备几乎是无穷多种表达方式。例如,我们来列举一些形容小姐姐美丽的表达:
炉边人似月,皓腕凝雪霜。
回眸一笑百媚生,六宫粉黛无颜色。
娴静似娇花照水,行动如弱柳扶风。
沉鱼落雁鸟惊喧,羞花闭月花愁颤。
月光下,你带着笑地向我步来,月光与雪色之间,你是第三种绝色。
每当你向我走来,看见了星辰大海。
你把蓝天穿在身上,照亮我内心。
显而易见,相同的意思有无穷种表达,无法预先在知识库里穷举。机器人在查询知识库的时候必须能正确处理事先未遇到,但是知识库中存在相似含义知识点的用户问题。这是问答匹配率提升关键点和难点。作为具备业内领先 AI 能力的服务营销一体化解决方案专家,网易七鱼的机器人问答匹配率高达90%,是如何达成的呢?
1 知识库搭建
客服系统知识库分类体系的合理性和范围广度是匹配率的最重要基础。根据上面的机器人问答匹配率公式,我们可以设想两种极端情况:
- 没有输入任何知识,知识的构建成本为零,同时用户问题被正确匹配的概率为零,即机器人问答匹配率为零;
- 知识库里的知识数量为无穷大,知识的构建成本为无穷大,即包含了用户所有可能提出的问题和答案,那么使用简单的字符串完全匹配算法,即可得到机器人问答匹配率为百分之百;
实际的知识库介于这两种极端情况之间,适合客服场景的知识库体系搭建需要专业的知识。大多数客户在第一次尝试智能客服系统时对知识库搭建并无实际经验,网易七鱼提供了专业的机器人辅助训练师服务。这些训练师处理过多种行业和场景下的知识库冷启动搭建,经验丰富, 可辅助客户在项目冷启动阶段快速搭建知识库,从而快速形成一套可用的客服系统。下图是一个典型客户的知识库冷启动过程:

我们再对比一下七鱼训练师团队辅助搭建的知识库,和对于智能机器人没有实际冷启动经验的客户自行创建的知识库:
整理前的知识库:

训练师整理后的知识库:

可以看到训练师整理后的知识库包含更多表达丰富的有效相似问法,同时消除了客户自行搭建知识库情况下包含的错误(比如“员工开介绍信” “工资问谁”被安排成是同一个知识点)。
2 知识库维护
冷启动阶段完成后,系统上线开始运行。如何在客服系统运行中不断提升知识库则成为保持和提升机器人问答匹配率的关键问题。线上系统的知识库维护需要从存量知识和增量知识两个维度分别考虑。
针对存量知识
客服行业由于人员流动性较大,系统侧的运营同学经常会发生变化。不同的客服运营同学互相之间有信息差,容易发生高度重复知识点被不断加入知识库的情况,最终知识库变得冗余低效。针对此问题,网易七鱼提供了知识查重功能,能有效发现重复度高的知识点,降低系统自干扰。下图是一个示例:

可以看到知识查重功能检测出大量相似问法分布在不同的知识点下面的情况,提示需要对知识库进行整理。
针对增量知识
针对线上运行情况,七鱼提供了 “猜你想问相似问法汇总” 和 “未知问题聚类” 两个功能点来帮助知识库运营同学提高工作效率。
猜你想问得到的相似问法:
下图是一个“猜你想问”范例,用户提问“食堂啥时候开门”,系统的知识库里并没有很接近的知识点,但是算法找到了三个比较接近的知识点,作为“猜你想问”候选提交给用户。如果用户做出了选择,比如示例里面的“1”, 那么,用户选中的问题 “餐厅开餐时间”和之前用户输入的问法“食堂啥时候开门”会在后台被保留下来。之后运营同学可以决定是否需要把“食堂啥时候开门”加入“餐厅开餐时间”所在的知识点里面。
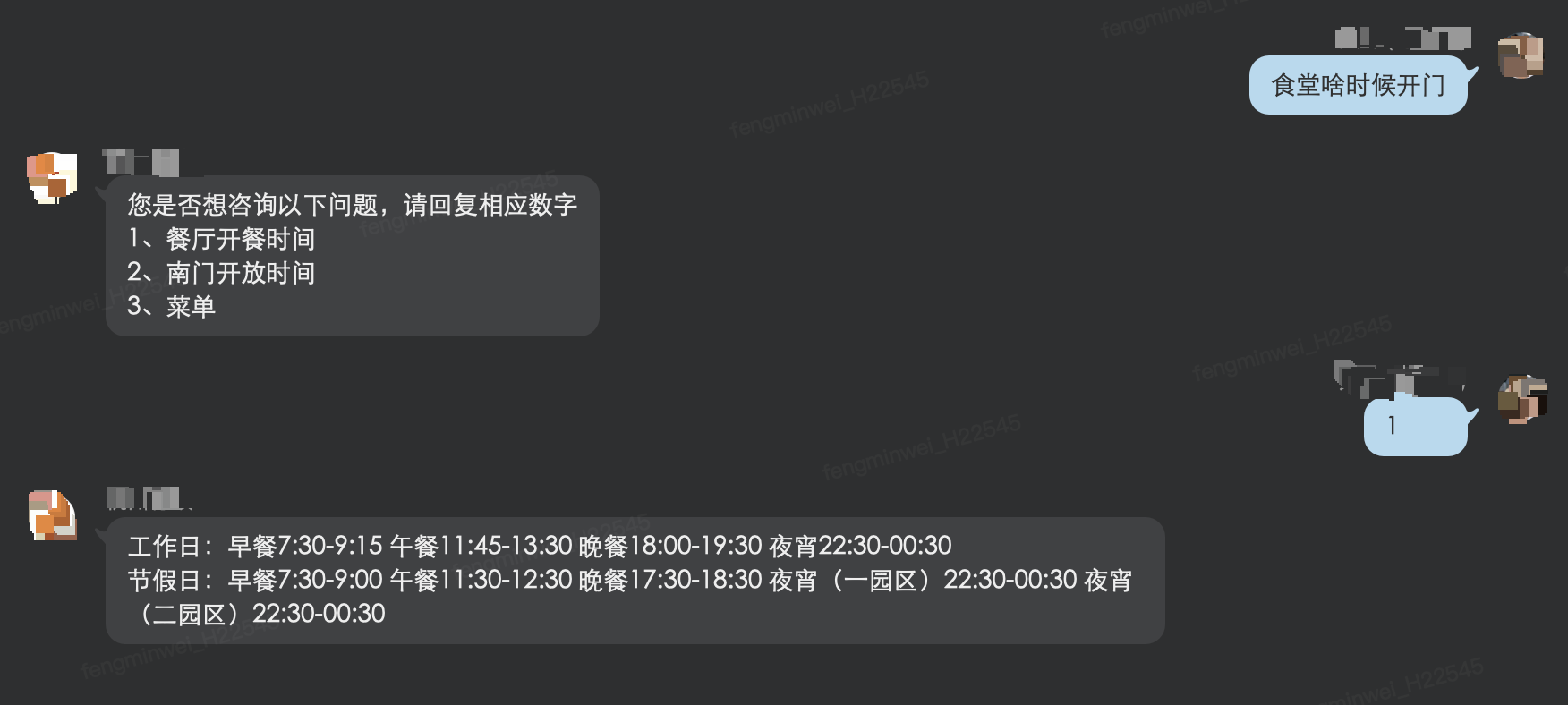
未知问题发现
系统运行过程中会不断遇到知识库中无法解答的问题,这类用户问题称为未知问题。七鱼系统提供了文本聚类的算法能力,能将这些语义接近的句子汇集到一起,例如:
- 新冠疫苗哪里可以打?
- 什么时候可以开始接种新冠疫苗?
- 如何申请新冠疫苗接种?
这类随着场景变化产生的新增用户提问大概率是不会被已有知识点包含的。七鱼的未知问题发现功能可以有效发现并归类这样的未知问题给运营同学,之后运营同学可以决定是否需要在知识库里面新增对应的知识点。 同时未知问题发现还具有舆情监控方面的作用,例如文本聚类找到了下面的相似问题:
- 今天的苹果好多烂的。
- 苹果质量不行啊。
- 你们的苹果怎么质量这么差。
- 苹果不新鲜而且好多都烂了。
上面的未知问法集中出现提示商家可能出现了品控问题,商家根据这个报警信息可以迅速做出管理动作从而解决问题。
3 句子相似度匹配核心算法
有了内容广泛,结构合理的知识库,下一步骤是算法模块的职责去找到正确匹配用户问法的知识点并将答案返回。针对同一知识点,五千年文化沉淀而成的汉语提供了枚举不尽的表达方式。用户问句和知识库中知识点语句的相似度匹配算法是七鱼机器人的核心模块,该模块的能力直接决定了客服系统的问答匹配率。七鱼客服系统的问答匹配率之所以保持在业界领先的90+%水平,主要依靠持续不断的研发投入,保证七鱼的算法能力始终处于业界前沿。下面列举一部分七鱼客服系统使用的相似度匹配算法,分别从单个语句的建模(通过数(number)去表示单个语句)和两个语句关系的建模(通过数(number)去表示待匹配两句话的关联性)两个维度来描述。
表示单个语句的算法
在计算两个句子相似度之前,先要找到合适的数学模型来做句子表征(即使用一定量的数(number)来表示句子)。七鱼内部的句子表征方法包括词袋(bag-of-words)模型, 向量空间(vector space)模型, 基于静态词向量(word embedding)模型, 基于预训练(pre-training based)模型。
词袋模型用集合来表示单个句子,每个词都是集合中的一个元素,词与词之间相互独立,即不考虑词语之间的顺序和依赖关系。通常我们会针对汉语预先定义一个词典,词袋模型的句子表征是一个向量,它的长度与该词典的大小相同,其中的每个元素代表了对应词出现的次数,例如:
- 词典:[老王,老张,想去,北京,上海,旅游]
- 例句:老王想去北京旅游
- 句子表征:[1,0,1,1,0,1]
例句中包含了“老王”、“想去”、“北京”、“旅游”四个词,并且这些词都只出现了1次,这些词在词典中的索引分别为0、2、3、5,所以句子表征向量中这些位置的元素值为1,其余元素值为0。
词袋模型使用词频作为句子向量中元素的值,还可以进一步用语义信息更丰富的指标来生成句子的向量空间模型表示,例如表示词重要性的TF-IDF指标。TF-IDF是词频(TF: Term Frequency)和逆文档频率(IDF: Inverse Document Frequency)两项指标的乘积,其思想是如果一个词在当前文档中出现的频率高,而在其他文档中出现的频率相对较低,那么说明这个词具有很好的区分度。词频可以通过统计当前句子得到,而逆文档频率则需要遍历所有文档,按照以下公式计算:
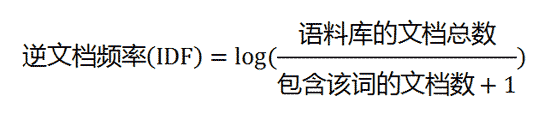
求出每个词的TF-IDF值后,类似词袋模型那样构建句向量。
词的语义信息往往体现于它与其他词的关系中,例如与“筷子”相近的词更可能是“吃饭”而非“睡眠”。静态词向量模型是对词与词之间的共现关系建模,从而获得词向量表示的方法。然后对句子中所有词的静态词向量取平均或者通过其他更复杂的神经网络结构(如CNN,LSTM),就能够获得该句话的向量表示。静态词向量中的“静态”是指对于给定的输入句子,词向量的取值是固定的,与该词对应的上下文无关。换言之,静态词向量模型训练完毕后,每个词语的静态词向量就是固定的,不因具体的输入句子改变而发生变化。
预训练模型通过大规模语料来学习在具体语境下词与词之间的关系,并且得到的词向量一般是动态的,即一个词向量的取值依赖于上下文。换言之,同一个词在不同语句中出现会对应不同的动态词向量。为了准确地获得语义,预训练模型通常从词法、句法等粒度出发构建学习任务,词法特征的任务主要有:
- 遮蔽某个词,使用上文信息去预测这个词是什么,例如GPT。
- 遮蔽某个词,使用上下文信息去预测这个词是什么, 例如BERT。
句法特征的任务主要有:
- 给定两句话S1和S2,判断二者在语料中的位置是否是连续的,例如BERT。
- 给定两句话S1和S2,判断在语料中哪句话先出现,例如ALBERT。
- 给定两句话S1和S2,判断在聊天的场景下,S2是否可以作为S1的回复,例如ERNIE 1。
- 给定一个句子集合,预测每条句子在语料中出现的顺序,例如ERNIE 2。
表示两个语句之间关系的算法
计算句子之间的相似度时,除了要考虑如何用数学模型表示单个句子之外,还要考虑对两句话之间的关联性进行建模,特别是需要考虑两个句子的关联方式和关联时机。根据建模时两个句子交互发生时机的不同,相似度算法大体上可划分为双塔模型、单塔模型、交互聚合模型三种结构。
双塔结构是纯粹基于单句句子表征的相似度算法,意思是我们先依次对两句话做出抽象的理解,然后再对比两边的理解是否一致。该类模型使用两个编码器分别对需要匹配的两句话进行编码表示,最后再计算两句话编码结果之间的相似度 (通常是余弦相似度)。双塔的意思是需要比较的两个语句如两座塔,在输出最后相似度结果之前没有任何交互,例如QA-LSTM、BCNN等。
单塔结构强调两句话之间的交互,意思是把待匹配的两句话放到一起当作整体去理解,然后得出相似与否的结论。该类模型将两句话通过某种方式拼接到一起,然后输入到编码器中计算相似度。单塔的意思是待匹配的两句话是一个整体,如同一座孤塔,待匹配的两句话从始至终都在发生信息的交互,例如 MatchPyramid、BERT等。
交互聚合结构可以认为是上述结构的一种折衷方案,类似于我们依次阅读两句话并做出初步的单句理解,基于单句理解的结果在全局层面进行第二步两句话的联合理解,最终得出句子匹配的结果。该类模型首先使用两个编码器分别对需要匹配的两句话进行编码表示,然后通过某种方法融合两部分的信息并做进一步推理,最后输出两句话之间的相似度。交互聚合的含义是整体结构如同存在一条或多条“天桥”的两座塔,下层互相独立,上层发生关联,例如ESIM、BiMPM等。
4 总结
在本篇文章中,我们详述了七鱼机器人问答匹配率高达90%以上的秘诀:
- 冷启动时在七鱼专业人工智能训练师的指导下快速搭建知识库实现服务上线;
- 系统运行中对知识库的有效维护和新知识点发现;
- 完整的算法技术栈以服务于各种场景。
在以上三个环节的加持下,七鱼机器人的问题匹配准确率在业内一直占据绝对优势。
不知您是否曾经在银行苦苦排队只为缴纳电费,是否在门店等待一小时却未能办好业务而和店员吵架,是否有过在食堂排队很久最后被告知菜卖完了的经历。如果以上这些都不够刻骨铭心的话,您是否曾经拖着病体大清早起床挂号,抑或数九寒天忍饥挨饿只为买一张火车票回家。
技术改变生活,移动互联网时代,以上这些需求都已经可以足不出户在手机上完成,而问答机器人在其中扮演了关键角色。
作具备业内领先 AI 能力的服务营销一体化解决方案专家,网易七鱼已经在电商、教育、制造、汽车等各行业落地,助力企业服务的数字化转型。有幸服务千家万户,提升生活品质,创造美好生活,对这个时代我们充满感激。如果您的企业仍然困扰于上述痛点,不妨和七鱼交个朋友,我们一起共同努力,拥抱星辰大海!