进程理论:
进程是程序运行的过程,进程是对正在运行程序的一个抽象。
进程的概念起源于操作系统,是操作系统最核心的概念。
操作系统管理复杂的硬件,应用程序也可以直接使用操作系统使用的功能来间接使用硬件。
总结:操作系统就是一个协调管理控制计算机硬件资源和软件资源的控制程序

操作系统功能分为两部分
#一:隐藏了丑陋的硬件调用接口,为应用程序员提供调用硬件资源的更好,更简单,更清晰的模型(系统调用接口)。应用程序员有了这些接口后,就不用再考虑操作硬件的细节,专心开发自己的应用程序即可。 例如:操作系统提供了文件这个抽象概念,对文件的操作就是对磁盘的操作,有了文件我们无需再去考虑关于磁盘的读写控制(比如控制磁盘转动,移动磁头读写数据等细节), #二:将应用程序对硬件资源的竞态请求变得有序化 例如:很多应用软件其实是共享一套计算机硬件,比方说有可能有三个应用程序同时需要申请打印机来输出内容,那么a程序竞争到了打印机资源就打印,然后可能是b竞争到打印机资源,也可能是c,这就导致了无序,打印机可能打印一段a的内容然后又去打印c...,操作系统的一个功能就是将这种无序变得有序。
#作用一:为应用程序提供如何使用硬件资源的抽象 例如:操作系统提供了文件这个抽象概念,对文件的操作就是对磁盘的操作,有了文件我们无需再去考虑关于磁盘的读写控制 注意: 操作系统提供给应用程序的该抽象是简单,清晰,优雅的。为何要提供该抽象呢? 硬件厂商需要为操作系统提供自己硬件的驱动程序(设备驱动,这也是为何我们要使用声卡,就必须安装声卡驱动。。。),厂商为了节省成本或者兼容旧的硬件,它们的驱动程序是复杂且丑陋的 操作系统就是为了隐藏这些丑陋的信息,从而为用户提供更好的接口 这样用户使用的shell,Gnome,KDE看到的是不同的界面,但其实都使用了同一套由linux系统提供的抽象接口 #作用二:管理硬件资源 现代的操作系统运行同时运行多道程序,操作系统的任务是在相互竞争的程序之间有序地控制对处理器、存储器以及其他I/O接口设备的分配。 例如: 同一台计算机上同时运行三个程序,它们三个想在同一时刻在同一台计算机上输出结果,那么开始的几行可能是程序1的输出,接着几行是程序2的输出,然后又是程序3的输出,最终将是一团糟(程序之间是一种互相竞争资源的过程) 操作系统将打印机的结果送到磁盘的缓冲区,在一个程序完全结束后,才将暂存在磁盘上的文件送到打印机输出,同时其他的程序可以继续产生更多的输出结果(这些程序的输出没有真正的送到打印机),这样,操作系统就将由竞争产生的无序变得有序化。 详解
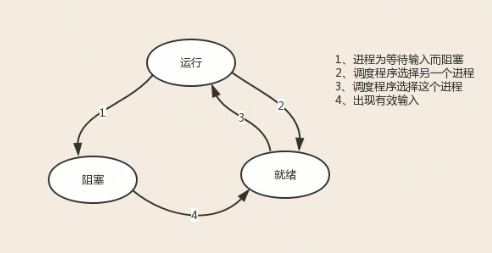
进程的运行状态一共有三种
运行:正在被cpu执行着
阻塞:遇到IO
就绪:IO 完了等待 CPU
一个运行的程序遇到IO了就是阻塞
运行时间过长进入就绪态
IO结束才有资格跟操作系统要CPU (这里需要综合整理消化)
唯一可以控制的状态是阻塞态,把IO 阻塞降下来就绪态就多了。(降IO)
进程暂停的情况下,保存的状态
到底怎么启进程?
为什么要开启子进程
在一个正在运行的父进程里面开启子进程是为了将我原来在父进程里面串行的任务拿到子进程里面执行,执行并发执行的效果。
代码在硬盘放着,右键运行操作系统接受指令在内存造内存空间,然后准备往内存空间放代码,操作系统将代码从硬盘读到内存里,然后调CPU运行
开启进程的两种方式
# # # 方式一:
from multiprocessing import Process#process是一个类
import time
def task(x):
print('%s is running' %x) #子进程起来以后运行左边三行代码
time.sleep(3)
print('%s is done' %x)
if __name__ == '__main__':#if __name__ == '__main__'开子进程要开启
# Process(target=task,kwargs={'x':'子进程'})
p=Process(target=task,args=('子进程',)) # 如果args=(),括号内只有一个参数,一定记住加逗号 不加括号是变量
#process是一个类类实例化生成对象
p.start() # 只是在操作系统发送一个开启子进程的信号
print('主')
#子进程拷贝父进程的空间,导模块会产生名称空间把数据丢进去
方式二:
from multiprocessing import Process
import time
class Myprocess(Process):
def __init__(self,x):
super().__init__()
self.name=x
def run(self):
print('%s is running' %self.name)
time.sleep(3)
print('%s is done' %self.name)
if __name__ == '__main__':
p=Myprocess('子进程1')
p.start() #p.run()
print('主')
from multiprocessing import Process
import time
def task(x,n):
print('%s is running' % x)
time.sleep(n)
print('%s is done' % x)
if __name__ == '__main__':
# Process(target=task,kwargs={'x':'子进程'})
p1 = Process(target=task, args=('子进程1',3)) # 如果args=(),括号内只有一个参数,一定记住加逗号
p2 = Process(target=task, args=('子进程2',5)) # 如果args=(),括号内只有一个参数,一定记住加逗号
p1.start() # 只是在操作系统发送一个开启子进程的信号
p2.start() # 只是在操作系统发送一个开启子进程的信号
print('主')
父进程在自己代码运行完了并不会马上结束掉,要子的结束才能结束掉
僵尸进程和孤儿进程
什么是僵尸进程?
僵尸进程是一种独特的数据结构。子进程在运行完毕以后内存空间都释放掉了,保留ID号
链接:https://www.zhihu.com/question/26432067/answer/70643183
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
什么是僵尸进程?
Unix进程模型中,进程是按照父进程产生子进程,子进程产生子子进程这样的方式创建出完成各项相互协作功能的进程的。当一个进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。如果父进程没有这么做的话,会产生什么后果呢?此时,子进程虽然已经退出了,但是在系统进程表中还为它保留了一些退出状态的信息,如果父进程一直不取得这些退出信息的话,这些进程表项就将一直被占用,此时,这些占着茅坑不拉屎的子进程就成为“僵尸进程”(zombie)。系统进程表是一项有限资源,如果系统进程表被僵尸进程耗尽的话,系统就可能无法创建新的进程。
那么,孤儿进程又是怎么回事呢?
孤儿进程是指这样一类进程:在进程还未退出之前,它的父进程就已经退出了,一个没有了父进程的子进程就是一个孤儿进程(orphan)。既然所有进程都必须在退出之后被wait()或waitpid()以释放其遗留在系统中的一些资源,那么应该由谁来处理孤儿进程的善后事宜呢?这个重任就落到了init进程身上,init进程就好像是一个民政局,专门负责处理孤儿进程的善后工作。每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程“凄凉地”结束了其生命周期的时候,init进程就会代表党和政府出面处理它的一切善后工作。
解决办法:
把他爹干死 所有僵尸进程被__init__进程收编
进程内存空间彼此隔离
from multiprocessing import Process
import time
x=100
def task():
global x
x=0
print('done')
if __name__ == '__main__':
p=Process(target=task)
p.start()
time.sleep(500) # 让父进程在原地等待,等了500s后,才执行下一行代码
print(x)
p.join()的方法
#1、join
from multiprocessing import Process
import time
def task(name):
print('%s is running ' %name)
time.sleep(3)
print('%s is done ' % name)
if __name__ == '__main__':
p=Process(target=task,args=('子进程1',))
p.start()
p.join() # 让父进程在原地等待,等到子进程运行完毕后,才执行下一行代码
print('主')
p.join()操作
p_l=[]
start=time.time()
for i in range(1,4):
p=Process(target=task,args=('子进程%s' %i,i))
p_l.append(p)
p.start()
# print(p_l)
for p in p_l:
p.join()
stop=time.time()
print('主',(stop-start))
进程对象其他相关属性或方法
父进程内查看子进程PID方式
if __name__ == '__main__':
p1=Process(target=task,args=(10,))
# print(p1.pid)
p1.start()
print(p1.pid) # 父进程内查看子pid的方式
print('主')
进程对象的方法或属性详解
================================================================================================================================================================
这里要进行修改
基于udp协议的套接字通信
客户端
import socket
client=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
while True:
msg=input('>>:').strip()
client.sendto(msg.encode('utf-8'),('127.0.0.1',8080)) #sendto指定发给谁
data,server_addr=client.recvfrom(1024) #元祖的解压
print(data)
client.close()
#udp也不用 connect(请求建立连接)
import socket
server=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)#数据报协议->udp协议 拿到套接字对象 没有粘包问题
server.bind(('127.0.0.1',8080))
while True:
data,client_addr=server.recvfrom(1024)
print('=====>',data,client_addr)
server.sendto(data.upper(),client_addr)
server.close()
#udp协议没有连接 不用listen 没有accept
#为什么udp发空不卡 为什么收空
#udp称之为数据报协议 每个协议钱都带报头
#刚刚输入空,并不是空数据,是带报头出去的,但tcp还没添加加报头 就是真的是空数据了
基于tcp协议不会有并发的效果,但是基于udp协议会有并发的效果
TCP(流式协议):可靠性高。会因为网络原因丢包,但只有在一端收到另一端发来的ack确认信息才会将信息在内存中删除,如果发现丢包(一段时间内没有回复)会将信息再发一份。TCP会存在粘包问题,收与发可以不是对应的。必须先启动服务端,否则报错。
UDP(数据报协议):可靠性低。信息一旦发出即在内存中删除,如果发生丢包,信息即丢失。UDP效率高速度快的主要原因,一时因为不建连接,二是因为
接受后不会确认。UDP没有粘包问题,收与发一一对应。如果发hello,但收一个字符在windows系统中会报错。在linux系统中不会报错,只接受h。
并行:(真正意义上的)同时运行,并行属于并发。
并发:看起来同时运行就可以了。
udp协议没有粘包现象
基于socketserver模块实现并发的套接字
操作系统原理
1串行:一个任务完完整整地运行完毕后,才能运行下一个任务
2并发:看起来同时进行,单核也可以实现并发
3并行:真正意义上多个任务同时运行,只有多核才实现并行
作为cpu干的是计算
IO操作:内容由硬盘刷到内存上,这个操作称之为write操作
:由硬盘往内存读,也称之为IO操作
多道技术:(单个CPU在多个程序中切换以实现并发)
多道的产生背景是想要在单个CPU的情况下实现多个进程并发执行的效果
a.空间上的复用(多道程序复用内存空间)
b.时间上的复用(多道程序复用CPU时间)
CPU遇到IO操作要切换(提升效率)
一个进程遇到CPU占用时间过长也切(降低效率)
进程与进程之间的内存空间是互相隔离的
多道技术其实是操作系统在用
cpu遇到IO切换:可以提升效率
一个进程占用CPU的时间过长也会切走,为了实现并发效果不得已而为之,反而会降低程序的运行效果
分时操作系统:相当于给每一个程序员发一套联机终端 让程序员以为独享计算机资源