https://zhuanlan.zhihu.com/p/45084771
分布式存储系统通过将数据分散到多台机器上来充分利用多台机器的资源提高系统的存储能力,每台机器上的数据存放都需要本地的单机存储系统,它是整个分布式存储系统的基础,为其提供保障。设计高性能、高可靠的分布式存储系统离不开高效、一致、稳定、可靠的本地存储系统。
ceph是目前业内比较普遍使用的开源分布式存储系统,实现有多种类型的本地存储系统;在较早的版本当中,ceph默认使用FileStore作为后端存储,但是由于FileStore存在一些缺陷,重新设计开发了BlueStore,并在L版本之后作为默认的后端存储。BlueStore的一些设计思想对于设计满足分布式存储系统需求的本地存储系统具有参考意义,因此我们将分多个章节对BlueStore的一些原理进行剖析,供读者进行参考和探讨。
在这一章中,我们将要了解BlueStore的诞生背景,以及它的一些设计思想。
为什么需要BlueStore
前面提到,BlueStore的诞生背景是由于FileStore存在的一些缺陷,这些缺陷具体是什么?
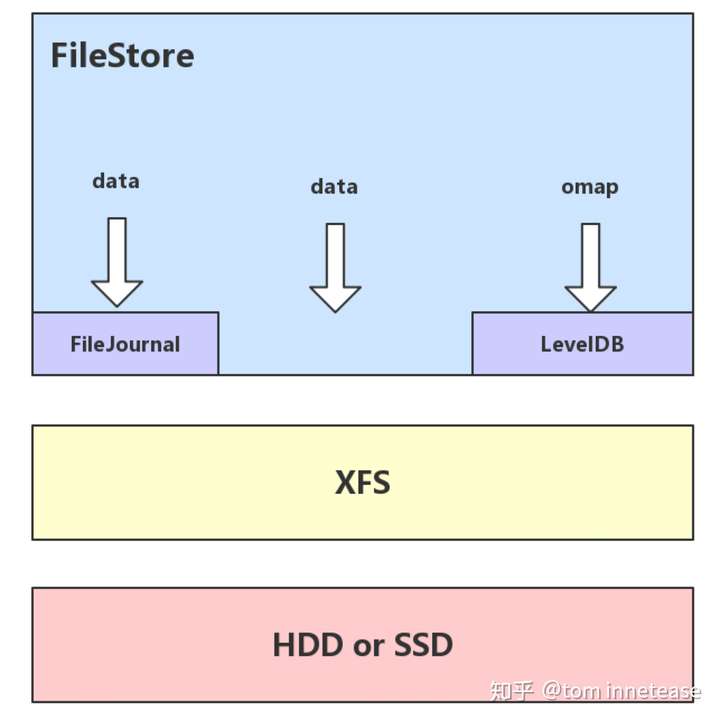
- IO放大
FileStore底层使用POSIX规范的文件系统接口,例如xfs、ext4、btrfs,然而这类文件系统本身不支持数据或元数据的事务操作接口(btrfs提供事务钩子的接口,但是测试过程中发现会导致系统宕机),而ceph对于数据写入要求十分严格,需要满足事务的特性(ACID);为此FileStore实现了FileJournal功能,所有的事务都需要先写到FileJournal中,之后才会写入对应的文件中,以此来保证事务的原子性,但是这导致了数据“双写”的问题,造成至少一半磁盘带宽的浪费。
此外xfs、ext4、btrfs这类文件系统本身存在一定的IO放大(即一次读写请求实际在低层磁盘发生的IO次数),再加上FileStore的日志双写,放大倍数成倍增加。
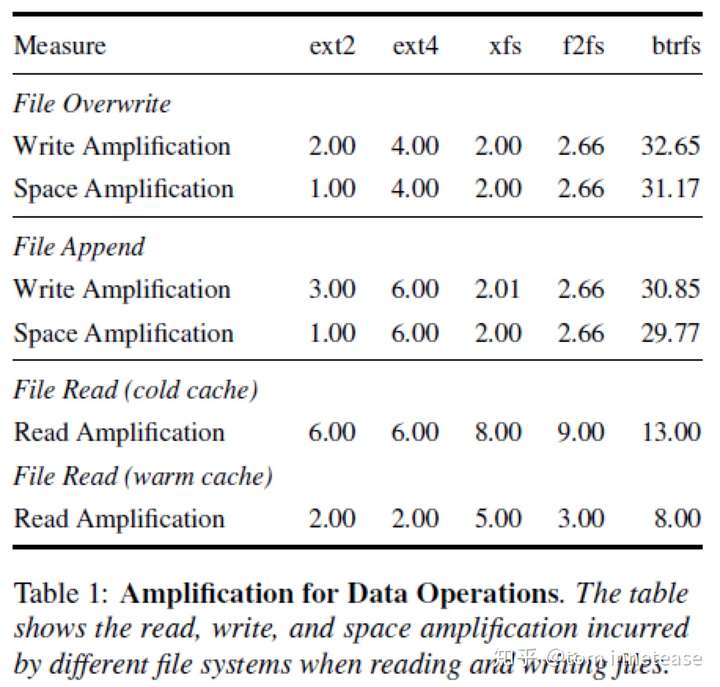
下图中的数据表示了以block大小为单位对不同文件系统进行读写,在不同场景下的读写放大及空间放大情况。我们以ext4文件系统说明下个参数的含义。在对文件进行Overwrite时,即将数据覆盖写入到文件中,除了写入数据外,还涉及到日志的写入(其中日志写入两次,一次记录更改的inode,一次为commit记录,具体可参考[5])、文件inode的更改,每次写的最小单位是block,因此最终相当于写入次数以及空间放大了四倍;而在进行Append写入时,由于需要新分配空间,因此相对于Overwrite增加了bitmap的更改以及superblock的更改(superblock记录总的空间分配情况),写放大和空间放大均为六倍。读文件时,在没有命中任何缓存的情况下(cold cache),需要读大量元数据,例如:目录、文件inode、superblock等,最终读放大为六倍;而如果是在顺序读的情况下(warm cache),像superblock、bitmap、目录等这些元数据都缓存在内存中,只需读取文件inode和文件数据。
同理,其他文件系统由于不同的结构和设计原理,其IO放大和空间放大系数也各不相同。
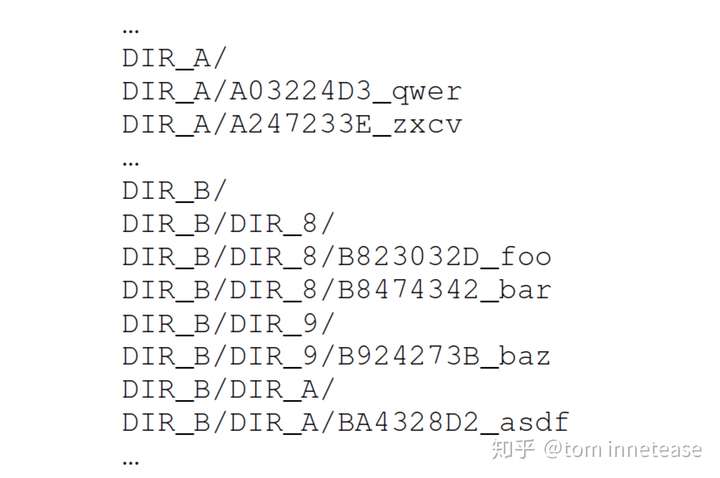
- 对象遍历
ceph的数据被划分为object存放,object以32位的hash值进行标识,ceph在进行scrubbing、backfill或者recovery时都需要根据hash值遍历这些object;POSIX文件系统不提供有序的文件遍历接口,为此FileStore根据文件的数量和hash的前缀将object划分到不同的子目录,其原则如下:
- 当目录下的文件个数>100个时,拆分子目录;目录名以文件名的hash前缀为依据(拆分一级目录时,以hash第一位为拆分依据,二级目录以第二位hash为拆分依据,依次类推)
- 当所有子目录下的文件个数<50个时,将合并到上级目录
因此FileStore在使用过程中需要不断合并拆分目录结构;这种方式将文件按照前缀放到不同目录,但对于同一目录中的文件依然无法很好排序,因此需要将目录中的所有文件读到内存进行排序,这样在一定程度上增加了CPU开销。
- 其他
- FileStore由于设计的较早,无法支持当前较新的存储技术,例如使用spdk技术读写NVMe盘。
- 数据和元数据分离不彻底。
- 流控机制不完整导致IOPS和带宽抖动(FileStore自身无法控制本地文件系统的刷盘行为)。
- 频繁syncfs系统调用导致CPU利用率居高不下。
BlueStore介绍
需求
首先看下BlueStore设计之初的一些需求:
- 对全SSD及全NVMe SSD闪存适配
- 绕过本地文件系统层,直接管理裸设备,缩短IO路径
- 严格分离元数据和数据,提高索引效率
- 使用KV索引,解决文件系统目录结构遍历效率低的问题
- 支持多种设备类型
- 解决日志“双写”问题
- 期望带来至少2倍的写性能提升和同等读性能
- 增加数据校验及数据压缩等功能
逻辑架构
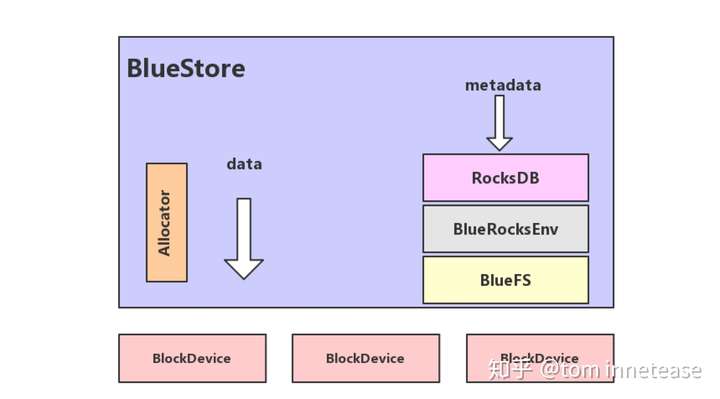
BlueStore的逻辑架构如上图所示,模块的划分都还比较清晰,我们来看下各模块的作用:
- RocksDB:rocksdb是facebook基于leveldb开发的一款kv数据库,BlueStore将元数据全部存放至RocksDB中,这些元数据包括存储预写式日志、数据对象元数据、Ceph的omap数据信息、以及分配器的元数据 。
- BlueRocksEnv:这是RocksDB与BlueFS交互的接口;RocksDB提供了文件操作的接口EnvWrapper,用户可以通过继承实现该接口来自定义底层的读写操作,BlueRocksEnv就是继承自EnvWrapper实现对BlueFS的读写。
- BlueFS:BlueFS是BlueStore针对RocksDB开发的轻量级文件系统,用于存放RocksDB产生的.sst和.log等文件。
- BlockDecive:BlueStore抛弃了传统的ext4、xfs文件系统,使用直接管理裸盘的方式;BlueStore支持同时使用多种不同类型的设备,在逻辑上BlueStore将存储空间划分为三层:慢速(Slow)空间、高速(DB)空间、超高速(WAL)空间,不同的空间可以指定使用不同的设备类型,当然也可使用同一块设备,具体我们会在后面的文章进行说明。
- Allocator:负责裸设备的空间管理,只在内存做标记,目前支持StupidAllocator和BitmapAllocator两种分配器,Stupid基于extent的方式实现 。
设计思想
在设计分布式文件系统的本地存储时,我们必须考虑数据的一致性和可靠性。在数据写入的过程中,由于可能存在异常掉电、进程崩溃等突发情况,导致数据还未全部写入成功便结束。虽然硬盘本身可以保证在扇区级别写入的原子性,但是一般文件系统的一个写请求通常包含多个扇区的数据和元数据更新,无法做到原子写。
常用的解决办法是引入日志系统,数据写入磁盘之前先写到日志系统,然后再将数据落盘;日志写入成功后,即便写数据时出现异常,也可以通过日志回放重新写入这部分数据;如果写日志的过程中出现异常,则直接放弃这部分日志,视为写入失败即可,以此保证原子写入。但是这种方式导致每份数据都需要在磁盘上写入两次,严重降低了数据的写入效率。
另一种方式则是采用ROW(Redirect on write)的方式,即数据需要覆盖写入时,将数据写到新的位置,然后更新元数据索引,这种方式由于不存在覆盖写,只需保证元数据更新的原子性即可。对于对齐的覆盖写入时,这种方式没有问题,但是如果是非对齐的覆盖写呢?
我们举个例子:某文件的逻辑空间 [0,4096) 区间的数据在磁盘上的物理映射地址为[0, 4096),磁盘的块(即磁盘读写的最小单元)大小为4096;如果要覆盖写文件[0,4096)区间的数据,那使用ROW的方式没有问题,重新再磁盘上分配一个新的块写入,然后更新元数据中的映射关系即可;但是如果写文件[512,4096)区域,也就是非对齐的覆盖写时,新分配的块中只有部分数据,旧的物理空间中仍有部分数据有效,这样元数据中需要维护两份索引,而且在读取文件的该块数据时,需要从多块磁盘块中读取数据,如果多次进行非对齐覆盖写,这种问题将更严重。
解决这种问题办法是使用RMW(Read Modify Write)的方法,即在发生非对齐覆盖写时,先读取旧的数据,更新的数据合并后,对齐写入到磁盘中,从而减少元数据、提高读性能,但这种方式也存在一种缺点,写数据时需要先读数据,存在一定的性能损耗。
分析完ROW的方式后,读者是否会有疑问,每次写入都放到新的位置,那么文件在磁盘中的物理连续性岂不是无法保证?的确,在传统的文件系统设计时,都是面向HDD盘,这种类型的盘在读写时会有磁头寻道的时间,对于非连续的物理空间读写,性能极差,在设计时会尽可能考虑数据存放的连续性,因此很少会采用ROW的方式。但是随着SSD盘的逐渐普及,随机读写的性能不再成为主要的性能关注点,越来越多的存储系统开始采用全闪存的磁盘阵列,相信ROW的方式会成为更加主流的方式。
我们再来看下BlueStore是怎么实现的,BlueStore在设计时便考虑了全闪存的磁盘阵列,但是仍要考虑使用HDD盘的场景,因此并未完全采用ROW的方式。
我们以下图为例进行说明,BlueStore提供了一个最小分配单元min_alloc_size的配置项,一般为磁盘块大小的整数倍,在此例中min_alloc_size为block大小的4倍。
写入的数据如果与min_alloc_size大小对齐,则使用ROW的方式,将数据写到新的地址空间,然后更改元数据索引,并回收原先占用的空间,元数据更新的原子性由RocksDB的事务特性进行保障。
而对于非min_alloc_size对齐的区域,则使用RMW的方式进行原地覆盖写(只读取非块大小对齐区域所在块,一般就是写入数据的第一个或最后一个块),写入的这部分数据可能跨多个块(因为min_alloc_size是块大小的整数倍),而磁盘只保证单个块大小的原子写入,对于多个块的原子写需要引入类似日志的功能,BlueStore用RocksDB来实现日志功能,将覆盖的这部分数据记到RocksDB中,完成以后再将数据覆盖写入到实际的数据区域,落盘成功以后再删除日志中的记录。
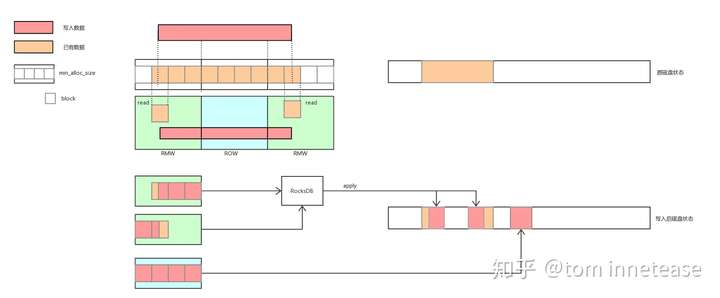
BlueStore对于写的流程处理较为复杂,我们将在后面的章节中详细进行分析。
总结
BlueStore的设计考虑了FileStore中存在的一些硬伤,抛弃了传统的文件系统直接管理裸设备,缩短了IO路径,同时采用ROW的方式,避免了日志双写的问题,在写入性能上有了极大的提高。
通过分析BlueStore的基本结构、考虑的问题以及设计思想,我们对于BlueStore有了大概的了解;BlueStore在设计时有考虑到未来存储的应用环境,是一种比较先进的本地文件系统,但也不可避免存在一些缺陷,例如较为复杂的元数据结构和IO逻辑,在大量小IO下可能存在的double write问题,较大的元数据内存占用等(当然有些问题在ceph的使用场景下可能不存在,但是我们如果希望借鉴BlueStore来设计本地文件系统就不得不考虑这些问题)。
在后续的系列文章中,我们将继续深入剖析各个模块的设计原理和流程,也会对BlueStore测试过程中发现的一些问题展开讨论。
Notes
作者:网易存储团队工程师 杨耀凯。限于作者水平,难免有理解和描述上有疏漏或者错误的地方,欢迎共同交流;部分参考已经在正文和参考文献中列表注明,但仍有可能有疏漏的地方,有任何侵权或者不明确的地方,欢迎指出,必定及时更正或者删除;文章供于学习交流,转载注明出处
参考资料
[1]. New in Luminous: BlueStore. https://ceph.com/community/new-luminous-bluestore/.
[2]. ceph存储引擎bluestore解析. https://www.sysnote.org/2016/08/19/ceph-bluestore/.
[3]. Jayashree Mohan, Rohan Kadekodi, Vijay Chidambaram. Analyzing IO Amplification in Linux File Systems. arXiv:1707.08514v1 [cs.OS] 26 Jul 2017 .
[4]. 谢型果等. Ceph设计原理与实现[M]. 北京:机械工业出版社,2017.12.
[5]. Linux: The Journaling Block Device. https://wangxu.me/translation/2008/08/21/journaling-block-device/index.html.