对多道并行执行的程序来说,有时它要占用处理器运行,有时要等待传送信息,当得到信息后又可继续执行,一个程序的执行可能受到另一个程序的约束。所以程序的执行实际上是走走停停的,为了能正确反映程序执行时的活动规律和状态变化,引进了进程,以便从变化的角度,动态地分析和研究程序的执行。
用计算机系统来解决某个问题时首先必须编制程序,可把程序看作是具有独立功能的一组指令的集合,或者说是指出处理器执行操作的步骤。程序的执行必须依赖于一个实体-数据集
还有一个问题就是从程序的角度无法正确描述程序执行时的状态。例:只有一个“编译程序”,同时为多个用户服务,有两个需要编译的程序甲、乙,假定编译程序p从a点开始工作,现在正在编译程序甲,当工作到b点时,需要把中间结果记录在磁盘上。于是程序p在b 点等待磁盘传输信息。这时处理器空闲,这时让p为源程序 乙进行编译,编译程序仍从a点开始工作。现在 的问题是如何来描述p的状态?是说“它在b点等侍磁盘传输”还是说“从a点开始执行?
1.进程和线程
进程:把一个程序在一个数据集上的一次执行称为一个进程
(程序是静止的,进程是动态的。在20世纪80年代,大多数操作系统仍采用进程技术,把进程作为操作系统的基本组成单位。进程既是资源分配单位,又是调度和执行单位)
线程:线程是进程中可独立执行的子任务。
(把一个计算问题或一个应用问题作为一个进程,把该进程中可以并发执行的各部分分别作为线程。一个数据库应用程序的运行创建了一个数据库进程,用户要求从数据库中生产一份工资报表,并将它传送到一个文件中。用户在等待报表生成的时候又向数据库提出一个查询请求。操作系统把用户的每一个请求(工资单报表,数据库查询)分别作为数据库进程的一个线程)
为什么引入线程?
1.每个进程都要占用一个进程控制块和一个私有的主存空间,开销比较大;进程之间传递消息时要从一个工作区传到另一个工作区,需专用通信机制,速度较慢
2.进程增多就增加了进程调度的次数,给调度和控制带来了复杂性。
在采用线程的操作系统中,进程是资源分配 单位,而线程是调度、执行单位。
协程:独⽴的栈空间,共享堆空间,调度由⽤户⾃⼰控制,本质上有点类似于⽤户级线程,这些⽤户级线程的调度也是⾃⼰实现的 。⼀个线程上可以跑多个协程,协程是轻量级的线程。
进程——>一个线程——>单线程程序
进程——>多线程——>多线程程序
2.并发和并行
1)多线程程序在cpu一个核蕊上运行就是并发
2)多线程程序在cpu多个核蕊上运行就是并行
并发是逻辑上的同时发生(simultaneous),而并行是物理上的同时发生。
并发:

并行:

3.用户空间线程和内核空间线程之间的映射关系
N:1, 1:1和 M:N
N:1是说,多个(N)用户线程始终在一个内核线程上跑,context上下文切换确实很快,但是无法真正的利用多核。
1:1是说,一个用户线程就只在一个内核线程上跑,这时可以利用多核,但是上下文switch很慢。
M:N是说, 多个goroutine在多个内核线程上跑,这个看似可以集齐上面两者的优势,但是无疑增加了调度的难度。
4.go的调度器
go 的高度器的内部结构:M P G
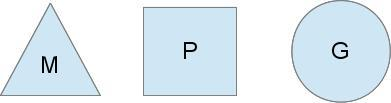
G:代表一个goroutine,它有自己的栈,instruction pointer和其他信息(正在等待的channel等等),用于调度。
P:代表调度的上下文,可以把它看做一个局部的调度器,使go代码在一个线程上跑,它是实现从N:1到N:M映射的关键。

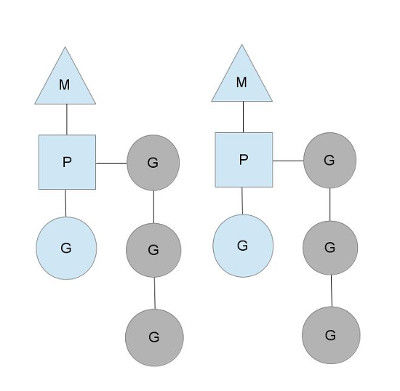
图中看,有2个物理线程M,每一个M都拥有一个context(P),每一个也都有一个正在运行的goroutine。
P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。
图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue),
goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。
图中看到,当一个OS线程M0陷入阻塞时,P转而在OS线程M1上运行。调度器保证有足够的线程来运行所以的context P。
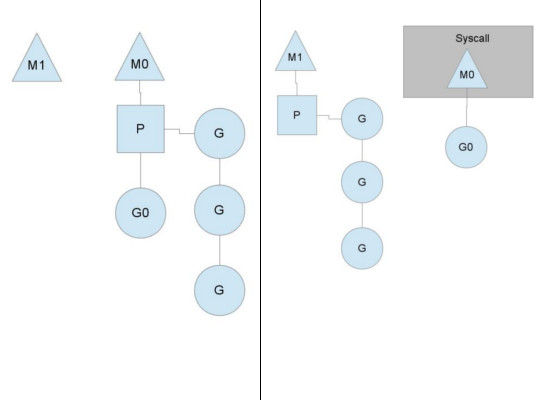
如果没有偷到的话,它就把goroutine放在一个global runqueue里,然后自己就去睡大觉了(放入线程缓存里)。Contexts们也会周期性的检查global runqueue,否则global runqueue上的goroutine永远无法执行。