本案例数据集地址(百度网盘):链接:https://pan.baidu.com/s/1FsEcr3lanXYbYLxGELtJZw 提取码:5nvw (此链接永久有效)
或扫描下方二维码获取:

在本次博客中,我将利用Python数据分析工具来做一个某医院某年度的销售情况汇总。
项目运行环境:
| 操作系统 | Windows 10 64位 |
| Python | 3.7.0 |
| 开发工具 | Pycharm(ipython) |
数据分析的基本过程主要分为两方面:
一、数据分析的目的
一方面是发现问题,并且找到问题的根源,最终通过切实可行的办法解决存在的问题;另一方面,提取有用信息和形成结论而对数据加以详细研究和概括,对以往的数据分析,总结发展趋势,为网络营销决策提供支持。
二 、数据分析基本过程
数据分析基本过程包括:获取数据、数据清洗、构建模型、数据可视化、得出结论。
1.获取数据
注:本次项目使用的数据请在前面链接自行下载
导包
|
import os import pandas as pd import matplotlib.pyplot as plt |
| os.chdir(r'填写你的数据所在路径') #比如:os.chdir(r'F:360Downloads朝阳医院') |
|
dataDF=pd.read_ecxel('文件名(记得带文件后缀名)') #比如:dataDF=pd.read_excel('朝阳医院2018年销售数据.xlsx') |
| dataDF.head() #默认查看前5行 |

接下来查看数据的下列信息:shape(形状)、index(索引)、columns(列名)、count(总数)
| dataDF.shape #查看数据的结构(行、列数) |

| dataDF.index #查看数据的索引 |

| dataDF.columns #查看数据的列名 |

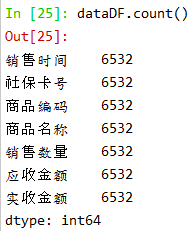
| dataDF.count() #查看数据的总数 |

| dataDF.describe() #查看数据的数值详细信息 |

|
通过以上的数据可以看出: 总共有6578行7列数据,但是“购药时间”和“社保卡号”这两列只有6576个数据,而“商品编码”一直到“实收金额”这些列都是只有6577个数据。这就意味着数据中存在缺失值,可以推断出数据中存在一行缺失值。 此外“购药时间”和“社保卡号”这两列都各自存在一个缺失数据,这些缺失数据在后面步骤中需要进一步处理。 而且数据中存在负数,这将在后面也需要进一步处理。 |
2.数据清洗
数据清洗通常包括:选择子集、修改列名称、处理缺失值、处理异常值、转换数据类型、数据排序(为可视化做准备),在这里我们根据实验数据本身特征进行处理,过程如下:
选择子集:
| 在进行数据分析时,通常会遇到非常庞大的数据包,并且其中难免会有一些‘无用’的数据,以及和本次项目不相关的信息,这时就需要将其分开并按照需求选择,得到有价值的数据集来进行进一步分析,从而挖掘出我们需要的潜在信息。由于本次案例使用的数据集量小且简单,因此可以忽略这一步。 |
修改列名称:
| 在拿到的原始数据中,列名称和数据和其他列名之间可能会相似或者不能够‘见名知意’,导致给后续分析带来困难,为了避免此现象,我们可以根据需求调用rename()函数将列名重命名,比如中文名称(这里纯属个人习惯) |
| dataDF=dataDF.rename(columns={'购药时间':'销售时间'}) dataDF.head() |
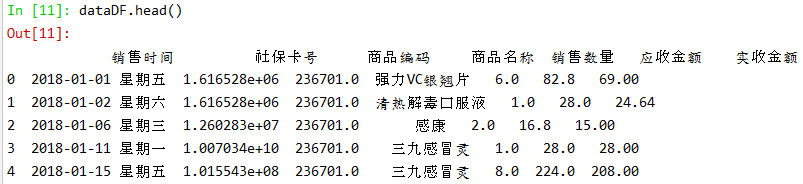
处理缺失值:
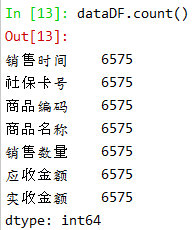
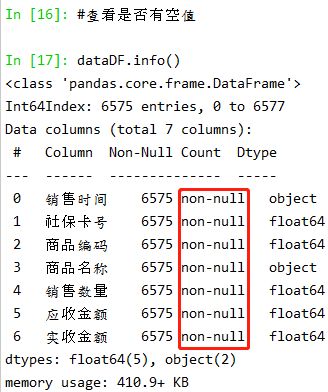
| 通过上面的dataDF.count()可以看出,数据的“购药时间”和“社保卡号”行数和其他数据不相等,证明肯定存在空值,为了不对后续的操作造成干扰,在这里需要进一步处理,通常处理方式有两种:第一,删除;第二,填充。在本次案例中,由于数据简单,我们采用第一种方式将含有空值的行删除,得到‘干净’数据,使用到的函数有dropna() |
| dataDF=dataDF.dropna(subset=['销售时间','社保卡号'],how='any') dataDF.count() |
处理异常值:
我们先来查看一下数据的当前信息:
| dataDF.describe() |
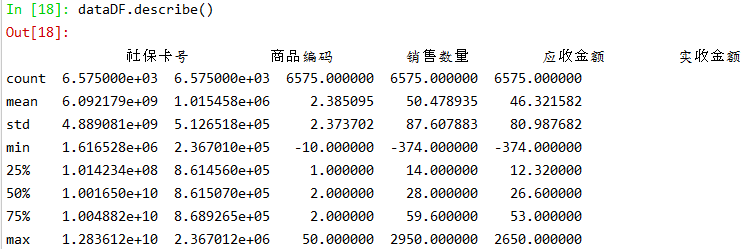
可以看出数据当中存在异常值(负值)。
现在我们删除负值所在的行
| pop=dataDF.loc[:,'销售数量']>0 |

| dataDF=dataDF.loc[pop,:] dataDF.describe() |

接下来再查看一下数据信息(行数)
转换数据类型:
我们先来查看一下数据的当前类型:

发现销售时间这一列并不是我们想要的datetime格式,因此需要转换,为后续分析做准备。这里使用到的函数有:astype()函数
在处理之前,原始数据如下图(发现‘销售时间’这一列存在星期*,显然这并不是我们需要的,接下来我们编写(分割)函数将其去除,具体操作如下):

下图是我编写的一个(分割)函数以及具体操作(此处方法很多,远远不止这一种)
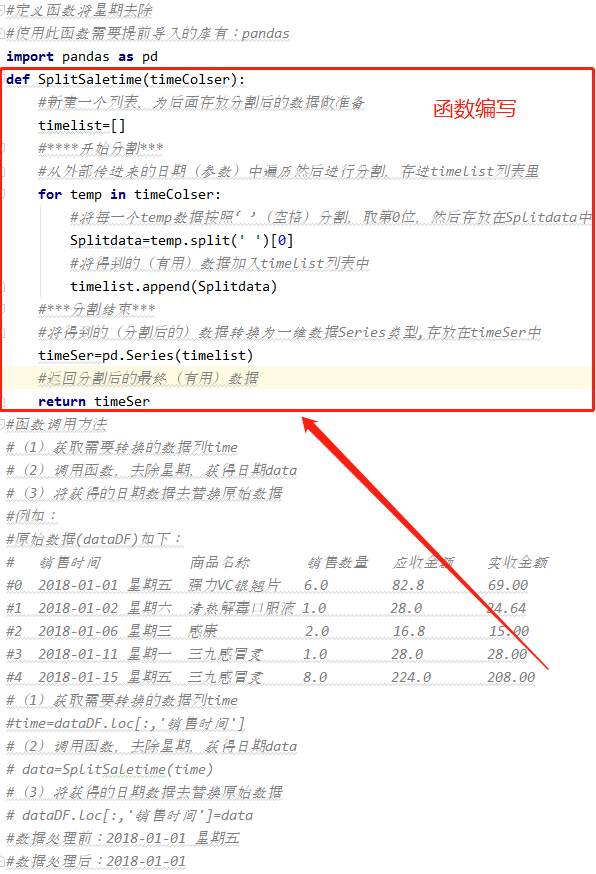
本案例操作方法如下:

调用函数,处理数据(具体过程见上图的‘函数调用方法’部分)
|
time=dataDF.loc[:,'销售时间'] data=SplitSaletime(time) dataDF.loc[:,'销售时间']=data |
处理后的数据(销售时间)如下:
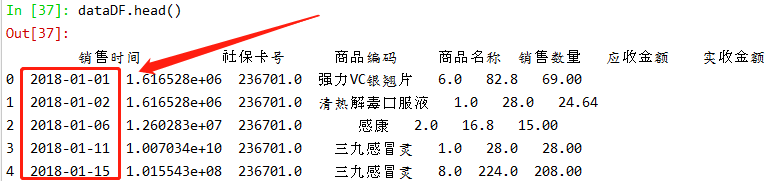
查看当前数据类型(如下图,发现销售时间列格式已经修改成功,接下来将其转换为datetime类型即可):

| dataDF.loc[:,'销售时间']=pd.to_datetime(dataDF.loc[:,'销售时间'],format='%Y-%m-%d',errors='coerce') |
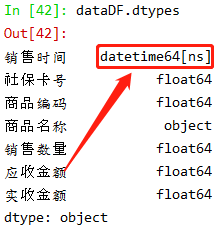
此时我们再来看数据(销售时间)类型,发现已经转换成功:
数据排序(重置索引):
接下来我们按照时间列进行升序排序
| dataDF=dataDF.sort_values(by=['销售时间'],ascending=True) #by='填写需要按照那一列来排序',ascending=True表示升序(False表示降序) |

然后重置索引
| dataDF=dataDF.reset_index(drop=True) |
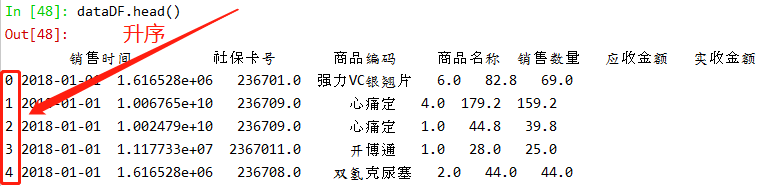
3.构建模型
| 数据准备就绪后,根据相关业务利用可视化工具实现图标制作,从而挖掘出数据背后的信息。 |
需求一:月均消费次数(月均消费次数 = 总消费次数/月份数)
第一步:计算总消费次数(为了便于统计,每张社保卡在当天的所有消费记录当做一次消费,因此首先需要对数据进行‘去重’操作,这里需要用到drop_duplicates()函数)
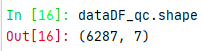
| dataDF_qc=dataDF.drop_duplicates(subset=['销售时间','社保卡号']) |
接着查看数据形状,看是否有变化:
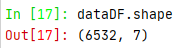
再看一下原始数据形状:
打印重复的行数:
| print(f'原始数据与去重后的数据行数相差:{dataDF.shape[0]-dataDF_qc.shape[0]}行。') |

计算总消费次数:
| Total_time=dataDF_qc.shape[0] |
结果如下:

第二步:计算月份数
按照销售时间升序排序,然后重置索引
| 升序排序 | dataDF_shengxu=dataDF_qc.sort_values(by=['销售时间'],ascending=True) |
| 重置索引 | dataDF_qc_resrt_index=dataDF_qc.reset_index(drop=True) |
索引:

计算销售时间范围:
| StartTime=dataDF_qc_resrt_index.loc[0,'销售时间'] |
| EndTime=dataDF_qc_resrt_index.loc[Total_time-1,'销售时间'] |


此时发现销售时间出现空值,因此这里我们删除空值所在行数据:
| dataDF_qc_resrt_index.dropna(subset=['销售时间'],inplace=True) |
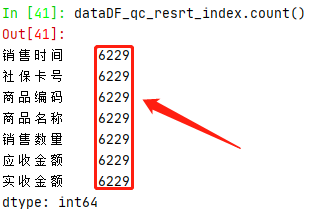
现在我们重复上述步骤获取开始和结束时间:
| StartTime=dataDF_qc_resrt_index.loc[0,'销售时间'] |
| EndTime=dataDF_qc_resrt_index.loc[Total_time-1,'销售时间'] |

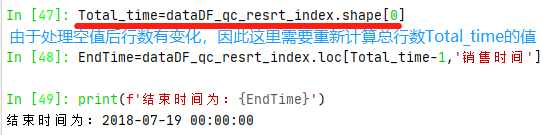
计算总天数:
| Day_time=(EndTime-StartTime).days |

计算月份数:
| Month_time=Day_time//30 #其中//为整除运算,每月按30天计 |

月均消费次数 = 总消费次数/月份数:
| Ave_time=Total_time//Month_time |

需求二:月均消费金额(月均消费次数 = 总消费金额/月份数)
第一步:计算总消费金额(这里用到sum()函数求和)
| Total_Money=data_new.loc[:,'实收金额'].sum() |

第二步:计算月均消费金额
| print(f'每月平均消费{(Total_Money//Month_time)}元。') |

需求三:每次购药平均消费金额(每次购药平均消费金额 = 总消费金额/总购药次数)
| print(f'每次购药平均消费金额为:{(Total_Money/Total_time)}元。') |

4.数据可视化
准备工作:
|
导入可视化包: import matplotlib.pyplot as plt 遇到数据中有中文的时候,一定要先设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] # 用黑体显示中文 |
首先将数据复制到一个新的变量,专门用作数据可视化
| Data_KSH=dataDF_qc_resrt_index |
需求一:查看每日消费金额
重置索引为‘销售时间’列:
| Data_KSH.index=Data_KSH['销售时间'] |

绘制图形:

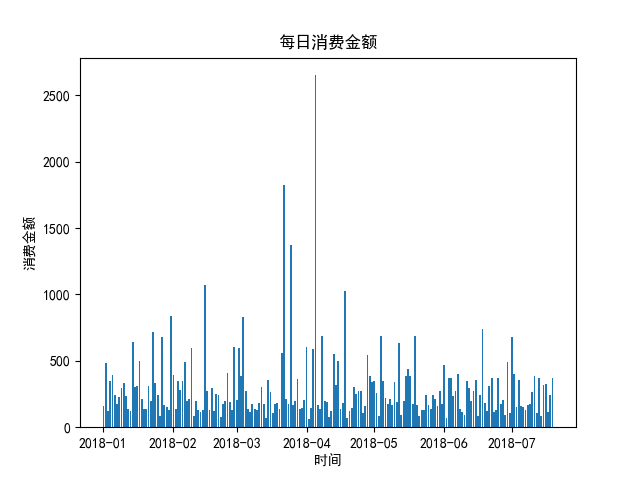
总结:日均 消费金额大部分集中在500元左右,并且上下波动不大。
需求二:查看每月销售金额
数据聚合(按照月份):
| Mon=Data_KSH.groupby(Data_KSH.index.month) |
利用sum()求和,计算每月销售金额:
| Mon_Money=Mon.sum() |
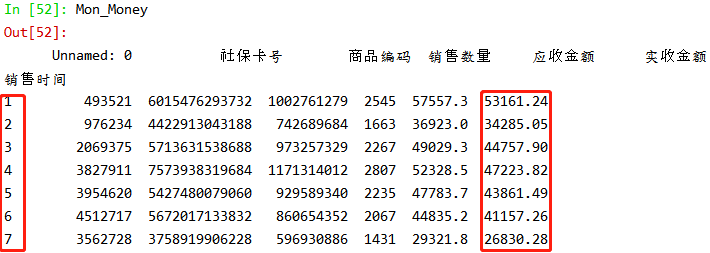
绘制图形:


总结:如图所示:3、4、5、6月份销售数据相对平稳均在4500元左右,其他月份波动较大。
需求三:查看销售量前十的药品
按照销售数量排序:
| Data_XSSL=Data_KSH.sort_values(by='销售数量') |

按照销售数量去重:
| Data_XSSL=Data_XSSL.drop_duplicates(subset=['销售数量']) |

提取前十行数据:
| Top_10=Data_XSSL.iloc[:10,:] |
查看前十行数据:
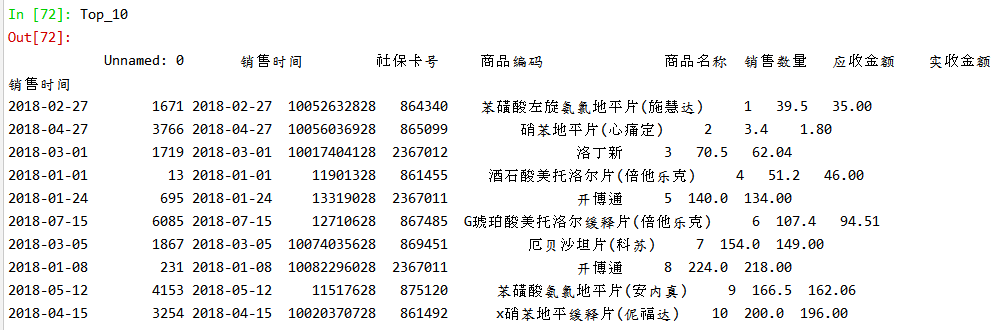
绘制图形:


总结:销售量前十的药品如图所示。
三、附件:本案例源代码
本案例数据集地址(百度网盘):链接:https://pan.baidu.com/s/1mStg3VcubipPx3EzQwMLEQ 提取码:5ua5 (此链接永久有效)
或者扫描下方二维码获取源代码:
