6.1 进程和程序
进程process是一个可执行程序program的实例
程序是包含了一系列信息的文件, 这些信息描述了如何在运行时创建一个进程, 所包括的内容 如下所示。
二进制格式标识 :每 个 程 序 文件 都 包 含 用于 描 述 可 执行 文 件 格 式的 元 信 息( metainformation)。内核(kernel)利用此信息来解释文件中的其他信息。大多数 UNIX 实现(包括 Linux)采用可执行连接格式( ELF),这一文件格式比老版本格式具有更多优点。
机器语言指令:对程序算法进行编码
程序入口地址:标识程序开始执行时的起始指令位置
数据:程序文件包含的变量初始值和程序使用的字面常量值(比如字符串)
符号表及重定位表:描述程序中函数和变量的位置及名称。这些表格有多种用途,其中包括调试和运行时的符号解析(动态链接)。
共享库和动态链接信息:程序文件所包含的一些字段,列出了程序运行时需要使用的共享库,以及加载共享库的动态链接器的路径名。
其他信息:程序文件还包含许多其他信息,用以描述如何创建进程
进程是由内核定义的抽象的实体,并为该实体分配用以执行程序的各项系统资源。 从内核角度看,进程由用户内存空间(user-space memory)和一系列内核数据结构组成,其中用户内存空间包含了程序代码及代码所使用的变量, 而内核数据结构则用于维护进程状态信息。 记录在内核数据结构中的信息包括许多与进程相关的标识号(IDs)、虚拟内存表、打开文件的描述符表、信号传递及处理的有关信息、进程资源使用及限制、当前工作目录和大量的其他信息。
6.2 进程号和父进程号
每个进程都有一个进程号(PID),进程号是一个正数,用以唯一标识系统中的某个进程。对各种系统调用而言,进程号有时可以作为传入参数,有时可以作为返回值。
系统调用 getpid()返回调用进程的进程号。 每个进程都有一个创建自己的父进程。使用系统调用 getppid()可以检索到父进程的进程号
getpid()返回值的数据类型为 pid_t,该类型是由 SUSv3 所规定的整数类型,专用于存储进程号。 除了少数系统进程外,比如 init 进程(进程号为 1),程序与运行该程序进程的进程号之间没有固定关系。 Linux 内核限制进程号需小于等于 32767。新进程创建时,内核会按顺序将下一个可用的进程号分配给其使用。每当进程号达到 32767 的限制时,内核将重置进程号计数器,以便从小整数开始分配。
每个进程都有一个创建自己的父进程。使用系统调用 getppid()可以检索到父进程的进程号。实际上,每个进程的父进程号属性反映了系统上所有进程间的树状关系。每个进程的父进程又有自己的父进程,以此类推,回溯到 1 号进程—init 进程,即所有进程的始祖。使用pstree(1)命令可以查看到这一“家族树”( family tree)。 如果子进程的父进程终止,则子进程就会变成“孤儿”, init 进程随即将收养该进程,子进程后续对 getppid()的调用将返回进程号 1。 通过查看由 Linux 系统所特有的/proc/PID/status 文件所提供的 PPid 字段,可以获知每个进程的父进程。
6.3 进程内存布局
每个进程所分配的内存由很多部分组成,通常称之为“段( segment)”。如下所示。
1.文本段包含了进程运行的程序机器语言指令。文本段具有只读属性,以防止进程通过错误指针意外修改自身指令。因为多个进程可同时运行同一程序,所以又将文本段设为可共享,这样,一份程序代码的拷贝可以映射到所有这些进程的虚拟地址空间中。
2.初始化数据段包含显式初始化的全局变量和静态变量。当程序加载到内存时,从可执行文件中读取这些变量的值。
3.未初始化数据段包含了未进行显式初始化的全局变量和静态变量。程序启动之前,系统将本段内所有内存初始化为 0。出于历史原因,此段常被称为 BSS 段。将经过初始化的全局变量和静态变量与未经初始化的全局变量和静态变量分开存放,其主要原因在于程序在磁盘上存储时,没有必要为未经初始化的变量分配存储空间。相反,可执行文件只需记录未初始化数据段的位置及所需大小,直到运行时再由程序加载器来分配这一空间。
4.栈( stack)是一个动态增长和收缩的段,由栈帧组成。系统会为每个当前调用的函数分配一个栈帧。栈帧中存储了函数的局部变量、实参和返回值。
5.堆(heap) 是可在运行时(为变量) 动态进行内存分配的一块区域。
对于初始化和未初始化的数据段而言,表述更清晰的称谓分别是用户初始化数据段和零初始化数据段。
size(1)命令可显示二进制可执行文件的文本段、初始化数据段、非初始化数据段( bss)的段大小
程序清单 6-1 展示了不同类型的 C 语言变量,并以注释说明每种变量分属于哪个段。这些说明正确的前提是假定使用了非优化的编译器,且在应用程序二进制接口( ABI)中,是通过栈来传递所有参数的。实际上,优化编译器会将频繁使用的变量分配于寄存器中,或者索性将变量彻底剔除。此外,一些 ABI 需要通过寄存器,而不是栈,来传递函数实参和结果。
尽管如此,本例只是意在展示 C 语言变量和进程各段间的映射关系。
虽然 SUSv3 未作规定,但在大多数 UNIX 实现(包括 Linux)中 C 语言编程环境提供了 3个全局符号:etext、 edata 和 end,可在程序内使用这些符号以获取相应程序文本段、初始化数据段和非初始化数据段结尾处下一字节的地址。使用这些符号,必须显式声明如下:
extern char etext,edata,end;
图 6-1 展示了各种内存段在 x86-32 体系结构中的布局,该图的顶部标记为 argv、 environ的空间用来存储程序命令行实参和进程环境列表,图中十六进制的地址会因内核配置和程序链接选项差异而有所不同。图中标灰的区域表示这些范围在进程虚拟地址空间中不可用,也就是说,没有为这些区域创建页表

6.4 虚拟内存管理
上述关于进程内存布局的讨论忽略了一个事实:这一布局存在于虚拟内存中。因为对虚拟内存的理解将有助于后续对诸如 fork()系统调用、共享内存和映射文件之类主题的阐述,所以这里将探讨一些有关虚拟内存的详细内容。 Linux,像多数现代内核一样,采用了虚拟内存管理技术。该技术利用了大多数程序的一个典型特征,即访问局部性( locality of reference),以求高效使用 CPU 和 RAM(物理内存)资源。大多数程序都展现了两种类型的局部性。
1.空间局部性( Spatial locality):是指程序倾向于访问在最近访问过的内存地址附近的内存(由于指令是顺序执行的,且有时会按顺序处理数据结构)。
2.时间局部性( Temporal locality):是指程序倾向于在不久的将来再次访问最近刚访问过的内存地址(由于循环)。
正是由于访问局部性特征,使得程序即便仅有部分地址空间存在于 RAM 中,依然可能得以执行。 虚拟内存的规划之一是将每个程序使用的内存切割成小型的、固定大小的“页”( page)单元。相应地,将 RAM 划分成一系列与虚存页尺寸相同的页帧。
任一时刻,每个程序仅有部分页需要驻留在物理内存页帧中。这些页构成了所谓驻留集( resident set)。程序未使用的页拷贝保存在交换区(swap area)内—这是磁盘空间中的保留区域,作为计算机 RAM 的补充—仅在需要时才会载入物理内存。若进程欲访问的页面目前并未驻留在物理内存中,将会发生页面错误( page fault),内核即刻挂起进程的执行,同时从磁盘中将该页面载入内存。
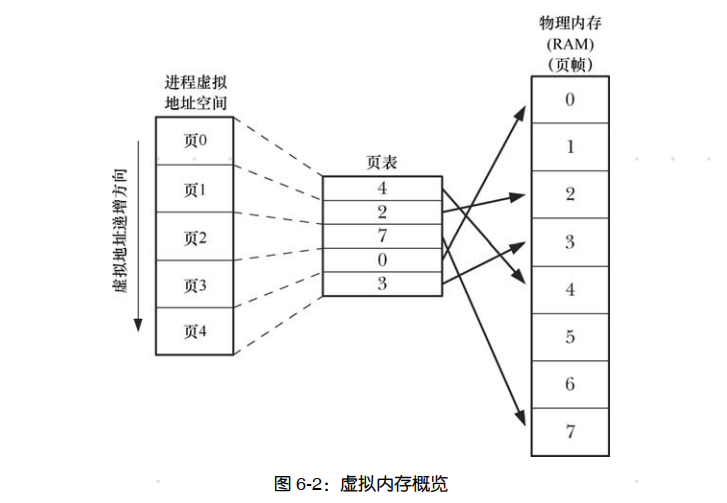
为支持这一组织方式,内核需要为每个进程维护一张页表( page table)(见图 6-2)。该页表描述了每页在进程虚拟地址空间( virtual address space)中的位置(可为进程所用的所有虚拟内存页面的集合)。页表中的每个条目要么指出一个虚拟页面在 RAM 中的所在位置,要么表明其当前驻留在磁盘上。
在进程虚拟地址空间中,并非所有的地址范围都需要页表条目。通常情况下,由于可能存在大段的虚拟地址空间并未投入使用,故而也无必要为其维护相应的页表条目。若进程试图访问的地址并无页表条目与之对应,那么进程将收到一个 SIGSEGV 信号。 由于内核能够为进程分配和释放页(和页表条目),所以进程的有效虚拟地址范围在其生命周期中可以发生变化。这可能会发生于如下场景。
1.由于栈向下增长超出之前曾达到的位置。
2.当在堆中分配或释放内存时,通过调用 brk()、 sbrk()或 malloc 函数族来提升堆顶的位置。
3.当调用 shmat()连接 System V 共享内存区时, 或者当调用 shmdt()脱离共享内存区时
4.当调用 mmap()创建内存映射时,或者当调用 munmap()解除内存映射时
虚拟内存管理使进程的虚拟地址空间与 RAM 物理地址空间隔离开来,这带来许多优点。
1.进程与进程、进程与内核相互隔离,所以一个进程不能读取或修改另一进程或内核的内存。这是因为每个进程的页表条目指向 RAM(或交换区)中截然不同的物理页面集合。
2.适当情况下,两个或者更多进程能够共享内存。这是由于内核可以使不同进程的页表条目指向相同的 RAM 页。内存共享常发生于如下两种场景。
2.1执行同一程序的多个进程,可共享一份(只读的)程序代码副本。当多个程序执行相同的程序文件(或加载相同的共享库)时,会隐式地实现这一类型的共享。
2.2进程可以使用 shmget()和 mmap()系统调用显式地请求与其他进程共享内存区。这么做是出于进程间通信的目的。
3.便于实现内存保护机制;也就是说,可以对页表条目进行标记,以表示相关页面内容是可读、可写、可执行亦或是这些保护措施的组合。多个进程共享 RAM 页面时,允许每个进程对内存采取不同的保护措施。 例如, 一个进程可能以只读方式访问某页面,而另一进程则以读写方式访问同一页面。
4.程序员和编译器、链接器之类的工具无需关注程序在 RAM 中的物理布局。
5.因为需要驻留在内存中的仅是程序的一部分,所以程序的加载和运行都很快。而且,一个进程所占用的内存(即虚拟内存大小)能够超出 RAM 容量。
虚拟内存管理的最后一个优点是:由于每个进程使用的 RAM 减少了, RAM 中同时可以容纳的进程数量就增多了。这增大了如下事件的概率:在任一时刻, CPU 都可执行至少一个进程,因而往往也会提高 CPU 的利用率。
6.5 栈和栈帧
函数的调用和返回使栈的增长和收缩呈线性。栈驻留在内存的高端并向下增长。专用寄存器—栈指针( stack pointer),用于跟踪当前栈顶。每次调用函数时,会在栈上新分配一帧,每当函数返回时,再从栈上将此帧移去
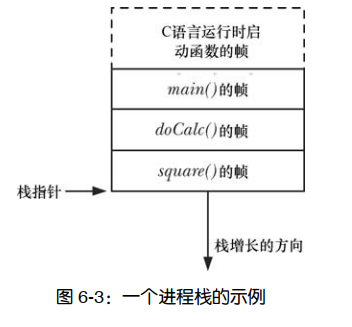
有时,会用用户栈(user stack)来表示此处所讨论的栈,以便与内核栈区分开来。内核栈是每个进程保留在内核内存中的内存区域,在执行系统调用的过程中供(内核)内部函数调用使用。 每个(用户)栈帧包括如下信息。
1.函数实参和局部变量:
由于这些变量都是在调用函数时自动创建的,因此在 C 语言中称其为自动变量。函数返回时将自动销毁这些变量(因为栈帧会被释放),这也是自动变量与静态(以及全局)变量主要的语义区别:后者与函数执行无关,且长期存在。
2.(函数)调用的链接信息:
每个函数都会用到一些 CPU 寄存器,比如程序计数器,其指向下一条将要执行的机器语言指令。 每当一函数调用另一函数时,会在被调用函数的栈帧中保存这些寄存器的副本,以便函数返回时能为函数调用者将寄存器恢复原状。