1.广播变量
1.1. Spark提供的Broadcast Variable,是只读的,并且在每个节点上只会有一份副本,而不会为每个task都拷贝一份副本
1.2.它的最大作用,就是减少变量到各个节点的网络传输消耗,以及各个节点上的内存消耗
1.3.spark自己内部也是用了高效的广播栓发来减少网络消耗
val factorbroadcast=sc.broadcast(factor)
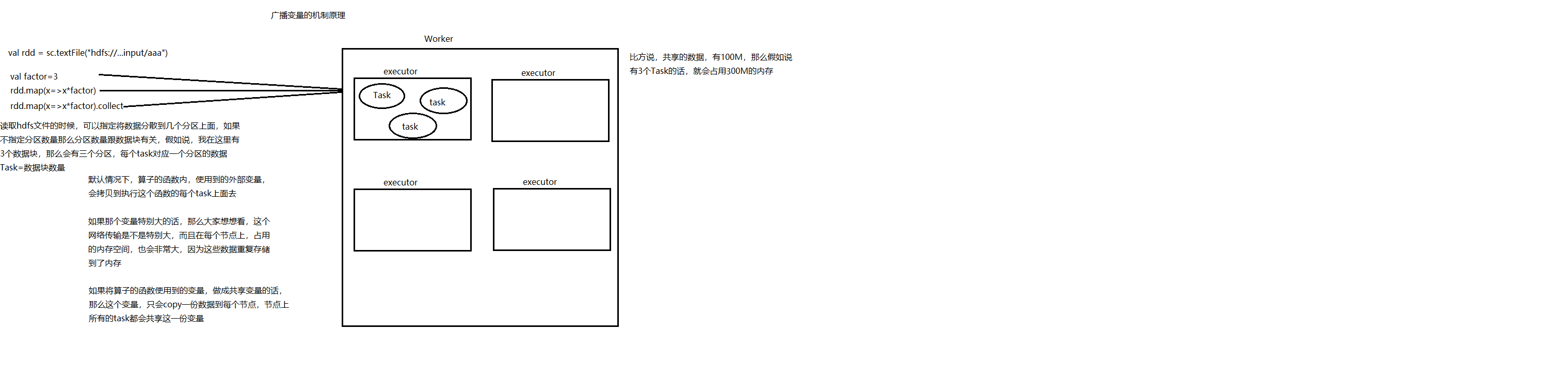
解读图:
2.1.val rdd=sc.textFile("hdfs://..input/aaa")
读取hdfs文件的时候,可以指定将数据分散到几个分区上面。如果不指定分区数量那么分区数量跟数据块有关
2.2.val factor=3
加入说,我在这里有三个数据块,那么会有三个分区,每个task对应一个分区的数据Task=数据块的数量
2.3.默认情况下,算子的函数内,使用到的外部变量,会拷贝到执行这个函数的task上面去。
2.4.如果那个广播变量特别大的话,这个网络传输也会特别大,而且在每个节点上,占用的内存空间,也会非常到,因为这些数据重复存储到内存
2.5.如果将算子的函数使用到的变量,做到共享变量的话,那么这个变量,只会copy一份数据到每个节点,节点上的所有task都会动向这一份变量
2.缓存
cache既不是tranformation算子也不是action算子
总结:如果内存放不下缓存的数据,那么多余的数据也不会缓存,没有缓存的数据在被使用的时候,需要再次计算
需要注意:
1.缓存的数据不能太大,尽可能缓存需要的数据
2.如果数据只是被使用一簇,那么不要进行缓存,因为缓存后只使用一次的话,性能会降低
3.如果使用完缓存以后,需要及时释放:radd.unperisist(true),否则会始终被占用
3.RDD的Checkpoint(检查点)机制:容错机制
1.检查点(本质是通过RDD写入disk左检查带你)是为了通过lineage(血统)做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销
2.设置checkpoint的目录,可以是本地的文件夹、也可以是HDFS,一般是在具有容错能力,高可靠的文件系统上(比如HDFS, S3等)设置一个检查点路径,用于保存检查点数据
4.访问数据库
//写入mysql result5.foreachPartition(filter=>{
//创建链接 val conn= DriverManager.getConnection( "jdbc:mysql://192.168.186.0:3306/test1?serverTimezone=Asia/Shanghai", "root","123456") filter.foreach(tp=>{
//获取sql对象 val ps=conn.prepareStatement("insert into suibian values(?,?)")
//添加字段 ps.setString(1,tp._1) ps.setInt(2,tp._2)
//更新 ps.executeUpdate()
//关流 ps.close() }) conn.close() })
思考题:
1:SparkContext是在那端生成的?
Driver
2:DAG是在那端构建的?
Driver
3:RDD是在那一端生成的?RDD的分区是在哪一端?
Driver
4:广播变量在那一端进行广播?
Driver
5:要广播的数据应该在那一端创建好再广播?
Driver
6:调用RDD的算子(Tranformation和Action)再那端创建?
Driver
7:RDD再调用Tranformation和Action时需要传入函数,传入的函数是在那一端执行了函数的业务逻辑?
Exceutor
8:自定义分区器这个类实在那一端被实例化?
Driver
9:分区器中的getpartition是在那一端被调用?
Executor端的Task中被执行
10:Task是在那一端生成的?
Driver端生成Task,对Task进行序列化,通过网络发送,Executor接收到Task以后,需要进行反序列化,实现了一个Runable接口的实现类进行包装,丢到线程池进行执行
11:Dag是在那一端构建好并被切分成一个或者多个stage
Driver
12:Dag是哪个类完成的切分Stage的功能?
DAGScheduler
13:DagScheduler将切分好的Stage以什么样的形式给TaskSceduler
TaskSet