How to transform the day time images to night time ? A series of paper review and some thinkings about this point.
Unsupervised Holistic Image Generation from Key Local Patches
2017-07-20 14:34:27
无监督的进行基于关键局部 patch 的图像生成,这个算是和 “传统”的 GAN 稍微不同的地方。这种方法需要让网络自己能够学习到关于所想生成物体的“空间结构”信息,否则生成的图像可能并不是很有意义。
首先,输入 patch 的空间安排需要学习出来,但是这些数据并没有类似的结构信息;
其次,我们想在生成图像的过程中,保存下来这个 key local patches ;
最后,产生的图像应该尽可能的看起来像是目标的类别。
由于输入是有多个 patch,那么就需要多个能够感知这些图像的 encoder net 来进行编码。所以本文设计了下图所示的 endcode 网络结构:

当然作者也考虑了其他的结构,不过,最终还是选择了这一种。其实就是用多个网络来感知多个 patch,然后将这些信息 sum 在一起,得到最终的编码向量 E。
总体的网络结构如图所示:

那么,可以看出:作者使用了多个 loss 来完成整个网络的训练,即:spatial loss, appearance loss 以及 real-fake discriminative.
为了得到那么多的训练数据,作者先用 proposal 的产生方法,产生一些 key patches,并且根据这些位置生成一些 GT binary mask。然后利用 Siamese network 对这多个 patch 进行编码,然后进行 sum,得到统一的 bottle layer E,然后紧接着用 Mask prediction (U-network) 来进行反卷积生成所需要的 binary mask。与此同时,我们用另一个反卷积网络(double U-network)来进行总体图像的产生。该图像还被用来和 mask 进行点乘操作,然后进行 appearance Loss 的计算。最终,该产生的图像被送到判别器当中,进行真伪的判别。
所用到的三个损失函数分别为:
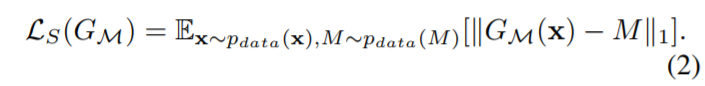

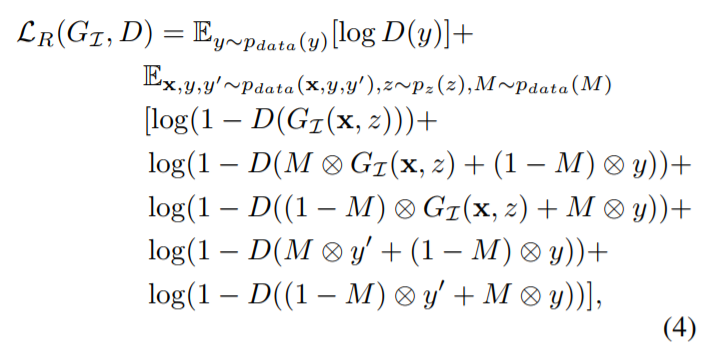
实验效果:

Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis
2017-07-20 22:45:08
Paper: http://openaccess.thecvf.com/content_ICCV_2017/papers/Huang_Beyond_Face_Rotation_ICCV_2017_paper.pdf
Official Tensorflow implementation: https://github.com/HRLTY/TP-GAN
Unofficial PyTorch Implementation: https://github.com/iwtw/pytorch-TP-GAN
本文的充分的利用了人脸姿势转换的相关领域知识,作为先验信息,进行整个 TP-GAN 网络的设计。如:对称性损失函数的设计,关于人头整体结构的建模和局部信息的捕捉,这些都是非常有用的 domain knowledge。其中,在进行姿态转换的过程中,如何保持转换后的图像仍旧是同一个人,这也是非常重要的。
最直观的还是来算法的网络设计:

本文主要是两个网络结构合成的。一个是 global 的网络,另个是 local 的网络。
关于 local 的网络,是四个部分构成的,即:两个眼镜,鼻子 和 嘴巴部分。分别将这四个部分编码,然后解码为对应的正面照。
然后总体对整幅图像进行 encoder-decoder 操作,相当于重构出一幅 正脸的图像,然后将这两个网络进行组合,就可以得到总体的输出。
其实 generator 就主要干这个事情,剩下的交给 discriminator 来做,即:判断是否为真。
另外的损失函数就是:保持对称的损失函数,保持个体不变的损失函数,以及 pixel-wise 的 loss。
Unpaired Image to Image Translation using Cycle-Consistent Adversarial Networks
UC Beerkeley
本文借助 Dualing Learning,不利用 paired image 进行图像到图像的转换。在这个过程中考虑到了 X->Y->X' 应该约等于 X 的假设,应用到图像的转换中。
先来看看其整个流程示意图:

其中,有两个主要的传播过程:前向循环一致性, 反向循环一致性。
而所谓的前向传播一致性,可以看出:

就是将 X 作为起点,经过 generator 可以得到转换后的 Y' ,然后再利用 generator 进行转换,以得到模拟的起点 X' 。根据 dualing learning 的理论,这种转换后得到的图像和初始的图像应该是尽可能保持一致的。另一个过程也是类似的思路:

对应的一致性损失函数可以写为:

除了这些一致性的损失函数之外,其实还是有 adversarial loss 的。

所以总体上的优化目标为:

那么,我们的网络定义中一定要有 两个 generator 以及 两个 discriminator,才能完成整个闭合的 loop。