SNP命名
|
奶茶妹妹是谁,京东老板娘,咦?章泽天!没错! 国民老公是谁?万达少东家,王健林儿子,王思聪!恭喜你又答对了! 函数是谁?这不是数学上的名词吗?不对,是杨幂…… 人类这是有多么爱给人取外号,就连SNP的命名,也是各种各样,奇怪到令人发指(⊙o⊙) |
关于SNP位点的命名其实是很乱的,不同的组织机构命名不统一,大家在文献中也是根据自己的习惯命名。具体表现有以下几种形式:
1、 RS命名
RS 命名是目前最常用的SNP 命名法,NCBI 会对作者提交的SNP信息进行分类验证,然后会给出一个rs 号,命名方法是 rs+6/7 位阿拉伯数字,包括前后序列,位置信息,分布频率等,这也 GenBank 官方相对比较完善的命名体系。如果已知一个SNP 的 refSNP ID,那么就很容易在GenBank 的SNP 数据库中搜索到相关的信息和在基因组中的位置。
具体查询方法如下:
首先,打开http://www.ncbi.nlm.nih.gov/snp/,输入你要查询SNP的rs号,如下图:

其次,点击search,就会找到查询的SNP位点信息,如下图:
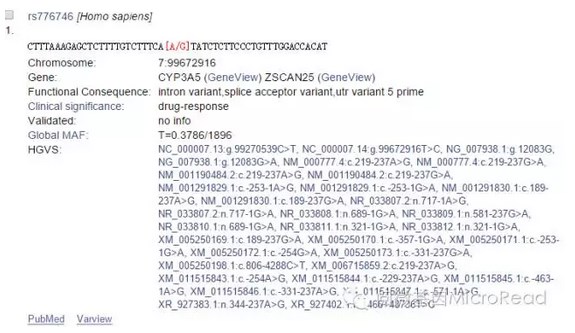
2、HGVS命名法
HGVS是Human Genome VariationSociety (人类基因组变异协会)的简称,是一个非政府的民间学术组织,其官方网址:http://www.hgvs.org/
HGVS命名法的规则是标出引用的核酸序列号(Reference Sequence,RefSeq)和SNP在该核酸序列中的位置,例如:
NC_000006.11:g.12292772G>T,其中红色的部分是核酸序列接受号,绿色的部分,G>T表示是该单核苷酸多态性位点在该核酸序列中的位置原始碱基是G,突变碱基是T。这样的命名方法有利于找出所在基因序列中的位置。
在NCBI网站上经常会看到“HGVS Names”和“refSNP ID”的字样,这两个都是用于命名SNP的常用方法。
3、突变信息之间加上位置信息
主要分为三种方式:
(1)突变信息之间+cDNA的位置,如 G2288T;但是由于基因信息的不断完善和补充, 很多原来的snp位置信息都在发生变化,像 G2288T这样的snp位置信息,只需把它当成一个名字即可,不要天真地对着2288这个位置去找snp。
(2)突变信息之间+DNA的位置,如 G2288T或 2288G>T;其实这是一种非常不正规的用HGVS Names标注SNP位置的方法。 很明显,由于缺少引用的核酸序列接受号,所以读者无法以这样的表示在GenBank中查到对应的信息。
(3)突变氨基酸信息之间+氨基酸位置,如Ser472Gly(S472G)。
4、惯用名称:
除了上述这些命名规则,还有一些在文献中经常出现的惯用名或按照频率顺序拟定的惯用名称,比如:CYP2D6*10、CYP2C9*3等,还有一些前面加个m,表示突变,如CYP2C19m2等。
例如成骨不全Ⅳ型家系COL1A1基因SNP:g.7601 G>A ; c.1678 G>A ; p.G560S,g应该是全基因组,c应该是cDNA,p应该是氨基酸,最后的G 、S是氨基酸缩写……等等。
总之形式百花齐放,百家争鸣,让人头晕!当然如果你有样本需要检测SNP位点,你可以直接将样本送到阅微基因,并提供SNP的名称、文献或序列皆可。
阅微基因提供专业的SNP服务,具有丰富的经验
可开展多种不同的检测方法、Taqman探针方法、SNaPshot方法、MassArray方法、直接测序法和KASP基因分型技术等。
阅微基因可根据客户的样本及位点的数量帮助客户选择合适的实验方案
针对有特殊结果的位点,我们会采用高效的DNA聚合酶,确保每个位点都有实验结果,进一步确保了客户数据的完整性。
每个项目的检测结果都能保证达到不低于95%的检出率。