MYSQL-innodb性能优化几个点
数据库常用参数
MYSQL数据库的参数配置一般在my.ini配置(部分参数也可以用set global 参数名=值 做临时调整,重启后失效),配置完后需要重启数据库才生效。
参数1:slow_query_log = 0|1
说明:开关慢查询日志。slow_query_log_file=为存放路径;long_query_time =记录超过的时间,默认为10s。
参数2:join_buffer_size = MB
说明:join buffer存放基于每thread的连接表信息,连接时,只需访问join buffer,不需要再去有并发机制保护的cache.
参数3:Sort_Buffer_Size = MB
说明:Sort_Buffer_Size 是一个connection级参数,每个connection第一次需要使用这个buffer的时候,一次性分配设置的内存。Sort_Buffer_Size 并不是越大越好,由于是connection级的参数,过大的设置+高并发可能会耗尽系统内存资源。官网文档说“On Linux, there are thresholds of 256KB and 2MB where larger values may significantly slow down memory allocation”
参数4: binlog_format = STATEMENT|ROW|MIXED
说明:日志格式
1)STATEMENT模式(SBR)
每一条会修改数据的sql语句会记录到binlog中。优点是并不需要记录每一条sql语句和每一行的数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题)。
2)ROW模式(RBR)
不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨。
3)MIXED模式(MBR)
以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
参数5:binlog_cache_size = MB
说明:默认大小是37268即32K.根据事务需要调整大小。该参数表示在事务中容纳二进制日志sql语句的缓存大小。二进制日志缓存,是服务器支持事务存储引擎并且服务器启用了二进制日志(-log-bin选项)的前提下为每个客户端分配的内存,是每个client都可以分配设置大小的binlog cache空间。
参数6:Max_binlog_cache_size = MB
说明:默认值是18446744073709547520,这个值很大,够我们使用的了。此参数和binlog_cache_size相对应,代表binlog所能使用的cache最大使用大小。如果系统中事务过多,而此参数值设置有小,则会报错。
参数7:Max_binlog_size = GB/MB
说明:Max_binlog_size: 1073741824=1G ,binlog的最大值,一般设置为512M或1G,一般不能超过1G。此参数不能非常严格控制binlog的大小,特别是在遇到大事务时,而binlog日志又到达了尾部,为了保证事务完整性,不切换日志,把所有sql都写到当前日志。
参数8:expire_logs_days = N
说明:设置binlog老化日期;有大致三种情况引发日志切换:binlog大小超过max_binlog_size;手动执行flush logs;重新启动时(MySQL将会new一个新文件用于记录binlog)
参数9:innodb_file_per_table = 0|1
说明:参数值为1,表示对每张表使用单独的 innoDB 文件
参数10:innodb_log_file_size = GB/MB
说明:对 Innodb 数据表有大量的写入操作,那么选择合适的 innodb_log_file_size 值对提升MySQL性能很重要;值太大了会让恢复过程变慢.
参数11:innodb_log_files_in_group = N
说明:该变量控制日志文件数。默认值为2。日志是以顺序的方式写入。
参数12:innodb_flush_method =
说明:设置InnoDB同步IO的方式:Default (fsync);O_SYNC (以sync模式打开文件,通常比较慢);O_DIRECT(在Linux上使用Direct IO。可以显著提高速度,特别是在RAID系统上。避免额外的数据复制和double buffering(mysql buffering 和OS buffering))
参数13:transaction_isolation = READ-UNCOMMITTED | READ-COMMITTED |REPEATABLE-READ | SERIALIZABLE
说明:设定事务隔离级别
1)未提交读(Read Uncommitted):允许脏读,也就是可能读取到其他会话中未提交事务修改的数据
2)提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)
3)可重复读(Repeated Read):可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻象读
4)串行读(Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞
参数14:character-set-server = utf8|utf8mb4
说明:设定字符集,utf8存3个字节,utf8mb4存4个字节。
参数15:innodb_buffer_pool_size = Gb/MB
说明:此参数类似于oracle的SGA配置,当主机做为mysql数据库服务器时,一般配置为整机内存的60%~80%。
参数16:innodb_buffer_pool_instances=N
说明:内存缓冲池实例数,将innodb_buffer_pool_size配置的内存分割成N份,此参数当配置内存大小于1G时才生效,当数据库有多个会话进行数据库操作时,用于并行在多个内存块中处理任务,一般配置值《=服务器CPU的个数。
参数17:max_connections = xxxx
说明:最大连接数,当数据库面对高并发时,这个值需要调节为一个合理的值,才满足业务的并发要求,避免数据库拒绝连接。
参数18:max_user_connections=xxxx
说明:设置单个用户的连接数。
参数19:innodb_log_buffer_size =xxxxx
说明:日志缓冲区大小,一般不用设置太大,能存下1秒钟操作的数据日志就行了,mysql默认1秒写一轮询写一次日志到磁盘。
参数20:innodb_flush_log_at_trx_commit =
说明:(这个配置很关键)一般的实时业务交易配置为2,取值0,1,2
0:数据操作时,直接写内存,并不同时写入磁盘;
2:数据操作时,直接写内存,并不同时写入磁盘;
1:就每个事务提交就会要刷新到磁盘后才算提交完成,这种情况是保证了事务的一致性,但性能会有很大的影响。
0与2的区别:
0:当mysql挂了之后,可能会损失前一秒的事务信息
2:当mysql挂了之后,如果系统文件系统没挂,不会有事务丢失。
参数21:innodb_read_io_threads = xxxx
说明:数据库读操作时的线程数,用于并发。
参数22:innodb_write_io_threads = xxx
说明:数据库写操作时的线程数,用于并发。
参数23:innodb file per table= 1
说明:每一个表是否使用独立的数据表空间,默认为OFF(使用共享表空间),一般建议配置为1,InnoDB 默认会将所有的数据库InnoDB引擎的表数据存储在一个共享空间中:(ibdata1),这样就感觉不爽,增删数据库的时候,ibdata1文件不会自动收缩,
单个数据库的备份也将成为问题。通常只能将数据使用mysqldump 导出,然后再导入解决这个问题。
共享表空间在Insert操作上少有优势。其它都没独立表空间表现好,如果数据库基本上都插入操作则配置为0。
参数24:innodb_stats_on_metadata={ OFF|on}
说明:是否动态收集统计信息,开启时会影响数据库的性能(一般关闭,找个时间手动刷新,或定时刷新)如果为关闭时,需要配置数据库调度任务,定时刷新数据库的统计信息。
参数25:innodb_spin_wait_delay=xxxxx
说明:控制CPU的轮询时间间隔,默认是6,配置过低时,任务调度比较频繁,会消耗CPU资源。
参数26:innodb_lock_wait_timeout=xxxx
说明:控制锁的超时时间,默认为50,这个值要注意,如果有特殊业务确实要耗时较长时,不能配置太短。
具体的调优参数内容较多,可参考官方文档,一些比较重要的参数:
back_log:back_log值指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。也就是说,如果MySql的连接数据达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。可以从默认的50升至500
wait_timeout:数据库连接闲置时间,闲置连接会占用内存资源。可以从默认的8小时减到半小时
max_user_connection: 最大连接数,默认为0无上限,最好设一个合理上限
thread_concurrency:并发线程数,设为CPU核数的两倍
skip_name_resolve:禁止对外部连接进行DNS解析,消除DNS解析时间,但需要所有远程主机用IP访问
key_buffer_size:索引块的缓存大小,增加会提升索引处理速度,对MyISAM表性能影响最大。对于内存4G左右,可设为256M或384M,通过查询show status like 'key_read%',保证key_reads / key_read_requests在0.1%以下最好
innodb_buffer_pool_size:缓存数据块和索引块,对InnoDB表性能影响最大。通过查询show status like 'Innodb_buffer_pool_read%',保证 (Innodb_buffer_pool_read_requests – Innodb_buffer_pool_reads) / Innodb_buffer_pool_read_requests越高越好
innodb_additional_mem_pool_size:InnoDB存储引擎用来存放数据字典信息以及一些内部数据结构的内存空间大小,当数据库对象非常多的时候,适当调整该参数的大小以确保所有数据都能存放在内存中提高访问效率,当过小的时候,MySQL会记录Warning信息到数据库的错误日志中,这时就需要该调整这个参数大小
innodb_log_buffer_size:InnoDB存储引擎的事务日志所使用的缓冲区,一般来说不建议超过32MB
query_cache_size:缓存MySQL中的ResultSet,也就是一条SQL语句执行的结果集,所以仅仅只能针对select语句。当某个表的数据有任何任何变化,都会导致所有引用了该表的select语句在Query Cache中的缓存数据失效。所以,当我们的数据变化非常频繁的情况下,使用Query Cache可能会得不偿失。根据命中率(Qcache_hits/(Qcache_hits+Qcache_inserts)*100))进行调整,一般不建议太大,256MB可能已经差不多了,大型的配置型静态数据可适当调大.
可以通过命令show status like 'Qcache_%'查看目前系统Query catch使用大小
read_buffer_size:MySql读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySql会为它分配一段内存缓冲区。如果对表的顺序扫描请求非常频繁,可以通过增加该变量值以及内存缓冲区大小提高其性能
sort_buffer_size:MySql执行排序使用的缓冲大小。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。如果不能,可以尝试增加sort_buffer_size变量的大小
read_rnd_buffer_size:MySql的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,MySql会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySql会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大。
record_buffer:每个进行一个顺序扫描的线程为其扫描的每张表分配这个大小的一个缓冲区。如果你做很多顺序扫描,可能想要增加该值
thread_cache_size:保存当前没有与连接关联但是准备为后面新的连接服务的线程,可以快速响应连接的线程请求而无需创建新的
table_cache:类似于thread_cache_size,但用来缓存表文件,对InnoDB效果不大,主要用于MyISAM
执行计划分析
mysql> EXPLAIN SELECT * FROM smssendbak;
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | smssendbak | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 100.00 | NULL |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-------+
说明:
Table:表名称
Type:重要的一列,显示使用了何种连接,从好到差依次为const、eq_ref、ref、range、index、all,下面详细说明:
type的描述:
System:表只有一行,这是const连接类型的特例;
Const:表中一个记录的最大值能够匹配这个查询(索引可以是主键或唯一索引)。因为只有一行,这个值实际就是常数,因为mysql先读这个值,再把它当作常数对待
eq_ref:从前面的表中,对每一个记录的联合都从表中读取一个记录。在查询使用索引为主键或唯一索引的全部时使用;
Ref:只有使用了不是主键或唯一索引的部分时发生。对于前面表的每一行联合,全部记录都将从表中读出,这个连接类型严重依赖索引匹配记录的多少-越少越好;
Range:使用索引返回一个范围中的行,比如使用>或<查找时发生;
Index:这个连接类型对前面的表中的每一个记录联合进行完全扫描(比all好,因为索引一般小于表数据);
All:这个连接类型多前面的表中的每一个记录联合进行完全扫描,这个比较糟糕,应该尽量避免。
possible_keys:可以应用在这张表中的索引,如果为null,则表示没有可用索引;
Key:实际使用的索引,如为null,表示没有用到索引;
key_len:索引的长度,在不损失精确度的情况下,越短越好;
Ref:显示索引的哪一列被使用了,如果可能的话,是个常数;
Rows:返回请求数据的行数;
Extra:关于mysql如何解析查询的额外信息,下面会详细说明。
extra行的描述:
distinct-mysql找到了域行联合匹配的行,就不再搜索了;
not exists-mysql优化了left join,一旦找到了匹配left join的行,就不再搜索了;
range checked for each-没找到理想的索引,一次对于从前面表中来的每一个行组合;
record(index map: #)-检查使用哪个索引,并用它从表中返回行,这是使用索引最慢的一种;
using filesort-看到这个就需要优化查询了,mysql需要额外的步骤来发现如何对返回的行排序。他根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行.
using index-列数据是从单使用了索引中的信息而没有读取实际行的表返回的,这发生在对表的全部的请求列都是同一个索引时;
using temporary-看到这个就需要优化查询了,mysql需要创建一个临时表来查询存储结果,这通常发生在多不同的列表进行order by时,而不是group by;
where used-使用了where从句来限制哪些行将与下一张表匹配或是返回给用户。如不想返回表中用的全部行,并连接类型是all或index,这就会发生,也可能是查询有问题。
SQL语句优化:注意SQL语句的书写规则,where条件,order by ,group by ,having , in ,like ,jion on,表顺序,聚合函数的使用,子查询等。
索引优化
1、是否有无重复索引
2、索引字段类型,顺序是否合理
3、是否有无用索引
4、索引利用率
表结构优化
1、表的字段类型是否合理
2、数据是否冗余
3、根据业务规则建立合理的约束
4、建表时,尽量使字段值不为空(加not null约束),索引列值尽量离散(不重复)
5、不常用的字段列可适当考虑折分表
6、数据量较大的表,有存储时间,IP地址数据时,转为int ,bigint
INT类型的时间数据转换:
UNIX_TIMESTAMP('2015-01-10 12:00:00') 转int(插入数据时)
FROM_UNIXTIME(时间字段) 取时间字段的值
IP地址数据操作转换:
INET_ATON :IP地址转bigint (inet_aton(192.168.1.1))
INET_NTOA :BIGINT转IP地址(inet_ntoa(ip地址字段))
注:在mysql中int ,比varchar处理要简单,尽量少使用text类型
数据库主机参数优化
网络:(/etc/security/sysctl.conf)
net.ipv4.tcp_keepalive_time = 1200
说明:表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟。
net.ipv4.ip_local_port_range = 10000 65000
说明:表示用于向外连接的端口范围,一般低位端口不要设置太低,有可能会用到其它程序固定的端口
net.ipv4.tcp_max_syn_backlog = 65535
说明:表示SYN队列的长度,默认为1024,加大队列长度为65535,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_tw_buckets = 5000
说明:示系统同时保持TIME_WAIT的最大数量,如果超过这个数字,TIME_WAIT将立刻被清除并打印警告信息。默 认为180000,避免被大量的timewait拖死。
net.ipv4.tcp_syncookies = 1
说明:表示开启SYN Cookies
net.ipv4.tcp_tw_reuse=1
说明:表示开启重用,允许将TIME-WAIT sockets重新用于新的TCP连接
net.ipv4.tcp_recycle=1
说明:表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭;
net.ipv4.tcp_fin_timeout=10
说明:修改系統默认的 TIMEOUT 时间。
limit.conf内核相关参数优化:
详见:《limits.conf详解》
vi /etc/security/limits.conf
limits.conf的格式如下:
<domain> <type> <item> <value>
或:username|@groupname type resource limit
username|@groupname:设置需要被限制的用户名,组名前面加@和用户名区别。也可以用通配符*来做所有用户的限制。
如:
type:有 soft,hard 和 -
soft 指的是当前系统生效的设置值
hard 表明系统中所能设定的最大值
soft 的限制不能比har 限制高
用 - 就表明同时设置了 soft 和 hard 的值。
resource:
core - 限制内核文件的大小
data - 最大数据大小
fsize - 最大文件大小
memlock - 最大锁定内存地址空间
nofile - 打开文件的最大数目
rss - 最大持久设置大小
stack - 最大栈大小
cpu - 以分钟为单位的最多 CPU 时间
noproc - 进程的最大数目
as - 地址空间限制
maxlogins - 此用户允许登录的最大数目
要使 limits.conf 文件配置生效,必须要确保 pam_limits.so 文件被加入到启动文件中。
查看 /etc/pam.d/login 文件中有:
session required /lib/security/pam_limits.so
暂时地:适用于通过 ulimit 命令登录 shell 会话期间。
永久地:通过将一个相应的 ulimit 语句添加到由登录 shell 读取的文件之一(例如 ~/.profile),即特定于 shell 的用户资源文件;或者通过编辑 /etc/security/limits.conf。
何谓core文件,当一个程序崩溃时,在进程当前工作目录的core文件中复制了该进程的存储图像。core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的。 core文件是个二进制文件,需要用相应的工具来分析程序崩溃时的内存映像。
系统默认core文件的大小为0,所以没有创建。可以用ulimit命令查看和修改core文件的大小。
$ulimit -c 0
$ ulimit -c 1000
$ ulimit -c 1000
-c 指定修改core文件的大小,1000指定了core文件大小。也可以对core文件的大小不做限制,如:
# ulimit -c unlimited
如果想让修改永久生效,则需要修改配置文件,如 .bash_profile、/etc/profile或/etc/security/limits.conf。
2.nofile - 打开文件的最大数目
[plain]
* soft nofile 10000 #软限制
* hard nofile 10000 #硬限制
对于需要做许多套接字连接并使它们处于打开状态的应用程序而言,最好通过使用 ulimit –n,或者通过设置nofile 参数,为用户把文件描述符的数量设置得比默认值高一些
vi /etc/security/limits.conf
用ulimit -n 2048 修改只对当前的shell有效,退出后失效:!!!!!!!!!!!!!!!!!
如A程序已经运行,此时ulimit -n为1024;之后ulimit -n 2048,这时在运行B程序;退出当前shell用户,再次进行shell,之后运行C程序;这时只有B程序用的是2048,其它用的都是1024.
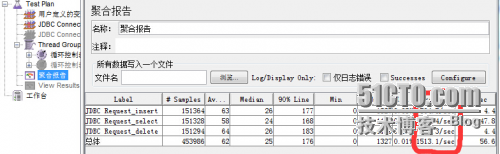
数据库参数调节效果对比
下列参数配置测试结果对比。
innodb_buffer_pool_size = 1024M
innodb_buffer_pool_instances = 4
max_connections = 2000
max_user_connections = 2000
innodb_flush_log_at_trx_commit = 2
innodb_write_io_threads = 16
innodb_read_io_threads = 16
innodb_spin_wait_delay = 10
innodb_lock_wait_timeout = 30
更改前:增查删操作通过jmeter测试每秒只有80.8笔。

更改后:增查删操作通过jmeter测试每秒达到1513.1笔。