作为产品的设计师,我们做出的决策要逻辑自证。尽量避免“我认为”或“我觉得”这类主观拍脑袋的决策。因此,用数据驱动产品迭代是一个产品设计方法论,也是我们必须掌握的一项能力。
如 何做数据分析驱动产品迭代?我们可以分为三个步骤。
第一步:明确数据分析的目的
数据分析的目的一般有2个:
- 了解产品或指定功能表现
- 验证假设
验证假设的数据需要根据具体情况来设计。了解产品或指定功能的数据主要有5个维度:
- 产品规模,如:DAU/MAU,付费
- 产品健康度,如:新增,留存,使用时长
- 用户属性,如:用户画像属性,终端数据属性
- 用户行为,如:用户使用产品的路径
- 渠道质量,如:各个渠道的新增留存
我们可以自建后台收集以上数据,这是自由度最大化的做法,但成本较高。也可以利用第三方数据分析平台的SDK快速构建,如:友盟或神策。对于竞品数据,我们可以通过艾瑞,易帆进行查询。
通过收集到的数据,我们可以判断产品目前处于产品发展的哪个阶段,从而制定相应的产品策略。 详见《社交产品方法论(一):自上而下的思考产品》。

产品发展阶段
切记数据分析一定要有目的性的去做。对于每一个收集的数据,要问自己,我们可以做些什么优化的事情吗?如果不能回答这个问题,可能这个数据本身就没有太多意义。比如:我们收集了日活数据,一定要思考如何提升日活,日活需要提升到多少,相应的我们需要做哪些事。单纯的天天盯着日活数据毫无意义的。
第二步:确定收集的数据指标
明确数据分析的目的后,我们需要收集相关的数据来帮助我们决策。数据指标的选择要有重点,尽量选择当下对产品最具有建设意义的,不要为了收集数据而收集。
我们可以参考下在《Lean Analytics》一书中,Alistair 和 Benjamin 提出的用户生命周期 AARRR 5个阶段,根据每个阶段确定相应的重点数据指标。
- A:acquisition (获取),如何获取用户。数据有推广点击量,单个用户获取价格等。
- A:activation(获取),如何激活用户。数据有新增,注册成功率等。
- R:retention(留存),如何留住用户。数据有留存,活跃,使用时长等。
- R:revenue(付费),如何让用户付费。数据有付费金额,付费频率等。
- R:referral (推广),如何让用户推广。数据有分享量,点击量等。
第三步:选择合适的分析方法
针对不同的目的和场景,我们需要选择合适的分析方法。
最常用的就是“埋点”,对不确定的事件进行埋点。比如:预埋一个功能的用户量,使用频率,付费数量等。从而判断该功能的表现如何,或者判断功能优化后是否起了作用。其次,对若干套无明显区别的方案,我们可以使用 A/B Test,让用户投票哪一种方案更好。
最后,推荐下《Lean Analytics》一书中提及的漏斗分析方法,根据用户所处不同阶段,假设用户预期行为,用数据验证假设从而驱动产品迭代。
细节如下:
Tunnel Analysis
综上,数据分析的逻辑图如下:

数据分析逻辑图
举几个笔者最近分析的案例:
(1)产品首页的游戏模块布局优化
- 分析目的:了解功能优化效果
- 收集数据:产品留存和游戏模块使用时长
- 分析方法:埋点,取上线前后一周时间对比
(2)连击礼物2种动效的选择
- 分析目的:验证哪一种连击礼物动效更能促进付费
- 收集数据:礼物的赠送数量
- 分析方法:A/B Test,根据送礼玩家的UID对2取模分为A/B组,取每组的礼物赠送数量平均数。结果需要考虑统计显著性和置信区间。
三、语音房小程序各流程优化
- 分析目的:数据驱动产品模块优化;
- 收集数据:每个漏斗阶段用户转化率,使用时长,分享转化率;
- 分析方法:漏斗分析。
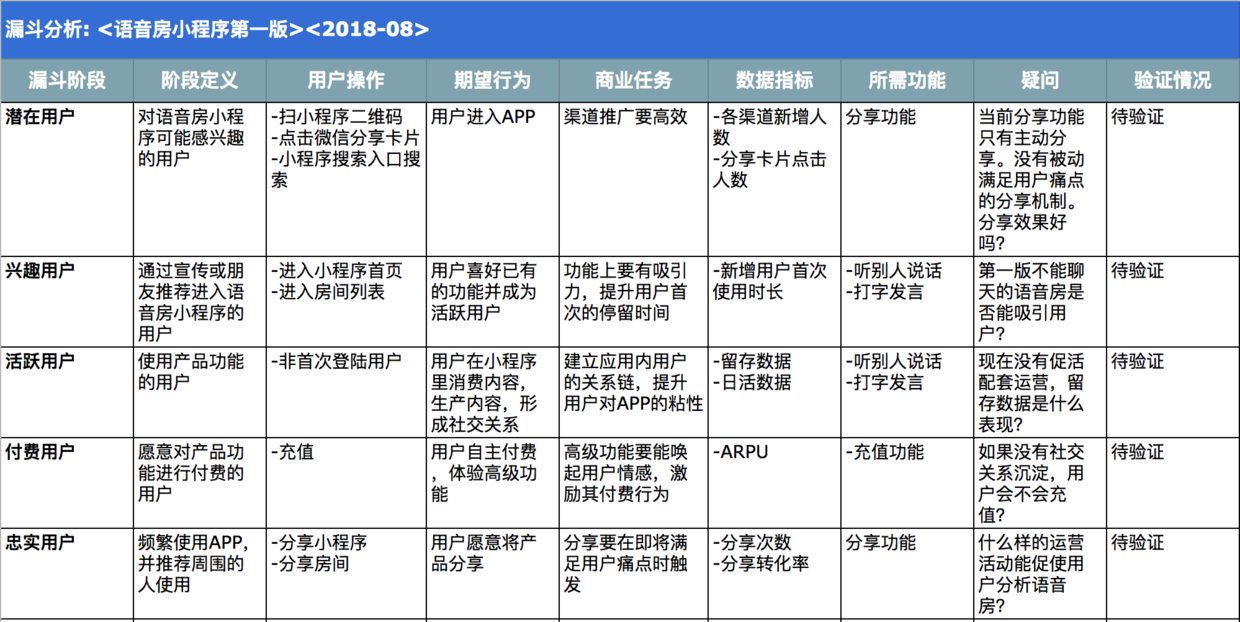
漏斗分析图
四、根据用户行为进行精细化运营
- 分析目的:产品策略优化
- 收集数据:最先使用的功能,功能日活,好友数,留存
- 分析方法:埋点,发现导致留存差异的明显数据区别。强化关键数据,如:引导用户加好友,通过最先使用的功能给其他功能导流,重点优化日活高的功能。
小结
数据分析作为一种方法论,可以在产品设计的各个阶段发挥作用。我们设计产品时,时常问自己三个问题:这个需求值得解决吗?设计方案能解决需求吗?如何用数据验证我们的假设?
从概率论的角度而言,样本量足够大的数据接近于真理。可能从李世石输给阿尔法狗的那天起,信自己就注定比不上信数据了。