集成学习二: Boosting
引言
集成学习,的第二种方式称为Boosting. 不同于bagging的民主投票制, 其采用的是"精英"投票制.也即不同的分类器具有不同的权重, 显然,分类效果好的分类器权重会更大些,反之,权重会小些. 这就是Boosting 的基本思想. 从偏倚-方差的角度, boosting 优化的是偏差.
目前,Boosting 集成学习是非常的红火, 就在2016年末, 微软发布了其boosting框架, 三天github 超过1000星! 号称比当比陈天奇的Xgboost 还要快的boosting 算法.
在Xgboost 出现之前, adaboost 是最具代表性的boosting 算法, 其是 gradient boosting 的一个特例. gbdt(gradient boosting decision tree) 是gradient boosting中名声最大的, 然而Xgboost的出现,一时风头无两, 大有一统江胡之势, 直到 lightGBM的出现… 本文将以这个路线介绍boosting算法(Xgboost, lightGBM另开博文).
Adaboost
Adaboost 是Adaptive boosting 的合成词(又是合成词, 真是集成学习啊, 连名字都合成, 汗~).
Adaboost 的思想很直观:
-
多种基学习器集成学习, 最后投票, 根据每个基学习器的准确度对其投票权赋予权重, 最终得到结果, 这是adaboost 里的boosting 的含义.
-
adaboost还有一个词是adaptive(适应的), 那这个适应性如何来体现呢, 或者说为什么要引入适应性呢? 从boosting的思想可知基分类器之间是相互独立的, 互不影响, 这是会造成信息浪费的: 前一个分类器训练完成后, 其实是可以对后前的分类器作出指导的, 即后面的基学习器可以根据前面基学习器的''经验''为自身的性能提供指导的.
如何指导呢? 我们可以被前一个基学习器错误分类的样本个体给予更多的关注, 而对已经被正确分类的样本个体适当地降低关注. 这样之前错误分类的样本个体在新的基学习器中被分类正确的可能性就会大大提升. 这就是适应性.
Adaboost 算法
明确下目标, 我们希望根据训练数据,及多个弱分类器(基(分类)学习器), 最终得到一个很强大的分类器:
-
输入:
- 训练样本集: $T = {(x_1,y_1),(x_2,y_2),dots,(x_N,y_N)},quad xin mathscr{X}subseteq R^n $, 其中 x是n 维的向量, (mathscr{X})是其向量空间, $ y in {+1,-1}$.
- M 个基(分类)学习器 (B = {b_1(x),b_2(x),dots,b_M(x)}).
-
输出: 最终的强分类器: G(x).
-
过程:
- 初始化权值分布. 这里因为没有其他参考信息, 故假设每个样本个体的权重是一致的:
[D_1 = {w_{1,1},w_{1,2},dots,w_{1,N}}, quad w_{1,i}= frac{1}{N},quad i=1,2,dots,N. ] 其中D_1 表示在第1个学习器学习之前样本的权值分布.
- 对每个基学习器进行训练.此过程中每轮都要更新样本权重,而且也要根据每个基学习器的准确度对其最终投票权赋予权重.
for m in {1到M}:
a. 训练基学习器(b_m):
[b_m(x):mathscr{X} ightarrow {+1,-1} ] 这里要强调地是样本集中的样本权重分布是 (D_m),即:
[D_1 = {w_{m,1},w_{m,2},dots,w_{m,N}}, quad i=1,2,dots,N. ] b. 对基学习器的投票权进行赋权.
如上所述, 基学习器的投票权重取决于其准确度, 或角换个角度, 取决于误差率.
即误差率越高的权重越低, 反之,权重越大. 误差率:
[e_m = P(b_m(x) e y)=sum_{i =1}^N w_{mi}cdot I_{{b_m(x_i) e y_i}} ] 为个让误差率可以表示基学习器的权重, 需要做一些变换,这里有个trick(后面
会知道, 这个trick后背是有原因的), (b_m(x))的权重 (alpha_m) 可表示为:
[alpha_m = frac{1}{2} logfrac{1-e_m}{e_m} ] 注意,这里的误差取值是不为0, 且也不能大于0.5的. 这个是非常自然的, 不为0
表示的是此基学习器的分类准确度不能达到100%, 这个是显然的,否则也不用
集成学习了, 更不能被称为弱分类器了; 不大于0.5 的意思是说其分类器的效果
好于随机猜测(瞎猜,期望为0.5), 这个也是显然的, 如果连瞎猜都不如, 用这个为
类器还不如不用.
c. 更新训练集中每个个体的权值分布.
[D_{m+1} = {w_{m+1,1},w_{m+1,2},dots w_{m+1,N}} ] 其中:
[w_{m+1,i} = frac{w_{m,i}}{Z_m}exp(-alpha_mcdot y_icdot b_m(x_i)) ] 其中:
[Z_m = sum_{i = 1}^N w_{m,i}cdot exp(-alpha_mcdot y_icdot b_m(x_i)) ] 也即归一化因子.
如前所述, 更新权值的逻辑是对错误分类样本个体提升权重, 而对正确分类样本
个体降低权重, 因为(y subseteq{+1,-1}) 因此错误分类的样本个体一定存在如下关
系:
[y_icdot b_m(x_i ) = -1 ] 为了对错误样本提升权重, 须在前面加个负号(这就是(8)式中负号的由来(因为
指数函数是单调递增函数啊~)). 而上升下降的步长则由基学习器的性能决定,表
现为(alpha) 决定, 这就是(8)式中 (alpha)的由来.
3). 构建最终分类器:
最终分类器是由以上训练的 M 个分类器组合而成的, 且因为类别只有两类(+1, -1).
则最终根据投票的结果的符号即可得到 最终比较好的分类效果:
[G(x) = signleft(sum_{m = 1}^M alpha_mcdot b_m(x) ight) ] 令:
[f(x) = sum_{m = 1}^M alpha_mcdot b_m(x) ] 则:
[G(x) = sign(f(x)) ]
这就是Adaboost 算法.
前向分步算法
上面介绍的 Adaboost 算法,是前向分步算法的一个特例, 从这个角度, Adaboost 可以解释为 模型是加法模型, 损失函数为指数函数, 学习算法为前向分步算法的二分类学习算法. 现在从更加一般的角度来探讨一下boosting.
boosting 的 最终目的即是使算法或模型的准确更高,或者说其误差率达到最低:
其中 f(x) 即是所要找的最终分类器(如上面的G(x)). 其可表示成:
其中 b(x) 是基学习器, w是其权重; (L(y,hat{y})) 是损失函数. 根据不同的损失函数产生不同的算法:
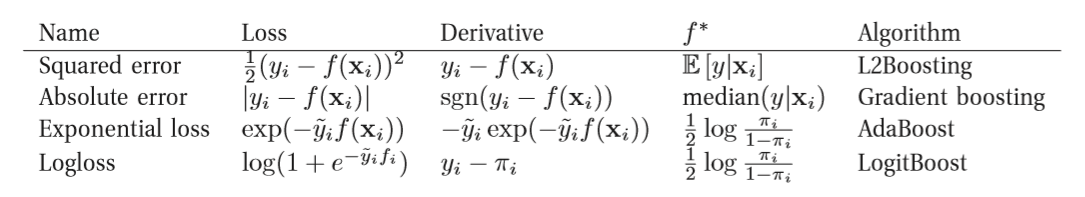
表1 (引自 Machine learning: A probabilistic perspective)
注: 上表中 ( ilde{y}in {+1,-1}, yin {0,1}, pi = 2cdot sigmoid(f(x)).)
最小化损失函数是一个非常复杂的优化问题, 不可能再其可行域内进行完全搜索. 因此这里用到的思想(trick) 就是前向分步思想: 因模型是一个广义加法模型, 可以从前向后,每步优少其中一个基学习器, 逐步优化目标函数, 就可降低问题复杂度,并达到一个令人满意的结果.
即每步只需优化如下损失函数:
前向分步算法
-
输入:
- 训练样本集: $T = {(x_1,y_1),(x_2,y_2),dots,(x_N,y_N)},quad xin mathscr{X}subseteq R^n $, 其中 x是n 维的向量, (mathscr{X})是其向量空间, $ y in {+1,-1}$.
- M 个基(分类)学习器 (B = {b_1(x),b_2(x),dots,b_M(x)}).
- 损失函数: L(y,f(x)).
-
输出: 加法模型 f(x).
-
算法过程:
1). 初始化 (f_0(x) = 0)
2). 逐步相加直到最终的f(x):
for m in (1,2,...,M):
a. 最小化损失函数,得到第 m 步的最优基学习器及其权重:
[(w_m, b_m(x)) = arg min_{w_m,b} sum_{i = 1}^N L(y_i, f_{m-1}(x_i) + w_m b(x)) ] b. 更新加法模型:
[f_m(x) = f_{m-1}(x) + w_mcdot b(x) ]4). 得到最终加法模型:
[f(x) ]
基学习器的数量(M) 一般人为给定, 有时M太大,会使模型最佳状态提早出现, 余下的训练过程会使模型的效果降低, 因此在上面的算法过程(2) b 步中, 给予模型一个衰减项(shrinkage):
其中 (gamma) 为衰减项.
Boosting Tree
boosting 算法 从其本身来看, 并没有限制一定是分类问题,还是回归问题,即boosting 是既可以应用于回归问题,也可以应用于分类问题. Adaboost 被认为是性能优越的二分类算法, 但其是可以解决回归问题的. 其中最具代表性是就是adaboost 的基学习器为决策树时的提升树算法. 提升树的做分类问题与上面别二致, 只不过基学习器固定为决策树而已, 不再赘述. 而对于回归问题, 这里描述一下:
回归树
回归树又叫分类回归树(Classfication and Regression Tree, CART), 其应用于回归问题与分类问题基本相同, 都是递归地构建二叉树的过程. 但不同于分类树的基尼系数(gini index) 最小化准则,回归树用平方误差最小化准则.
一个回归树对应着输入空间(即特征空间)的一个划分以及在划分单元上的输出值. 假设已将输入空间化分为 Q 个单元(R_1, R_2, dots, R_Q), 并且在每个单元(R_q)上有一个固定的输出值 (c_q), 于是回归树的模型可表示为:
当输入空间的划分确定时, 可以用平方误差来表示回归树对于训练数据的预测误差:
最小化上式, 可得出, (c_m)的最优估计值:
即第 q 个子空间的均值.
对于回归问题, 关键是如何对输入空间进行划分. 这是一个 NP 问题, 故采用CART启发式的方法, 选择第 j 个变量 (x^{(j)}) 及其 取值 s 作为划分变量(splitting variable) 和 划分点(splitting point), 并定义两个区域:
最优划分变量及划分点应该满足:
由上已知, 在j,s固定的情况下, c即为子划分区域内的均值,见 (22) 式. 这样遍历所有输入变量,找到最优的切分变量 j , 构成 一个对 (j, s), 将输入空间间划分成左右两个子空间, 递归的重复此过程, 直到满足终止条件为止, 这样就生成了一棵回归树, 这样的回归树也被称为最小二乘回归树.
算法:
-
输入: 训练集D
-
输出, 回归树.
-
递归过程:
1). 选择最优划分:
[min_{j,s}left[min_{c_L}sum_{x_iin R_L(j,s)}(y_i - c_R)^2+min_{c_R}sum_{x_iin R_R(j,s)}(y_i - c_R)^2 ight] ] 此过程遍历变量 j, 并对固定的变量 j 找到最优划分点 s .
2). 在每个子划分空间求解输出值 c:
[hat{c}_q = frac{sum_{i = 1}^Ny_icdot I_{{x_iin R_q}}}{sum_{i =1}^N I_{{x_iin R_q}}} ]3). 递归地重复 (1),(2);
-
将输入空间划分为 Q 个子空间, 生成回归树:
[t(x) = sum_{q = 1}^Q hat{c}_qcdot I_{(xin R_q)} ]
M 是子空间的个数, 因此也是叶子结点的个数(子空间最终都落在叶子结点上).
提升回归树
有了上一节的知识, 提升回归树就容易多了.
设回归树可表示为:
其中参数(Theta = {(R_1,c_1),cdots, (R_Q,c_Q)})
最终的模型 则可表示为:
其中 (f_m(x) = f_{m-1}(x) + T(x; Theta_m)).
在前向分步算法的第 m 步中, :
此即为第 m 棵树的最优参数.
当采用平方误差作为损失函数时:
在 第 m 步的损失可表示为:
其中:
即为第m 棵需要拟合的数据! 即前一步的残差.
算法过程:
-
输入: 数据集;
-
输出: 提升树 (f(x) = f_M(x));
-
前向分步过程:
1). 初始化 (f_0(x) = 0);
2). for i in (1到 M):
a. 计算残差: (r_{m,i} = y_i - f_{m-1}(x_i)quad i = 1,2,…,N);
b. 拟合残差 (r_{m,i}), 得到 (T_m(x; Theta_m));
c. 更新 f(x): (f_m(x) = f_{m-1} (x) + T(x; Theta_m));
-
得到提升树: (f(x) = sum_{m = 1}^M f_m(x) = sum_{m = 1}^M T(x; Theta_m)).
Gradient Boosting
梯度提升算法是大牛 Freidman 提出的boosting 算法框架,是结合了梯度下降算法的更一般的boosting 算法, 在这个框架内, 无论损失函数以何种形式, 都可以应用boosting. Gradient Boosting 的基本思想: 在前向分步算法的每一步中, 以负梯度方向作为新基学习器的拟合目标的近似. 这样的好处是不用担心损失函数的具体形式, 只要可以找到其可微就可以.
简述其关键改进:
1): 在m 步中, 损失函数对f(x)求梯度:
这即为下个基函数的拟合目标, 因此,在 m 步中,只需要考虑如下优化:
2): 更新 f(x)
其中 ( ho_m) 学习率(或称步长), 可通过线性搜索求得: ( ho_m = arg min_{ ho} L(f_{m-1} - ho g_m)). 但因其不是必须的, 故常取 1.
参考文献:
- 统计学习方法, 2012, 李航, 清华大学出版社;
- Machine learning: A Probablistic Perspective, 2012, Kevin P. Murphy, The MIT Press;
- The elements of statistical learning 2nd, 2009, Jerome Friedman et al, Spring
- Machine learning: A Bayesian and Optimization perspective, 2015, Sergios Theodoridis, Elsevier.
- Adaboost 算法的原理与推导, 2015, July, CSDN.