[论文阅读笔记] Community-oriented attributed network embedding
本文结构
- 解决问题
- 主要贡献
- 算法原理
- 参考文献
(1) 解决问题
大多数现有方法在网络表征过程仅仅保留了节点的局部结构特征,忽略了他们的社区信息和丰富的属性信息。
(2) 主要贡献
Contribution 1: 提出了一个新颖的属性网络表征方法(COANE),引入主题模型LDA生成节点社区信息,指导随机游走捕获网络中的社区信息。
Contribution 2: 设计了一个面向社区的随机游走策略——引入了社区边缘来自适应地控制随机游走的范围,这解决了基于随机游走的方法在稠密网络中不能采样有效的游走序列的问题。
(3) 算法原理
首先简要介绍算法中使用来生成节点社区信息的LDA模型(具体介绍请参考其他资料或者看原始论文)。LDA是一个迭代的算法,通过吉布斯采样以统计频次的方式来估计以下两个概率分布(需要预先给定社区数)。
- 给定社区c,其中节点v在社区c中的概率
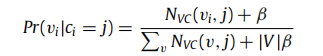
- 给定节点序列s,从中选择一个节点是属于社区c的概率)
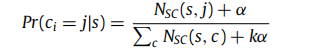
它首先给序列s中的每个节点vi随机分配一个社区ci。基于采样的序列,每个节点都被遍历,并且它的社区也基于以下概率被不断更新,直到LDA模型参数收敛。
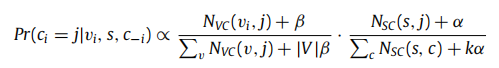
COANE算法主要包括以下三部分:
- 基于边缘的随机游走生成节点序列。
- 基于以上采样的节点序列,训练两个具有不同超参数的LDA模型分别来学习基于结构(简记为LDA-S)和基于文本属性(简记为LDA-X)的社区分布。
- 通过Skip-Gram模型来学习节点的向量表示。
接下来我们从算法伪代码开始一步步分析COANE算法的原理。
COANE算法伪代码如下图所示:

从上述伪代码我可以看出算法的输入为图、随机游走的参数、社区数(LDA主题模型的参数)、边缘出现时刻 Mm、边缘扩张速度Ms。输出为网络的嵌入矩阵。
那么基于基于边缘的随机游走是什么呢?怎么实现的呢? 首先,在早期我们通过随机游走生成节点序列并且输入LDA-S模型更新节点归属。在经过迭代几轮的节点社区归属更新之后,在属于不同社区的节点之间是会有边距的,如下图所示。不同社区之间的差距也是越来越明显的,即节点对于更可能社区的隶属度会逐渐增大,在图中表现为颜色加深。
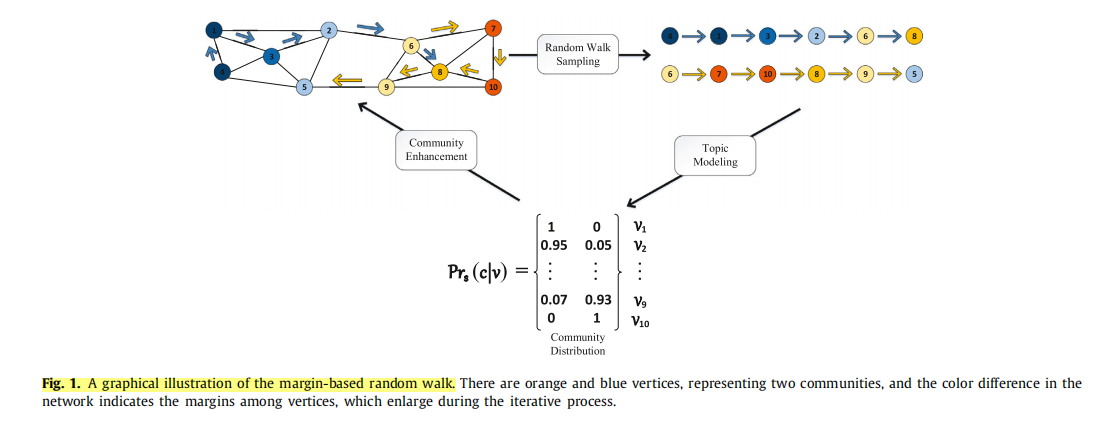
可以发现,不断迭代训练后的LDA模型是可以比较准确的发现社区结构的。因此基于LDA估计的社区归属概率,我们可以计算两个节点的在随机游走过程中的转移概率如下:
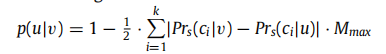
Mmax是一个由0不断增加到1的参数。当最大边距Mmax=0的时候,基于边距的随机游走就相当于传统的DeepWalk随机游走。随着Mmax的增加,节点跨社区访问的概率就减少。Mmax可以被认为是社区划分的置信度,这个置信度是不断增加的,因为经过不断训练LDA模型发现的社区结构是越来越明显的。
以上便是基于边缘的随机游走,边缘随着LDA模型的训练程度是越来越明显的,社区对于随机游走的约束也是越来越强的。
由伪代码第13,14行所示,每一轮随机游走的序列都会用来迭代更新两个LDA模型。
现在,将基于边缘的随机游走得到的节点序列输入Skip-Gram模型训练,我们可以得到基于节点拓扑结构和社区结构的节点向量表示了。那么怎么融合节点属性信息呢?
前面提到了一个基于文本属性建模的LDA模型(LDA模型本来就是处理文本主题分布概率的啊,这边我们只要采样文本的序列就行啦),同样,我们在图中进行基于边缘的随机游走,替换序列中的节点为其对应的文本属性,这些文本聚合在一起生成一个单独的文档,输入到基于文本的LDA模型中,。最终LDA模型可以生成文档的主题概率分布,论文直接把该分布当成节点的文本属性的表示向量,最终拼接合并到原始的基于结构的表示向量即可得到融合节点拓扑结构、社区信息以及属性信息的节点表示。
以上就是该网络表示学习算法的全部内容。
(4) 参考文献
Gao Y, Gong M, Xie Y, et al. Community-oriented attributed network embedding[J]. Knowledge-Based Systems, 2020, 193: 105418.