最近发现有些同学并不太了解大数据开发工程师这个职位,自己转大数据开发也已经三年了,所以想简单介绍一下什么是大数据开发工程师,当前互联网公司的数据开发到底是什么样子的?和一般的java或者php工程师在工作上有什么区别?
声明:本文仅代表个人观点,有不同意见欢迎提出。另外本文对大数据开发工程师没什么参考价值~仅是我各人对这个职位做一个介绍。
1 先说我认为什么不是大数据开发
仅使用数据库(关系型mysql,sqlserver,oracle等 非关系型 mongo redis等),尽管数据量达到千万级别,亿级别不是大数据开发。
从业务系统的数据库中查询数据然后产出报表不是大数据开。
端上(页面,h5,手机native)埋点上报数据记录到数据库中不是大数据开发。
2 我认为什么是大数据开发
大数据开发需要的技能
到智联上搜了一下大数据开发工程师 这个职位,随便点了几个职位,截图如下:
 

 

所以说首先,现在互联网公司所指的大数据开发用到的工具是:hadoop,hive,hbase,spark,kafka等.
大数据开发做的事情
精简到一个词语就是:统计
精简到两类指标就是:PV和UV
精简到一句话就是:统计各种指标的PV和UV.
PC互联网时代,各门户网站(比如:新浪,网易,搜狐)关注的是各自网站今天被打开了几次(pv),今天有多少人(uv)访问了网站.更复杂一点的比如:
页面上某个按钮或者某个连接有多少人点击了几次.
某个页面上的热力图(点击地方越多,图上颜色越重)
移动互联网时代,手机应用被用户打开的次数和人数也是大家关注的重点,但是除此之外还多出了许多其他非常重要的数据,由于手机屏幕的限制,信息流成为了移动时代的主流.
各大门户网站非常关注自己的新闻客户端中: 在信息流中曝光了多少篇文章, 其中有多少篇文章被用户点击了.每篇文章阅读了长时间,因为用户点击的文章越多,使用客户端的时间越长,各公司的广告收入才越高,所以各公司想方设法推荐用户喜欢的内容~
如何做这些事情
因为网站的浏览行为,手机客户端中文章的曝光或者点击这些数据非常大,基本以亿为单位起,
所以传统的把统计信息放到数据库中的方式已经不能完成这项统计工作.(例如,wordpress博客中,用户每阅读一篇文章,mysql中就会更新这篇文章的阅读次数+1)

所以大数据是通过日志来统计这些指标.
比如:后台服务的日志,例如:apache,tomcat,weblogic,nginx日志
例如下图,我的个人网站apache服务的access日志
日志的url字段中 以 /年份(红色部分)开头行数就是这个网站文章页被访问的次数
以/category(蓝色部分)开头的行数就是这个网站分类目录被访问的次数.
 

当然我的这份日志中是统计不了用户数的,因为用户数的统计需要在每条日志上记录当前用户的唯一标识,然后再做个去重,去重后的数量就是用户数.但是这里没有上报用户的唯一标识.
那如何统计人数呢, 一般互联网公司会自己在页面或者客户端上生成一个用户的唯一标识,然后主动上报到自己的日志服务器上.
流程如下:
- 页面,客户端埋点(按照指定的字段格式,在特定的时间把数据发送出去)
- 日志接收服务器,通常是
nginx集群专门用来接收日志.
例如我的个人网站中,我用的百度统计来统计网站的用户数,用户只要打开我的网站就会有如下信息发送到百度的服务器上:
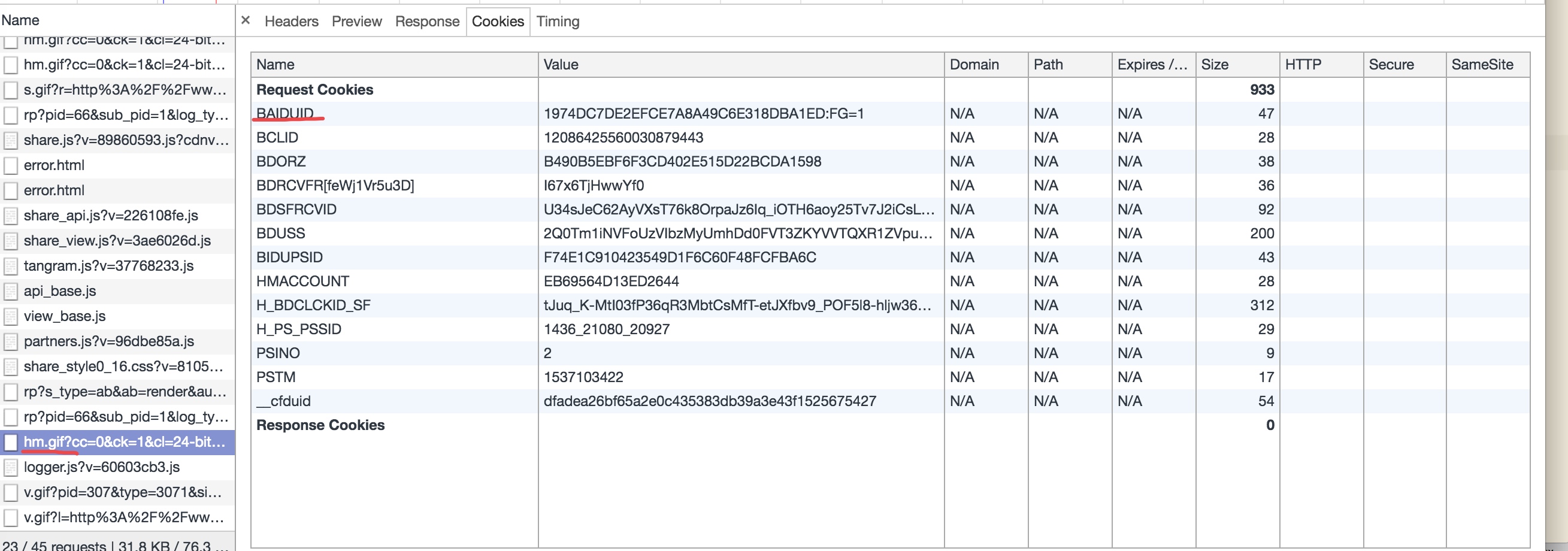 

其中:hm.gif 是一个大小为0的图片,只是为了把这条url记录打印到nginx服务的日志中.
我猜测BAIDUID这个字段是百度用来帮我统计人数的.
上面主要说的是日志的产生(端上产生,服务端接收), 大数据开发工程师的工作就是从接收到的日志中计算出来需要的指标,并且展示在页面上,方便分析师查看
(因为接收到的日志格式不整齐还有一些垃圾数据,所以需要对日志进行清洗(etl操作),再处理成各种数据仓库表,方便后续统计.)
例如:一行access日志:
218.69.234.153 - - [23/Sep/2018:21:08:00 +0800] "GET /2018/09/python-scrapy-%e7%99%bb%e5%bd%95%e7%9f%a5%e4%b9%8e%e8%bf%87%e7%a8%8b/ HTTP/1.1" 200 12466
处理之后:为四列(ip, 时间, http状态, url),更方便统计.
218.69.234.153 2018-09-23 21:08:00 200 /2018/09/python-scrapy-%e7%99%bb%e5%bd%95%e7%9f%a5%e4%b9%8e%e8%bf%87%e7%a8%8b/
然后 按照某种格式计算的行数就是次数.
按照某种规则,取出某个字段,用这个字段排重,就是UV(如果这个字段是用户唯一标识,就是人数)
主要难点在于:
- 日志量太大(一般大点的互联网公司,一个业务线每天的日志都有几个t,再大些的每天几十t,几百t也不奇怪),需要掌握大数据相关技术例如前问题到的hadoop,hive等
- 数据的及时性,从离线计算来说,一般每天零点,前一天的日志都接收完毕,开始计算前一天的数据,几点能计算完毕? 要看各个公司各自的要求.
- 数据的准确性.(这是重中之重,大数据开发的工作就是统计,统计的数据如果不准....)
- 如果是实时计算,需要掌握实时相关技术.例如:每5分钟网站的在线人数.
- 监控监控监控:监控任务是否失败,数据是否产出,产出的数据是否异常.
- 容灾容灾容灾:如果任务失败如何补救.比如实时任务,由于某种原因13:00到14:00的数据没有,如何把数据补回来.
大数据开发和一般业务开发的对比
在转做大数据开发之前,一直在用java作业务系统: 例如 hr系统(考勤,薪资等).收费系统.
谈谈我个人对业务系统开发和大数据开发的理解:
业务系统:
一句话:对数据库的各种增删改查操作.
重点难点在于:
- 对复杂业务的理解上(比如计算工资:基本工资,五险一金,全勤奖,高温补贴,报销,奖金,加班费.....等等都需要计算).
- 线上服务的稳定,比如
facebook,淘宝等网站高并发的压力下维持网站正常运行.
大数据开发
一句话:对字符串的各种算数.
重难点在于:
- 数据的及时性.例如实时数据中,想知道
12:00~12:10这10分钟的用户数,如果这个数据在晚上20点才计算完成,那就没什么意义了.再比如,大家应该都有体验过:再手机上刷新闻的时候,你点了某一篇文章,再继续刷新闻,后面很快会出来不少和前面点击的那篇文章类似的文章.这就是根据你的点击给你及时推荐你有更大可能点的东西. - 数据的准确性.这个重要性不言而喻.
- 数据的稳定性和容灾.
仅仅分享个人的一些小看法,虽不全面也不系统,但是能够让未接触过的同学了解一些大数据开发吧~欢迎留言.