让我们看一下下面的图,它向我们展示了存在于基于linux的系统上的不同内存分配器,稍后讨论它。

内核内存分配器概述
有一种分配机制可以满足任何类型的内存请求。根据你需要什么样的内存,你可以选择一个最接近你的目标。主要的分配器是页分配器,它只处理页(页是它能交付的最小内存单元)。然后是SLAB分配器,它构建在页面分配器之上,从它获取页面并返回较小的内存实体(通过SLAB和缓存)。这是kmalloc分配器所依赖的分配器。
页分配器
页分配器是Linux系统中最低级别的分配器,是其他分配器所依赖的。系统的物理内存由固定大小的块(称为页帧)组成。在内核中,页帧(page frame)在内核里表示为结构体 struct page 的实例。一页是操作系统能给予任何低级别内存请求的最小内存单位。
页分配 API
我们知道内核页面分配器使用 buddy 算法来分配和释放页面块。页面以大小为2的幂的块分配(为了从buddy算法中得到最好的结果)。这意味着它可以分配1页、2页、4页、8页、16页等等:
1. alloc_pages(mask, order)申请2的order次幂个页, 并返回struct page结构体的实例,指向申请到的block的第一页。如果只申请一页内存,order的值应该为0。以下是alloc_page(mask)实现:
struct page *alloc_pages(gfp_t mask, unsigned int order) #define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
__free_pages()用于释放由alloc_pages()函数分配的内存。它接受一个指向已分配页面的指针作为参数,其顺序与分配时相同:
void __free_pages(struct page *page, unsigned int order);
2. 还有其他函数以同样的方式工作,但不是struct page的实例,它们返回保留块的地址(虚拟地址)。比如 __get_free_pages(mask, order) 和 __get_free_page(mask):
unsigned long __get_free_pages(gfp_t mask, unsigned int order); unsigned long get_zeroed_page(gfp_t mask);
free_pages()用于释放用__get_free_pages()分配的页面。地址addr参数表示被分配页面的起始区域,以及参数order,应该与分配时的相同:
free_pages(unsigned long addr, unsigned int order);
在上面两种情况下,mask 指定有关请求的详细信息,即内存区域和分配器的行为。mask可选值如下:
- GFP_USER: 用于用户内存分配。
-
GFP_KERNEL: 内核内存分配的常用标志。
-
GFP_HIGHMEM: 从HIGH_MEM区域请求内存。
-
GFP_ATOMIC: 以不能休眠的原子方式分配内存。当需要从中断上下文分配内存时使用。
使用GFP_HIGHMEM时需要注意,不应该与__get_free_pages() (或者 __get_free_page())一起使用,因为HIGHMEM内存不能保证是连续的,所以不能返回从该区域分配的内存地址。全局来说,只有GFP_*的一个子集被允许在内存相关的函数中:
1 unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order) 2 { 3 struct page *page; 4 /* 5 * __get_free_pages() returns a 32-bit address, which cannot represent 6 * a highmem page 7 */ 8 VM_BUG_ON((gfp_mask & __GFP_HIGHMEM) != 0); 9 page = alloc_pages(gfp_mask, order); 10 if (!page) 11 return 0; 12 return (unsigned long) page_address(page); 13 }
alloc_pages() /__get_free_pages() 可以分配的最大页面数是1024。这意味着在一个4KB大小的系统上,您最多可以分配1024 * 4KB = 4MB。kmalloc也是一样。
转换函数
page_to_virt()函数用于将struct page(例如alloc_pages()返回的页面)转换为内核地址。virt_to_page()接受内核虚拟地址并返回其关联的struct page实例(就像使用alloc_pages()函数分配的一样)。virt_to_page() 和 page_to_virt() 都定义在 <asm/page.h>:
struct page *virt_to_page(void *kaddr); void *page_to_virt(struct page *pg);
page_address() 宏返回的虚拟地址对应于 struct page 实例的起始地址(逻辑地址):
void *page_address(const struct page *page);
我们可以在get_zeroed_page()函数中看到它是如何使用的:
1 unsigned long get_zeroed_page(unsigned int gfp_mask) 2 { 3 struct page * page; 4 page = alloc_pages(gfp_mask, 0); 5 if (page) { 6 void *address = page_address(page); 7 clear_page(address); 8 return (unsigned long) address; 9 } 10 return 0; 11 }
__free_pages() 和 free_pages() 容易混淆。它们之间的主要区别是 free_pages() 接受一个虚地址作为参数,而__free_pages()接受一个struct page 结构作为参数。
slab分配器
slab 分配器是 kmalloc() 所依赖的。它的主要目的是消除在内存分配较小的情况下由buddy系统引起的内存分配/释放造成的碎片,并加快常用对象的内存分配。
buddy 算法
内存分配请求的大小被四舍五入到2的幂,然后 buddy 分配器搜索相应的列表。如果不存在请求的条目,则下一个上级列表(其块的大小是上一个列表的两倍)中的条目被分成两部分(称为buddies)。分配器使用前半部分,而另一部分添加到下一个列表中。这是一种递归方法,当 buddy 分配器成功地找到可以拆分的块时,或者当块达到最大大小且没有可用的空闲块时,该方法就会停止。
举个例子,如果最小分配大小是1 KB,内存大小是1 MB,buddy 分配器将创建一个空列表1 KB洞,空列表2 KB的洞,一个4 KB洞,8 KB、16 KB, 32 KB、64 KB、128 KB、256 KB、512 KB、和一个列表1 MB洞。它们最初都是空的,除了1MB的列表,它只有一个洞。让我们假如我们想要分配一个70K大小的块。buddy 分配器将它四舍五入到128K,最终将这1MB分成两个512K块,然后是256K,最后是128K,然后它将把其中一个128K块分配给用户。以下是该场景的概述:
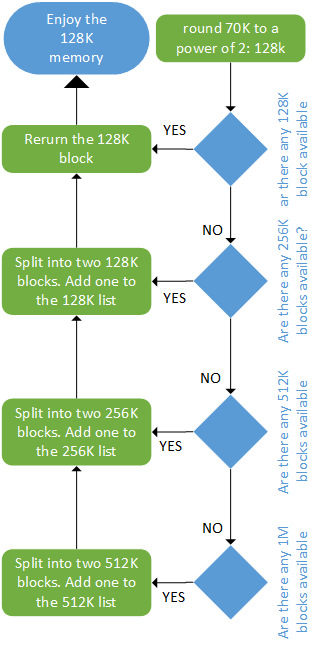
使用buddy算法分配
释放和分配一样快。下图总结了回收算法:

使用buddy算法进行回收
slab 分配器分析
- Slab: 这是一个由几个页帧组成的连续的物理内存。每个slab被划分为相同大小的相等块,用于存储特定类型的内核对象,如索引节点、互斥对象等。每个slab是一个对象的数组。
- Cache: 它由链表中的一个或多个slab组成,它们在内核中表示为 struct kmem_cache_t 结构的实例。cache 只存储相同类型的对象(例如,仅存储inodes,或仅存储地址空间结构).
Slabs可能处于以下状态之一:
- Empty: 这是 slab 上的所有 objects(chunks) 被标记为 free 的地方。
- Partial: used 和 free 的 objects 同时存在于 slab 中。
- Full: slab 上所有的 objects 被标记为 used。
构建 caches 取决于内存分配器,最初,每个slab被标记为空。当你的代码为内核对象分配内存时,系统会在缓存的 partial/free slab 中为该类型的对象寻找空闲位置。如果没有找到,系统将分配一个新的slab并将其添加到 cache 中。从这个slab中分配新对象,并且slab被标记为partial。当内存使用完(释放)时,对象被简单地返回到初始化状态的slab缓存。
这就是为什么内核还提供帮助函数来获取初始化为零的内存,以消除以前的内容。slab保持有多少对象被使用的引用计数,所以当缓存中的所有slab都满了,并且请求另一个对象时,slab分配器负责添加新的slab:

Slab cache概述
这有点像创建一个 per-object 分配器,系统为每种类型的对象分配一个缓存,并且只有相同类型的对象可以存储在同一个缓存中(例如,只有 task_struct 结构体)。
内核中有不同类型的slab分配器,取决于是否需要紧凑性、缓存友好性或原始速度:
- SLOB,它是尽可能紧凑的
- SLAB,它是尽可能有利于缓存的
- SLUB,非常简单,需要较少的指令开销计数
kmalloc
kmalloc是一个内核内存分配函数,如用户空间中的malloc()。kmalloc返回的内存在物理内存和虚拟内存中是连续的:
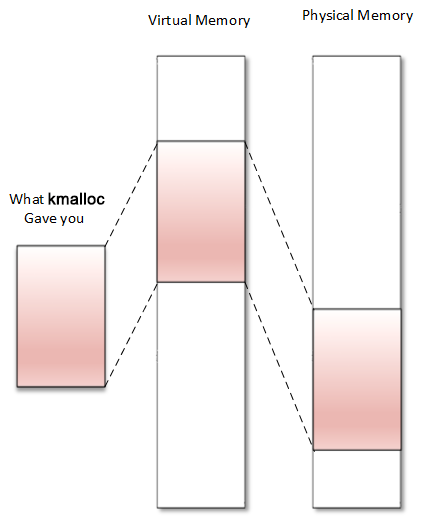
kmalloc分配器是内核中通用的高级内存分配器,它依赖于SLAB分配器。kmalloc返回的内存有一个内核逻辑地址,因为它是从 LOW_MEM 区域分配的,除非指定了 HIGH_MEM。它在<linux/slab.h>中声明,在驱动程序中使用kmalloc时要包含这个头文件。以下是原型:
void *kmalloc(size_t size, int flags);
size指定要分配的内存大小(以字节为单位)。flags 决定如何分配内存以及在哪里分配内存。可用 flags 与 page分配器的 flags 相同(GFP_KERNEL, GFP_ATOMIC, GFP_DMA,等等):
- GFP_KERNEL: 我们不能在中断处理程序中使用这个标志,因为它的代码可能会休眠。它总是从 LOM_MEM 区域返回内存(因此是一个逻辑地址)。
- GFP_ATOMIC: 这保证了分配的原子性。在中断上下文中使用的唯一标志。请不要滥用它,因为它使用一个应急内存池。
- GFP_USER: :这将内存分配给用户空间进程。与分配给内核的内存是截然不同的。
- GFP_HIGHUSER: 这将从HIGH_MEMORY区域分配内存。
- GFP_DMA: 从DMA_ZONE中分配内存。
在成功分配内存时,kmalloc返回分配的块的虚拟地址,保证是物理连续的。如果出错,它将返回NULL。
kmalloc在分配小容量内存时依赖SLAB缓存。在这种情况下,内核将分配的区域大小舍入到能够容纳它的最小SLAB缓存的大小。始终使用它作为您的默认内存分配器。在 ARM 和 x86 架构中,每次分配的最大大小是4MB,总分配的最大大小是128MB。
kfree函数用于释放kmalloc分配的内存。以下是kfree()的原型:
void kfree(const void *ptr)
例子:
1 #include <linux/init.h> 2 #include <linux/module.h> 3 #include <linux/slab.h> 4 #include <linux/mm.h> 5 6 void *ptr; 7 static int alloc_init(void) 8 { 9 size_t size = 1024; /* allocate 1024 bytes */ 10 ptr = kmalloc(size, GFP_KERNEL); 11 if(!ptr) { 12 /* handle error */ 13 pr_err("memory allocation failed "); 14 return -ENOMEM; 15 } else { 16 pr_info("Memory allocated successfully "); 17 } 18 19 return 0; 20 } 21 static void alloc_exit(void) 22 { 23 kfree(ptr); 24 pr_info("Memory freed "); 25 } 26 module_init(alloc_init); 27 module_exit(alloc_exit); 28 MODULE_LICENSE("GPL"); 29 MODULE_AUTHOR("xxx");
其他类似的函数有:
1 void kzalloc(size_t size, gfp_t flags); 2 void kzfree(const void *p); 3 void *kcalloc(size_t n, size_t size, gfp_t flags); 4 void *krealloc(const void *p, size_t new_size, gfp_t flags);
krealloc() 是内核中的用户空间 realloc() 函数。由于 kmalloc() 返回的内存保留了以前的内容,如果将其暴露给用户空间,就可能存在安全风险。要获得值全为零的内存,您应该使用 kzalloc。kzfree() 是 kzalloc() 的释放函数,而kcalloc()为数组分配内存,其参数n 和 size 分别表示数组中元素的数量和元素的大小。
由于kmalloc()返回内核永久映射中的内存区域(这意味着物理上连续),可以使用 virt_to_phys() 将内存地址转换为物理地址,或者使用 virt_to_bus() 将内存地址转换为IO总线地址。这些宏内部调用 __pa() 或 __va() 中任何一个(如有必要)。物理地址(virt_to_phys(kmalloc'ed address)),通过PAGE_SHIFT向下移动,将生成所分配的块的第一个页面的PFN。
vmalloc
vmalloc() 申请的内存只在虚拟地址上连续,在物理地址上不连续。

返回的内存总是来自HIGH_MEM区域。返回的地址不能被转换成物理地址或总线地址,因为你不能断言内存是物理上连续的。这意味着vmalloc()返回的内存不能在微处理器之外使用(您不能轻松地将其用于DMA目的)。使用vmalloc()为只存在于软件(例如,网络缓冲区)中的大型序列(例如,使用它来分配一个页面没有意义)分配内存是正确的。需要注意的是,vmalloc()比kmalloc()或页分配器函数慢,因为它必须检索内存,构建页表,甚至重新映射到一个虚拟地址连续的范围,而kmalloc()从不这样做。
在使用vmalloc API之前,应该在代码中包含这个头文件:
#include <linux/vmalloc.h>
以下是vmalloc家族原型:
1 void *vmalloc(unsigned long size); 2 void *vzalloc(unsigned long size); 3 void vfree( void *addr);
size是您需要分配的内存大小。成功分配内存后,它返回已分配内存块的第一个字节的地址。如果失败,它将返回NULL。vfree函数用于释放 vmalloc() 分配的内存。
vmalloc的示例如下:
1 #include<linux/init.h> 2 #include<linux/module.h> 3 #include <linux/vmalloc.h> 4 void *ptr; 5 static int my_vmalloc_init(void) 6 { 7 unsigned long size = 8192; 8 ptr = vmalloc(size); 9 if(!ptr) { 10 /* handle error */ 11 printk("memory allocation failed "); 12 return -ENOMEM; 13 } else { 14 pr_info("Memory allocated successfully "); 15 } 16 return 0; 17 } 18 static void my_vmalloc_exit(void) /* function called at the time of 19 20 */ 21 { 22 vfree(ptr); //free the allocated memory 23 printk("Memory freed "); 24 } 25 module_init(my_vmalloc_init); 26 module_exit(my_vmalloc_exit); 27 MODULE_LICENSE("GPL"); 28 MODULE_AUTHOR("xxx");
可以使用 /proc/vmallocinfo 显示系统中 vmalloc 使用的所有内存。VMALLOC_START 和 VMALLOC_END 是两个分隔 vmalloc 地址范围的符号。它们依赖于体系结构,在<asm/pgtable.h>中定义。
内部处理内存分配
让我们关注更底层的分配器,它分配内存页。内核将报告框架页(物理页)的分配,直到真正需要时(当这些页通过读或写被实际访问时)。这种按需分配称为惰性分配,消除了分配永远不会使用的页面的风险。
每当请求一个页时,只更新页表,在大多数情况下会创建一个新条目,这意味着只分配虚拟内存。只有当您访问该页面时,才会引发称为页面错误的中断。这个中断有一个专用的处理程序,称为页面错误处理程序,当尝试访问没有立即成功的虚拟内存时,MMU会调用这个处理程序。
实际上,对于页表中的条目没有设置允许这种访问类型的适当权限位的页,无论其访问类型是什么(读、写、执行),都会引发页错误中断。对该中断的响应可分为以下三种方式之一:
- hard fault: 页面不驻留在任何地方(既不在物理内存中,也不在内存映射文件中),这意味着处理程序不能立即解决故障。处理程序将执行I/O操作,以准备解决故障所需的物理页,并可能在系统工作以解决问题时挂起中断的进程并切换到另一个进程。
- soft fault: 页面驻留在内存的其他地方(在另一个进程的工作集中)。这意味着错误处理程序可以立即将物理内存的一个页附加到适当的页表项上,调整页表项,并恢复被中断的指令,从而解决故障。
- 无法解决的 fault : 这将导致总线错误或segv。SIGSEGV被发送到出错的进程,终止它(默认行为),除非SIGSEV已经安装了一个信号处理程序来改变默认行为。
内存映射通常一开始不附加任何物理页,而是在不关联任何物理内存的情况下定义虚拟地址范围。当访问内存时,实际的物理内存稍后被分配,以响应页面错误异常,因为内核提供了一些标志来确定尝试的访问是否合法,并指定了页面错误处理程序的行为。因此,用户空间brk()、mmap() 和 类似的分配(虚拟)空间,但是物理内存稍后附加。
在中断上下文中出现的页面错误会导致双重错误中断,这通常会使内核感到恐慌(调用panic()函数)。这就是为什么在中断上下文中分配的内存是从内存池中获取的,这不会引发页错误中断。处理双重故障时发生中断,会产生三重故障异常,导致CPU关闭,操作系统立即重启。这种行为实际上是 arc-dependent 的。
copy-on-write (CoW)
CoW(在fork()中大量使用)是一个内核特性,它不会为两个或多个进程共享的数据分配几倍的内存,直到一个进程使用到它(写入它);在这种情况下,内存被分配给它的私有副本。下面展示了页面错误处理程序如何管理CoW(单页案例研究):
- 将PTE添加到进程页表,并标记为不可写。
- 映射将导致在流程VMA列表中创建VMA。该页面被添加到该VMA,该VMA被标记为可写。
- 在页访问(第一次写入时),错误处理程序注意到差异,这意味着这是一个CoW。然后,它将分配一个物理页(分配给之前添加的PTE),更新PTE标志,刷新TLB项,并执行do_wp_page()函数,该函数可以将内容从共享地址复制到新位置。