原文地址:http://www.reigndesign.com/blog/love-hotels-and-unicode/
讲得挺通俗的一篇文章
On Sunday 28 October I attended Shanghai Barcamp 9, organised byTechYizu. It was great to catch up with everyone in the local tech scene. Barcamps are "unconferences", meaning anyone can show up without registering, and give a talk on a geeky topic of their choice.
Here's my talk from the event, on love hotels and Unicode.

A few years ago in rural Henan province, a farmer was ploughing in his field, when suddently he hit a big rock in the ground. He pulled it out with the help of some other farmers, and they washed away the accumulated dirt, trying to see if there was anything engraved on the surface of the stone. But they couldn't see anything.

Then someone had the bright idea of turning the stone over. And they discovered ASCII.

Yes! China invented ASCII! Hold on, I may have got my history mixed up slightly.
ASCII was actually invented in the US in the 1960s, as a standardised way of encoding text on a computer. ASCII defined 128 characters, that's a character for half of the 256 possible bytes in an 8-bit computer system. Characters included A-Z, small a-z, numbers, a few common punctuation symbols, and control characters.
As computer usage became more widespread, ASCII wasn't really enough. To encode all the characters found in common Western languages, such as an à for French, or a ß for German, new standards emerged. ISO 8859-1 was used for Western languages and encoded these characters between bytes 128-255. In Russia a different set of characters was needed, so Cyrillic letters were encoded in bytes 128-255 in the standard ISO-8859-5. In Israel, Hebrew characters, and so on.
In Asia, the situation was even more complex. 256 characters clearly wasn't enough to write Japanese, or Chinese. So double byte character sets evolved, where each character was represented by two bytes. Even then, there were competing standards promulgated by Mainland China, Taiwan, Hong Kong, Singapore, Japan, and so on.

Things started to reach a crisis point as the Internet became widespread. People would send an email, but unless the recipient had the right character set, they would see gibberish on their screen. And you couldn't write a text document which contained both Chinese and Japanese, or even both Simplified and Traditional characters.
What was needed was a character set that could grow to encompass all characters from all languages. What was needed was Unicode.

Unicode is, on the surface, a simple system. Every character, or to be more exact, every "grapheme", is assigned a Unicode code point. It gets a number - for example in hex, this is Unicode code point 4B - a name - LATIN CAPITAL LETTER K, and an example of how to render it.

Here's a Greek letter theta, character 3B8. Notice we're already above FF (256).

A Unicode code point doesn't tell us exactly how to render a character - that's up to font designers. The two common variants of small letter a are still the same code point, 61.

Non-European languages are represented, here's an Arabic letter at 642.

Unicode, a great system in theory.

And because language and cultural issues are so important to many people in many countries, you ended up with some of the geekiest and oddest arguments ever to grace the Internet. I'm going to cover 5 of these petty squabbles in the rest of my talk.
First up, Unicode encodings. Now, Unicode defines an abstract number for each character. What it doesn't do is tell you how to convert those into bytes. And there quickly sprung up multiple different ways to encode Unicode.
Historically most character encodings were fixed width. Each character was encoded as 1 or 2 bytes. Because Unicode has so many characters, that wasn't enough. So the UTF-32 system, for example, encoded each character as 4 bytes (32 bits). That's enough for 256*256*256*256 characters, which is more than enough for most human writing systems. But UTF-32 is very verbose. Every character takes up 4 bytes, so the file size of a text file is pretty large.

So, more compact encodings became more popular - UTF-16, which underlies the text system in many operating systems, and UTF-8, the most popular character encoding on the modern Internet. Let's take a closer look at how UTF-8 works.
For any Unicode code point up to 7 bits (0-127), it can be encoded in a single byte. One nice effect of this, is that the UTF-8 representation of a ASCII string is exactly the same as in ASCII. Unicode code points up to 11 bits, such as the Greek and Arabic characters we saw above, can be encoded into 2 bytes. Almost all common Chinese characters can fit into 3 bytes.

The second point of contention was endianness. The word endianness comes from Jonathan Swift's satirical book Gulliver's Travels. In the book, the people of Lilliput and their neighbors at Blefuscu have a long-running feud over whether to crack their soft-boiled egg at the big end or the small end.
An equally silly argument ensued over how to encode sequences of bytes. For encodings such as UTF-16 where each character encodes as two bytes, should the "most significant" or "least significant" byte be encoded first?

A ham-fisted attempt to solve this problem was the "Byte Order Mark", Unicode FEFF. As you can see, it should be invisible.

Depending whether you're using UTF-8, UTF-16 big endian or UTF-16 little endian, it is encoded as a different set of bytes. The ideas was you'd add this as the first character in a text file, and this would tell the intepreter which endianness you were using.

However, there were still many non-Unicode-aware text processing systems out there, and the BOM caused far more confusion than it solved. PHP would sometimes output the BOM to the browser, then raise warnings when you tried to write an HTTP header to the page.
If you've ever opened a text file and seen the symbols  at the top, you're seeing an ISO-8859-1 representation of the three bytes of a UTF-8 encoded BOM. Needless to say, this is wrong. BOMs are optional, and deleting the stray bytes will usually solve the problem!
The third big argument was Han Unification. The characters we know in Chinese as hanzi are also used in other Asian languages. In Japanese they're called kanji, in Korean they are hanja.

And so a single "Chinese" character can have different meanings, and sometimes even different renderings, in different Asian languages. Chinese-Japanese-Korean "CJK" characters in Unicode are given generic names.

This character, for "grass", is written in one way in Chinese. But in Japanese, it's often written in a slightly different way, with the radical at the top broken in two. Should the Japanese and Chinese versions of this character be unified into a single Unicode code point?

If we allowed that, what about the many, many, other variations of characters. Here are just a few grass radicals that have been used in modern and historical scripts!

Even after all common Chinese, Japanese and Korean characters had been argued over, standardised and added to Unicode, the arguing continued.
In recent years, there's been an effort to add Emoji to Unicode. What are Emoji? They're small pictures that the three big Japanese mobile phone characters allow their users to embed into SMS messages.

Here are some examples from two of the carriers. There are hundreds of icons: smileys, food, animals, places... And the systems implemented by the three carriers weren't compatible with each other.

Companies like Apple, Microsoft and Google were keen to provide products that supported Emoji across carriers. So a Unicode Consortium subcommiteeincluding representatives of some of these companies, as well as national and international standards bodies, met to try to standardise Emoji and add them to Unicode.
There were really important discussions about characters like WOMAN WITH BUNNY EARS:

And of course, LOVE HOTEL

Not forgetting the versatile PILE OF POO.

The discussions around some of the characters were even more entertaining. Japan had much to say about noodles.

Ireland stood up for gay rights.

While Germany rejected racial stereotyping:

We saw the same arguments about unification of characters. Was FACE WITH STUCK OUT TONGUE significantly different to FACE WITH STUCK OUT TONGUE AND WINKING EYE?
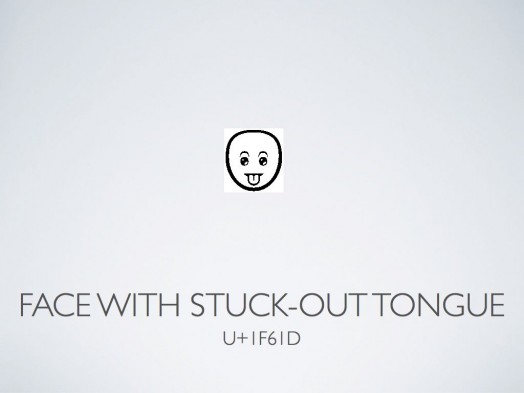

After a mere two-and-a-half years of debate, most of the disputes were resolved and hundreds of Emoji characters were encoded in Unicode Version 6.0.
The one remaining argument was flags.

In the carrier Emoji symbols, 10 countries had representations of their national flags encoded. Quickly, other countries - Canada, Ireland - began complaining that they too should get a character for their flag. Should every country get a flag in Unicode? Was it the Unicode Consortium's job to decide what was an wasn't a country? Should Taiwan get a flag?
The situation had the potential to become technically and politically messy. So, a compromise was formed in the shape of the "regional indicator symbols", 26 Unicode code points in the range 1F1E6 to 1F1FF. Rendered normally they look something like this, a letter in a box.

Clients (like operating systems, or web browsers) that encounter regional indicator symbols may render combinations of two regional indicator symbols as a national flag matching that country's 2-letter ISO country code.
For example, this is a valid representation of these two characters:

But an implementor may choose to render it instead like this!

And with that, I'll leave you with a WAVING HAND SIGN
