ATOM: Accurate Tracking by Overlap Maximization
2019-03-12 23:48:42
Paper:https://arxiv.org/pdf/1811.07628
Code: https://github.com/visionml/pytracking
1. Background and Motivation:
这篇文章的主要动机是从改善重合度的角度,来提升跟踪的总体性能。因为现有的算法,大部分都在强调,怎么做才能跟的上,而很少有人专门研究:“怎么跟踪,才能跟踪的好?”这里的好,不但是指能时刻跟住目标,而且所预测的 BBox 要能很好的框柱目标物体。所以,这里就要谈到重合度的问题了,即文章标题所体现的 “Overlap Maximization”。文章主要是受到 IoU Net 的启发,有兴趣的可以先去看下这个物体检测的文章。
作者将跟踪任务主要分为两种:a classification task and an estimation task。前者是粗略的将提取的图像块分类为前景和背景,得到一个粗略的目标位置;而后者是通过一个 BBox 来预测目标的状态。最新的一个顶尖跟踪算法,也是依赖于模型中的分类成分来进行目标预测。但是这种策略是有很大局限性的,因为 bounding box estimation 是一个非常具有挑战性的任务,需要对目标的姿态有高层的理解,如下图所示:

而本文尝试解决 target classification 和 estimation in visual tracking 存在的鸿沟。作者引入一种新颖的多任务跟踪框架,主要包括两个成分,用于 target estimation 和 classification。本文的跟踪示意图如下图所示。基于 IoU-Net,作者训练一个目标预测模块(Target estimation module)来预测 target 和 estimated BBox 之间的 IoU overlap,即:the Jaccard Index。但是,由于原本的 IoU-Net 是class-specific,并不能直接拿过来用于 tracking,所以作者提出一个新的框架,将 target-specific information 融合到 IoU 的预测中。作者用过引入一个 modulation-based network component,将 target appearance 结合到 reference image 中,以得到特定目标的重合度预测(the target-specific IoU estimates)。酱紫,就可以让作者的目标预测模块在大型数据集上,进行 offline 的训练。在跟踪的过程中,目标 BBox 就是简单的最大化每一帧预测的 IoU overlap。
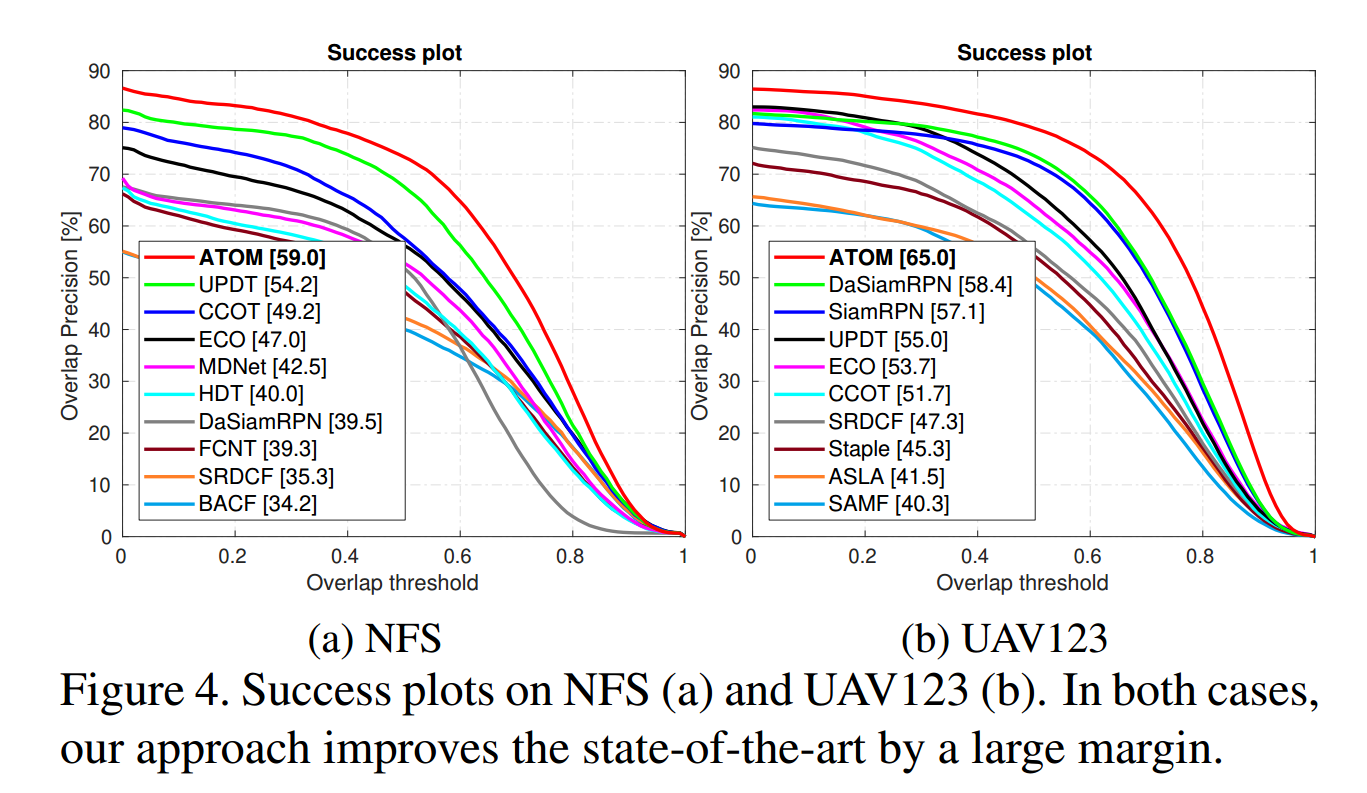
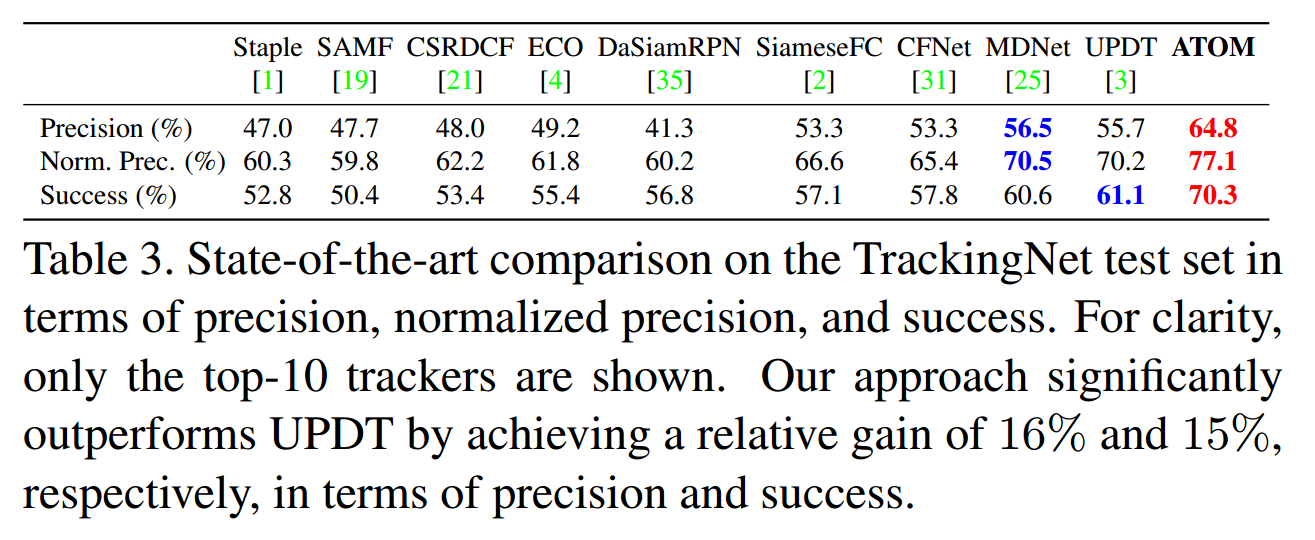
此外,作者还设计了一个 classification module,并且是 online 训练的,提供了较高的鲁棒性。作者最终的跟踪过程就是:target classification,estimation,and model update。作者在四个数据集上取得了极大地提升,包括:NFS, UAV123, TrackingNet and VOT-2018。
2. Overview of ATOM:
该模型主要包括两个部分,一个是 target estimation,另一个是 target classification。
对于 target estimation,就是刚刚提到的 IoU-predictor,主要包括四个输入:
1). 当前视频帧的 feature;
2). 当前视频帧预测的 bounding box;
3). reference image 的 feature;
4). reference image 的目标 BBox;
然后,该网络输出的是:当前视频帧 BBox 的 IoU 预测得分。
第二个网络是用于 target classification,是 online 训练的。就是用于对提取的 proposal 进行打分,进行前景和背景的区分。但是,作者并没有采用常规的 SGD optimizator,而是用了基于 Conjugate Gradient and Gauss-Newton 的优化策略。原因呢?就是可以确保 fast online training。
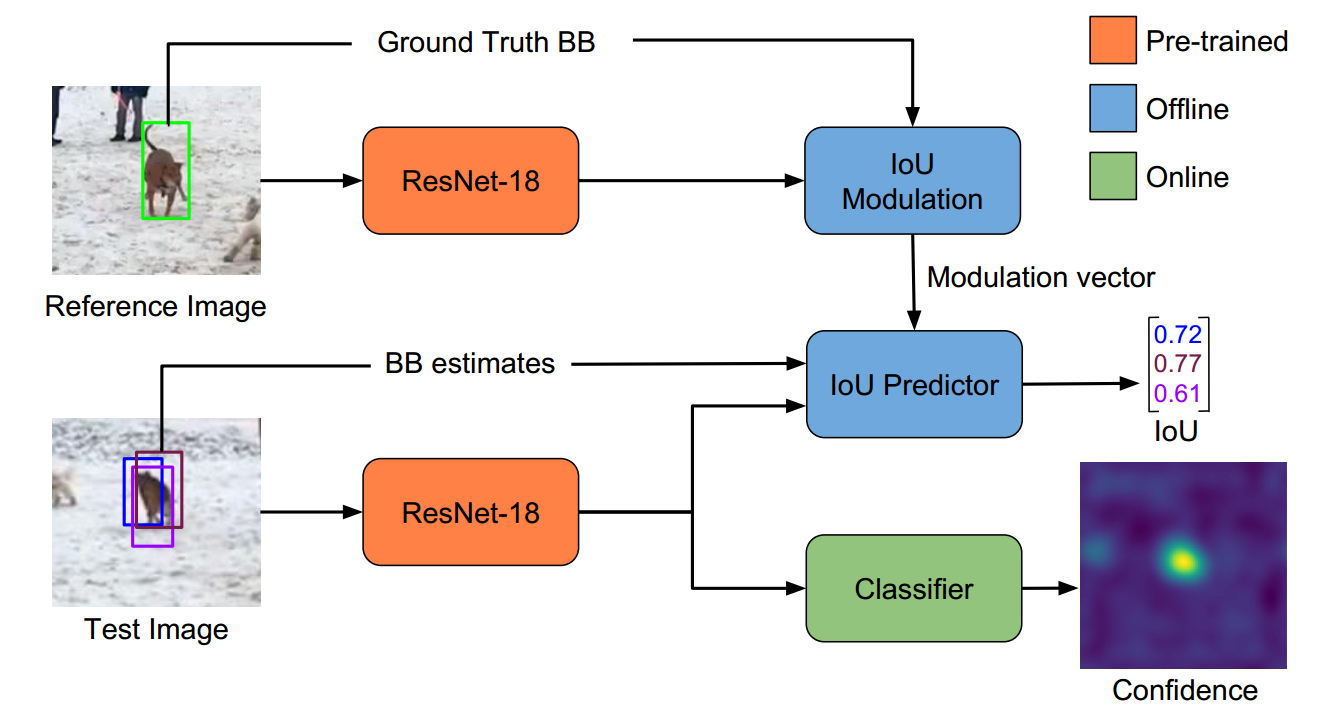
3. The Details of ATOM:
3.1 Target Estimation by Overlap Maximization
IoU-Net 介绍:

网络结构:
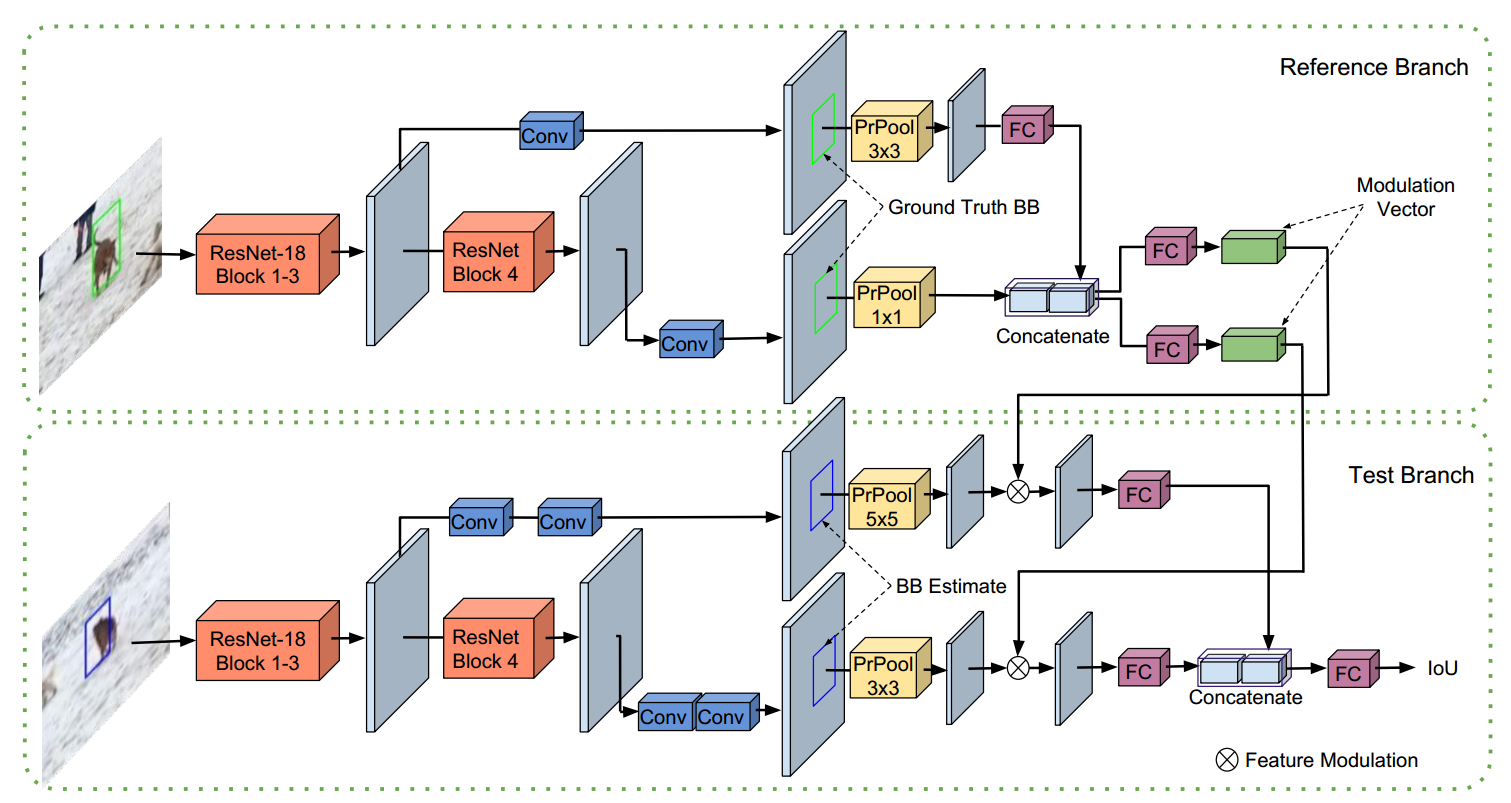
如上图所示,作者想要设计一种 IoU-Net 用于跟踪问题,想要做到 target-specific IoU prediction,由于 IoU 预测任务是更加高层的,所以,在单张图像上进行训练或者微调是不可行的。所以,作者认为目标预测网络需要离线训练,以学习一个 general 的表达进行 IoU prediction。作者刚开始的实验表明:简单的将 reference image 和 current-frame features 进行结合的效果并不好。作者也发现:Siamese 的网络结构也无法得到最好的效果。在本文中,在给定单张参考图像的条件下,作者就提出一种 modulation-based network architecture 来预测任意一个物体的 IoU,如上述流程图所示。
该网络包含两个分支,这两个分支都是依赖于 ResNet-18 Block 3 和 Block 4 的feature 作为输入。
The reference branch 将参考图像的 features x0 和 target BBox 标注 B0 作为输入,其返回一个 modulation vector c(x0, B0)。具体网络结构就是:一个卷积层,然后接一个 PrPool 和 一个 fc 层。
The current image,即我们要预测目标包围盒的状态,是在 test branch 进行的。其首先将 feature map x 输入到两个卷积层,然后经过 PrPooling layer,得到的结果是 z(x, B)。这样子得到的 target-specific representation,有效的结合了 reference appearance information。然后将该特征输入到 IoU predictor module g,这个是由三个全连接层构成的。
![]()
为了训练这个网络,我们最小化公式(1)的预测误差。在跟踪的过程中,我们最大化该 IoU 来预测目标的状态。
3.2 Target Classification by Fast Online Learning:
有了 proposal,剩下的就是对这些样本进行前景和背景的判别了。作者的目标分类模型是一个 2层的全卷机层,定义为:
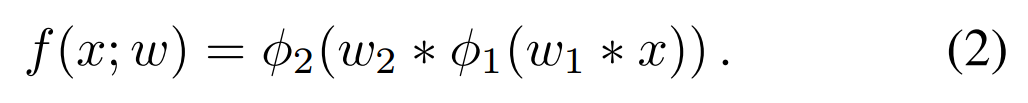
此处,x 是 backbone feature map,w 是网络参数,$phi$ 是激活函数,* 是标准的多通道卷积。受到最近一些判别性相关滤波方法的启发,作者将相似性学习的目标定义成与 L2 分类误差类似的形式:
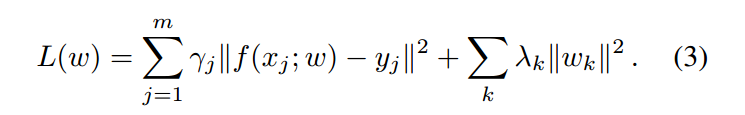
最小化上述公式(3)的一种比较粗暴的方式,就是采用 标准的 SGD 的方法。但是这些方法缺对 online learning 的方式不够友善,因为其收敛速度很慢。所以作者自己提出了一种新的优化方法,进行更加高效的优化,具体细节见原文。关于这一块,等我仔细研读后,再对博文进行更新。

实验部分:
实验在多个数据集上都取得了顶尖的效果,而且提升不是一星半点。

==