RIFF file format
RIFF全称为资源互换文件格式(Resources Interchange File Format),是Windows下大部分多媒体文件遵循的一种文件结构。RIFF文件所包含的数据类型由该文件的扩展名来标识,能以RIFF格式存储的数据有(包含有:):
(文件格式和数据格式是两码事情)
- 音频视频交错格式数据 .AVI
- 波形格式数据 .WAV
- 位图数据格式 .RDI
- MIDI格式数据 .RMI
- 调色板格式 .PAL
- 多媒体电影 .RMN
- 动画光标 .ANI
- 其他的RIFF文件 .BND
CHUNK
chunk是RIFF文件的基本单元,其基本结构如下:
struct chunk
{
uint32_t id; // 块标志
uint32_t size; // 块大小
uint8_t data[size]; // 块数据
};- id 4字节,用以标识块中所包含的数据。如:RIFF,LIST,fmt,data,WAV,AVI等,由于这种文件结构 最初是由Microsoft和IBM为PC机所定义,RIFF文件是按照小端 little-endian字节顺序写入的。
- size 块大小 存储在data域中的数据长度,不包含id和size的大小
- data 包含数据,数据以字为单位存放,如果数据长度为奇数(字节为单位),则最后添加一个空字节。
chunk是可以嵌套的,但是只有块标志为RIFF或者LIST的chunk才能包含其他的chunk。
RIFF chunk
标志为RIFF的chunk是比较特殊的,每一个RIFF文件首先存放的必须是一个RIFF chunk,并且只能有这一个标志为RIFF的chunk。RIFF的数据域的起始位置是一个4字节码(FOURCC),用于标识其数据域中chunk的数据类型;紧接着数据域的内容则是包含的subchunk,如下图
这是一个RIFF chunk中包含有两个subchunk,可以看出RIFF chunk的数据域首先是是4字节的 Form Type,接着是两个subchunk,每一个subchun有包含有自己的标识、数据域的大小以及数据域。
除了RIFF cunk可以嵌套其他的chunk外,另一个可以有subchunk的就是LIST chunk。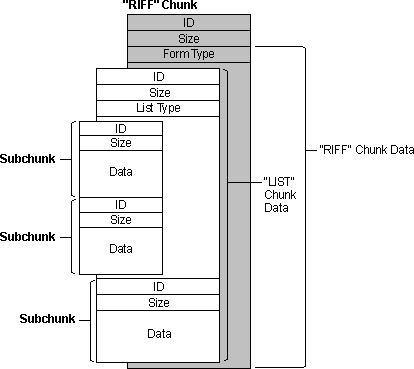
上图中,首先是RIFF文件必须的RIFF chunk,其数据域又包含有两个subchunk,其中一个subchunk的类型为LIST,该LIST chunk又包含了两个subchunk。
(list chunk 是否可以做首)
FourCC
FourCC 全称为Four-Character Codes,是一个4字节32位的标识符,通常用来标识文件的数据格式。例如,在音视频播放器中,可以通过 文件的FourCC来决定调用那种CODEC进行视音频的解码。例如:DIV3,DIV4,DIVX,H264等,对于音频则有:WAV,MP3等。对于上面的RIFF文件,则有:RIFF,WAVE,fmt,data等。FourCC是4个ASCII字符,不足四个字符的则在最后补充空格(不是空字符)。比如,FourCC fmt,实际上是'f' 'm' 't' ' '。
FourCC的生成通常可以使用如下宏:
#define MAKE_FOURCC(a,b,c,d)
( ((uint32_t)d) | ( ((uint32_t)c) << 8 ) | ( ((uint32_t)b) << 16 ) | ( ((uint32_t)a) << 24 ) )在程序 中还是不要使用太长的宏为好,在C++中可以使用模板和enum结合的方式。来保证在编译时期就能够将FourCC生成出来。
#define FOURCC uint32_t
template <char ch0, char ch1, char ch2, char ch3> struct MakeFOURCC{ enum { value = (ch0 << 0) + (ch1 << 8) + (ch2 << 16) + (ch3 << 24) }; };
FOURCC fourcc_fmt = MakeFOURCC<'f', 'm', 't', ' '>::value;将字符常量传入模板,在结构体中声明一个enum,编译器会在编译时期确定枚举值,这样就能给保证FOURCC在编译就能生成出来。
WAV file
WAV 是Microsoft开发的一种音频文件格式,它符合上面提到的RIFF文件格式标准,可以看作是RIFF文件的一个具体实例。既然WAV符合RIFF规范,其基本的组成单元也是chunk。一个WAV文件通常有三个chunk以及一个可选chunk,其在文件中的排列方式依次是:RIFF chunk,Format chunk,Fact chunk(附加块,可选),Data chunk。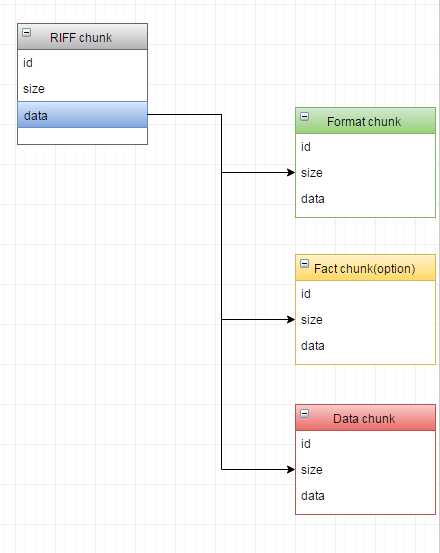
一个WAV文件,首先是一个RIFF chunk;RIFF chunk又包含有Format chunk,Data chunk以及可选的Fact chunk。各个chunk中字段的意义如下:
- RIFF chunk
- id
FOURCC 值为'R' 'I' 'F' 'F' - size
其data字段中数据的大小 字节数 - data
包含其他的chunk
- id
- Format chunk
- id
FOURCC 值为 'f' 'm' 't' ' ' - size
数据字段包含数据的大小。如无扩展块,则值为16;有扩展块,则值为= 16 + 2字节扩展块长度 + 扩展块长度或者值为18(只有扩展块的长度为2字节,值为0) - data
存放音频格式、声道数、采样率等信息- format_tag
2字节,表示音频数据的格式。如值为1,表示使用PCM格式。 - channels
2字节,声道数。值为1则为单声道,为2则是双声道。 - samples_per_sec
采样率,主要有22.05KHz,44.1kHz和48KHz。 - bytes_per sec
音频的码率,每秒播放的字节数。samples_per_sec * channels * bits_per_sample / 8,可以估算出使用缓冲区的大小 - block_align
数据块对齐单位,一次采样的大小,值为声道数 * 量化位数 / 8,在播放时需要一次处理多个该值大小的字节数据。 - bits_per_sample
音频sample的量化位数,有16位,24位和32位等。 - cbSize
扩展区的长度 - 扩展块内容
22字节,具体介绍,后面补充。
- format_tag
- id
- Fact chunk(option)
- id
FOURCC 值为 'f' 'a' 'c' 't' - size
数据域的长度,4(最小值为4) - 采样总数 4字节
- id
- Data chunk
- id
FOURCC 值为'd' 'a' 't' 'a' - size
数据域的长度 - data
具体的音频数据存放在这里
- id
采用压缩编码的WAV文件,必须要有Fact chunk,该块中只有一个数据,为每个声道的采样总数。
Format chunk 中的编码方式
在Format chunk中,除了有音频的数据的采样率、声道等音频的属性外,另一个比较主要的字段就是format_tag,该字段表示音频数据是以何种方式编码存放的。其具体的取值可以为以下:
- 0x0001
WAVE_FORMAT_PCM,采用PCM格式 - 0x0003
WAVE_FORMAT_IEEE_FLOAT,存放的值为IEEE float,范围为[-1.0f,1.0f] - 0x0006
WAVE_FORMAT_ALAW , 8bit ITU-T G.711 A-law - 0x0007
WAVE_FORMAT_MULAW,8bit ITU-T G.711 μμ-law - 0XFFFE
WAVE_FORMAT_EXTENSIBLE,具体的编码方式有扩展区的 sub_format字段决定
关于扩展格式块
当WAV文件使用的不是PCM编码方式是,就需要扩展格式块,它是在基本的Format chunk又添加一段数据。该数据的前两个字节,表示的扩展块的长度。紧接其后的是扩展的数据区,含有扩展的格式信息,其具体的长度取决于压缩编码的类型。当某种编码方式(如 ITU G.711 a-law)使扩展区的长度为0,扩展区的长度字段还必须保留,只是其值设置为0。
扩展区的各个字节的含义如下:
- size 2字节
扩展区的数据长度 ,可以为0或22 - valid_bits_per_sample 2字节
有效的采样位数,最大值为采样字节数 * 8。可以使用更灵活的量化位数,通常音频sample的量化位数为8的倍数,但是使用了WAVE_FORMAT_EXTENSIBLE时,量化的位数有扩展区中的valid bits per sample来描述,可以小于Format chunk中制定的bits per sample。 - channle mask 4字节
声道掩码 - sub format 16字节
GUID,include the data format code,数据格式码。
在Format chunk中的format_tag设置为0xFFFE时,表示使用扩展区中的sub_format来决定音频的数据的编码方式。在以下几种情况下必须要使用WAVE_FORMAT_EXTENSIBLE
- PCM数据的量化位数大于16
- 音频的采样声道大于2
- 实际的量化位数不是8的倍数
- 存储顺序和播放顺序不一致,需要指定从声道顺序到声卡播放顺序的映射情况。
Data chunk
Data块中存放的是音频的采样数据。每个sample按照采样的时间顺序写入,对于使用多个字节的sample,使用小端模式存放(低位字节存放在低地址,高位字节存放在高地址)。对于多声道的sample采用交叉存放的方式。例如:立体双声道的sample存储顺序为:声道1的第一个sample,声道2的第一个sample;声道1的第二个sample,声道2的第二个sample;依次类推....。对于PCM数据,有以下两种的存储方式:
- 单声道,量化位数为8,使用偏移二进制码
- 除上面之外的,使用补码方式存储。
总结
本文主要介绍了RIFF文件的格式和WAV音频文件格式,为后面实现对WAVE文件的读写打一个理论基础。后面打算使用C++标准库,实现对WAV文件的读写。
原文:http://www.cnblogs.com/wangguchangqing/p/5957531.html