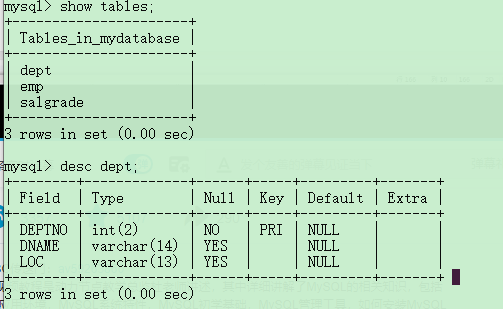
查询表结构:
desc 表名;
简单的查询语句(DQL)
语法格式:
1.查询部分字段
select字段名1,字段名2,字段名3..... from表名;
提示:
1.任何一条sql语句以“;"结尾。
2.sql语句不区分大小写
select 字段名*12 as 新字段名 from表名;(字段可以进行计算)
2.查询所有字段
select * from 表名;
2、条件查询:

语法格式:
select
字段,字段...
from
表名
where
条件;
执行顺序:先from。 然后where。 最后select
select * from emp where ename='smith';

select * from emp where sal>1000;

and 与 && 都可以 (&不要尝试)
select ename,sal from emp where sal between 1100 and 3000; // between. . .and.. .是闭区间
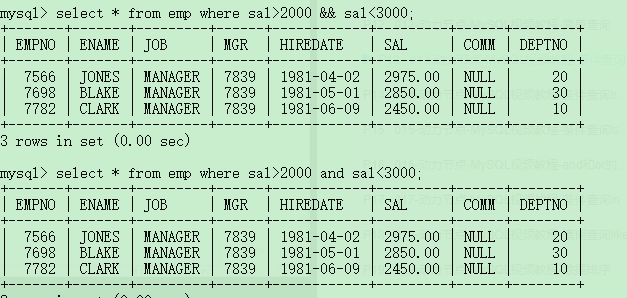
select ename from emp where comm is null;//找出没有补助的员工
select ename,sal,deptno from emp where deptno in(10,20);//找出部门编号为10与20的员工姓名及薪水
select ename from emp where ename like '%o%';//找出名字当中含有o的?

select ename from emp where ename like '_A%';//查询姓名第二个字是A的

排序(升序、降序)(order by)
【语法】:
select
字段1,字段2.....
f rom
表名
order by
字段/字段所在的列数;
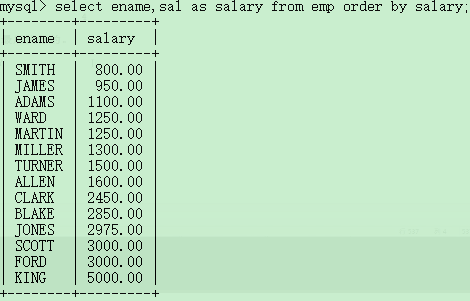
按照工资升序,找出员工名和薪资?
select ename,sal from emp order by sal;(默认升序)
select ename,sal from emp order by 6;//sal 在第六列
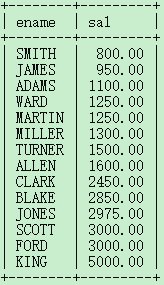
注意:默认是升序。怎么指定升序或者降序呢? asc表示升序,desc表示降序。
例:1. select ename,sal from emp order by sal desc;

2.按照工资的降序排列,当工资相同的时候再按照名字的升序排列。
select ename,sal from emp order by sal desc,ename asc;
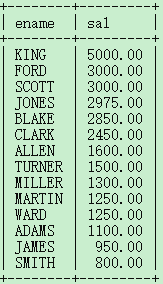
注意:越靠前的字段越能起到主导作用。只有当前面的字段无法完成排序的时候,才会启用后面的字段。
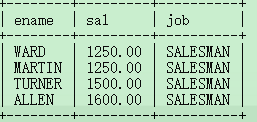
3.找出工作岗位是SALESMAN的员工,并且要求按照薪资的降序排列。
select ename,sal,job from emp where job='salesman' order by sal;
执行顺序:
select
字段1,字段2.... 3
from
tablename 1
where
条件 2
order by 字段 4
orderby是最后执行的。
验证:
分组函数?
count计数
sum求和
avg 平均值
max 最大值
min最小值
记住:所有的分组函数都是对"某一组"数据进行操作的。
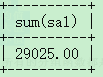
select sum(sal) from emp;
其余不再赘述,用法同上
分组函数还有另-一个名字 : 多行处理函数。
多行处理函数的特点:
输入多行,最终输出的结果是1行。
分组函数自动忽略NULL.
计算每个员工的年薪?
select ename, (sal+comm) *12 as yearsal from emp ;(写法不对,如果comm有空值)
重点:所有数据库都是这样规定的,只要有NULL参与的运算结果定是NULL。
使用ifnull函数:
select ename, (sal+ifnu11 (comm,0))*12 as yearsal from emp;
ifnull()空处理函数?
ifnull(可能为NULL的数据,被当做什么处理):属于单行处理函数。
select ename , ifnull (comm,0) as yearsal from emp ;
正确写法: select ename,(sal+ifnull(comm,0))*12 as yearsal from emp;
select ename,sal from emp where sal > avg(sal) ; //ERROR 1111 (HY000) : Invalid use of group function
思考以上的错误信息:无效的使用了分组函数?
原因: sQI语句当中有一个语法规则,分组函数不可直接使用在where子句当中。
怎么解释?
因为group by是在where执行之后才会执行的。
select 5
....
from 1
...
where 2
...
group by 3
...
having 4
....
order by 6
group by和having
group by :按照某个字 段或者某些字段进行分组。
having:having是对分组之后的数据进行再次过滤。
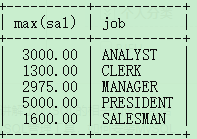
案例:找出每个工作岗位的最高薪资。
select max(sal),job from emp group by job;
注意:分组函数一般都会和groupby联合使用,这也是为什么它被称为分组函数的原因。
并且任何一个分组函数(count sum avg max min)都是在group by语句执行结束之后才会执行的。
当一条sql语句没有group by的话,整张表的数据会自成一组。
多个字段联合起来分组
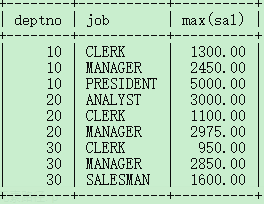
找出每个部门不同工作岗位的最高薪资.
select deptno,job,max(sal) from emp group by deptno,job;
having:
【例子】:
取得每个岗位的平均工资大于2000元
select job,sal from emp group by job having avg(sal)>2000;
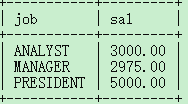
关于查询结果集的去重?//distinct关键字去除重复记录。且distinct只能出现在所有字段的最前面。
select distinct job from emp ;