现在, 我们将揭示Lex是如何将它的输入程序变成一个词法分析器的。 转换的核心是被称为有穷自动机(finite automata) 的表示方法。 这些自动机在本质上是与状态转换图类似的图, 但有如下几点不同:
1) 有穷自动机是识别器(recognizer) , 它们只能对每个可能的输入串简单地回答“是”或“否”。
2) 有穷自动机分为两类:
① 不确定的有穷自动机( NFA)对其边上的标号没有任何限制。 一个符号标记离开同一状态的多条边,并且空串∈ 也可以作为标号。
② 对于每个状态及自动机输入字母表中的每个符号, 确定的有穷自动机(DFA) 有且只有一条离开该状 态、 以该符号为标号的边。 确定的和不确定的有穷自动机能识别的语言的集合是相同的。 事实上, 这些语言的集合正好是能够用正则表达式描述的语言的集合。 这个集合中的语言称为正则语言(regular language) [4]。
6.1 不确定的有穷自动机
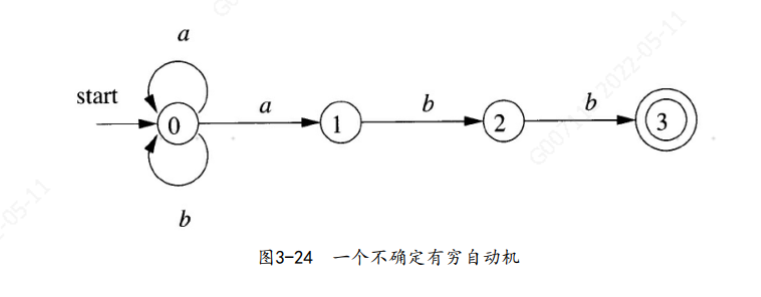
一个不确定的有穷自动机(NFA) 由以下几个部分组成: 1) 一个有穷的状态集合S。
2) 一个输入符号集合Σ, 即输入字母表(input alphabet) 。 我们假设代表空串的∈ 不是Σ中的元素。
3) 一个转换函数(transition function) , 它为每个状态和Σ∪ {∈ }中的每个符号都给出了相应的后继状态(next state) 的集合
4) S中的一个状态s0被指定为开始状态, 或者说初始状态。
5) S的一个子集F被指定为接受状态( 或者说终止状态的) 集合。
不管是NFA还是DFA, 我们都可以将它表示为一张转换图( transition graph) 。 图中的结点是状态, 带有标号的边表示自动机的转换函数。
从状态s到状态t存在一条标号为a的边当且仅当状态t是状态s在输入a上的后继状态之一。 这个图与状态转换图十分相似, 但是:
① 同一个符号可以标记从同一状态出发到达多个目标状态的多条边。
② 一条边的标号不仅可以是输入字母表中的符号, 也可以是空符号串∈
6.2 转换表
我们也可以将一个NFA表示为一张转换表(transition table) , 表的各行对应于状态, 各列对应于输入符号和∈ 。 对应于一个给定状态和给定输入的条目是将NFA的转换函数应用于这些参数后得到的值。 如果转换函数没有给出对应于某个状态-输入对的信息, 我们就把Ø放入相应的表项中
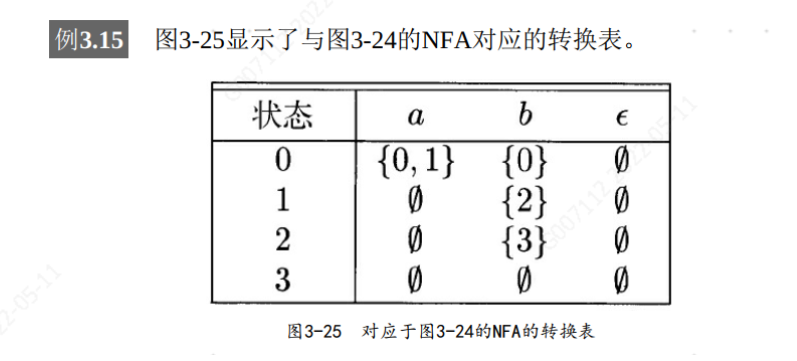
转换表的优点是我们能够很容易地确定和一个给定状态和一个输入符号相对应的转换。 它的缺点是: 如果输入字母表很大, 且大多数状态在大多数输入字符上没有转换的时候, 转换表需要占用大量空间
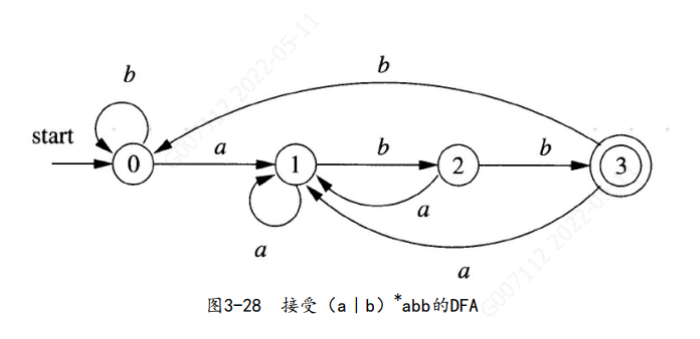
6.3 自动机中输入字符串的接受
一个NFA接受(accept) 输入字符串x, 当且仅当对应的转换图中存在一条从开始状态到某个接受状态的路径, 使得该路径中各条边上的标号组成符号串x。 注意, 路径中的∈ 标号将被忽略, 因为空串不会影响到根据路径构建得到的符号串
6.4 确定的有穷自动机
确定的有穷自动机(简称DFA) 是不确定有穷自动机的一个特例,其中: 1) 没有输入∈ 之上的转换动作。
2) 对每个状态s和每个输入符号a, 有且只有一条标号为a的边离开s。
如果我们使用转换表来表示一个DFA, 那么表中的每个表项就是一个状态。 因此, 我们可以不使用花括号, 直接写出这个状态, 因为花括号只是用来说明表项的内容是一个集合。 NFA抽象地表示了用来识别某个语言中的串的算法, 而相应的DFA则是一个简单具体的识别串的算法。 在构造词法分析器的时候, 我们真正实现或模拟的是DFA。
幸运的是, 每个正则表达式和每个DFA都可以被转变成为一个接受相同语言的DFA。 下边的算法说明了如何将DFA用于串的识别。