PriorityQueue是一种什么样的容器呢?看过前面的几个jdk容器分析的话,看到Queue这个单词你一定会,哦~这是一种队列。是的,PriorityQueue是一种队列,但是它又是一种什么样的队列呢?它具有着什么样的特点呢?它的底层实现方式又是怎么样的呢?我们一起来看一下。
PriorityQueue其实是一个优先队列,什么是优先队列呢?这和我们前面讲的先进先出(First In First Out )的队列的区别在于,优先队列每次出队的元素都是优先级最高的元素。那么怎么确定哪一个元素的优先级最高呢,jdk中使用堆这么一种数据结构,通过堆使得每次出队的元素总是队列里面最小的,而元素的大小比较方法可以由用户指定,这里就相当于指定优先级喽。
1.二叉堆介绍
那么堆又是什么一种数据结构呢、它有什么样的特点呢?(以下见于百度百科)
(1)堆中某个节点的值总是不大于或不小于其父节点的值;
(2)堆总是一棵完全树。
(2)堆总是一棵完全树。
常见的堆有二叉堆、斐波那契堆等。而PriorityQueue使用的便是二叉堆,这里我们主要来分析和学习二叉堆。
二叉堆是一种特殊的堆,二叉堆是完全二叉树或者是近似完全二叉树。二叉堆有两种:最大堆和最小堆。最大堆:父结点的键值总是大于或等于任何一个子节点的键值;最小堆:父结点的键值总是小于或等于任何一个子节点的键值。
说到二叉树我们就比较熟悉了,因为我们前面分析和学习过了二叉查找树和红黑树(TreeMap)。惯例,我们以最小堆为例,用图解来描述下什么是二叉堆。
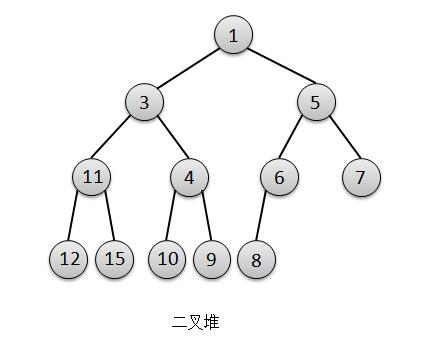
上图就是一颗完全二叉树(二叉堆),我们可以看出什么特点吗,那就是在第n层深度被填满之前,不会开始填第n+1层深度,而且元素插入是从左往右填满。
基于这个特点,二叉堆又可以用数组来表示而不是用链表,我们来看一下:
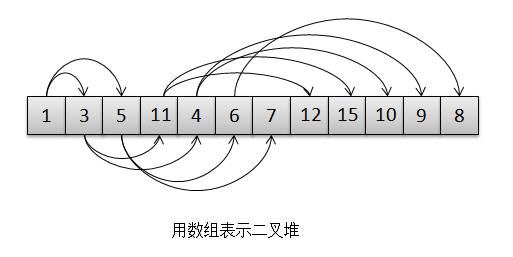
通过"用数组表示二叉堆"这张图,我们可以看出什么规律吗?那就是,基于数组实现的二叉堆,对于数组中任意位置的n上元素,其左孩子在[2n+1]位置上,右孩子[2(n+1)]位置,它的父亲则在[(n-1)/2]上,而根的位置则是[0]。
好了、在了解了二叉堆的基本概念后,我们来看下jdk中PriorityQueue是怎么实现的。
2.PriorityQueue的底层实现
先来看下PriorityQueue的定义:
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
我们看到PriorityQueue继承了AbstractQueue抽象类,并实现了Serializable接口,AbstractQueue抽象类实现了Queue接口,对其中方法进行了一些通用的封装,具体就不多看了。
下面再看下PriorityQueue的底层存储相关定义:

1 // 默认初始化大小 2 privatestaticfinalintDEFAULT_INITIAL_CAPACITY = 11; 3 4 // 用数组实现的二叉堆,下面的英文注释确认了我们前面的说法。 5 /** 6 * Priority queue represented as a balanced binary heap: the two 7 * children of queue[n] are queue[2*n+1] and queue[2*(n+1)]. The 8 * priority queue is ordered by comparator, or by the elements' 9 * natural ordering, if comparator is null: For each node n in the 10 * heap and each descendant d of n, n <= d. The element with the 11 * lowest value is in queue[0], assuming the queue is nonempty. 12 */ 13 private transient Object[] queue ; 14 15 // 队列的元素数量 16 private int size = 0; 17 18 // 比较器 19 private final Comparator<? super E> comparator; 20 21 // 修改版本 22 private transient int modCount = 0;
我们看到jdk中的PriorityQueue的也是基于数组来实现一个二叉堆,并且注释中解释了我们前面的说法。而Comparator这个比较器我们已经很熟悉了,我们说PriorityQueue是一个有限队列,他可以由用户指定优先级,就是靠这个比较器喽。
3.PriorityQueue的构造方法
1 /**
2 * 默认构造方法,使用默认的初始大小来构造一个优先队列,比较器comparator为空,这里要求入队的元素必须实现Comparator接口
3 */
4 public PriorityQueue() {
5 this(DEFAULT_INITIAL_CAPACITY, null);
6 }
7
8 /**
9 * 使用指定的初始大小来构造一个优先队列,比较器comparator为空,这里要求入队的元素必须实现Comparator接口
10 */
11 public PriorityQueue( int initialCapacity) {
12 this(initialCapacity, null);
13 }
14
15 /**
16 * 使用指定的初始大小和比较器来构造一个优先队列
17 */
18 public PriorityQueue( int initialCapacity,
19 Comparator<? super E> comparator) {
20 // Note: This restriction of at least one is not actually needed,
21 // but continues for 1.5 compatibility
22 // 初始大小不允许小于1
23 if (initialCapacity < 1)
24 throw new IllegalArgumentException();
25 // 使用指定初始大小创建数组
26 this.queue = new Object[initialCapacity];
27 // 初始化比较器
28 this.comparator = comparator;
29 }
30
31 /**
32 * 构造一个指定Collection集合参数的优先队列
33 */
34 public PriorityQueue(Collection<? extends E> c) {
35 // 从集合c中初始化数据到队列
36 initFromCollection(c);
37 // 如果集合c是包含比较器Comparator的(SortedSet/PriorityQueue),则使用集合c的比较器来初始化队列的Comparator
38 if (c instanceof SortedSet)
39 comparator = (Comparator<? super E>)
40 ((SortedSet<? extends E>)c).comparator();
41 else if (c instanceof PriorityQueue)
42 comparator = (Comparator<? super E>)
43 ((PriorityQueue<? extends E>)c).comparator();
44 // 如果集合c没有包含比较器,则默认比较器Comparator为空
45 else {
46 comparator = null;
47 // 调用heapify方法重新将数据调整为一个二叉堆
48 heapify();
49 }
50 }
51
52 /**
53 * 构造一个指定PriorityQueue参数的优先队列
54 */
55 public PriorityQueue(PriorityQueue<? extends E> c) {
56 comparator = (Comparator<? super E>)c.comparator();
57 initFromCollection(c);
58 }
59
60 /**
61 * 构造一个指定SortedSet参数的优先队列
62 */
63 public PriorityQueue(SortedSet<? extends E> c) {
64 comparator = (Comparator<? super E>)c.comparator();
65 initFromCollection(c);
66 }
67
68 /**
69 * 从集合中初始化数据到队列
70 */
71 private void initFromCollection(Collection<? extends E> c) {
72 // 将集合Collection转换为数组a
73 Object[] a = c.toArray();
74 // If c.toArray incorrectly doesn't return Object[], copy it.
75 // 如果转换后的数组a类型不是Object数组,则转换为Object数组
76 if (a.getClass() != Object[].class)
77 a = Arrays. copyOf(a, a.length, Object[]. class);
78 // 将数组a赋值给队列的底层数组queue
79 queue = a;
80 // 将队列的元素个数设置为数组a的长度
81 size = a.length ;
82 }
构造方法还是比较容易理解的,第四个构造方法中,如果填入的集合c没有包含比较器Comparator,则在调用initFromCollection初始化数据后,在调用heapify方法对数组进行调整,使得它符合二叉堆的规范或者特点,具体heapify是怎么构造二叉堆的,我们后面再看。
那么怎么样调整才能使一些杂乱无章的数据变成一个符合二叉堆的规范的数据呢?
4.二叉堆的添加原理及PriorityQueue的入队实现
我们回忆一下,我们在说红黑树TreeMap的时候说,红黑树为了维护其红黑平衡,主要有三个动作:左旋、右旋、着色。那么二叉堆为了维护他的特点又需要进行什么样的操作呢。
我们再来看下二叉堆(最小堆为例)的特点:
(1)父结点的键值总是小于或等于任何一个子节点的键值。
(2)基于数组实现的二叉堆,对于数组中任意位置的n上元素,其左孩子在[2n+1]位置上,右孩子[2(n+1)]位置,它的父亲则在[n-1/2]上,而根的位置则是[0]。
为了维护这个特点,二叉堆在添加元素的时候,需要一个"上移"的动作,什么是"上移"呢,我们继续用图来说明。
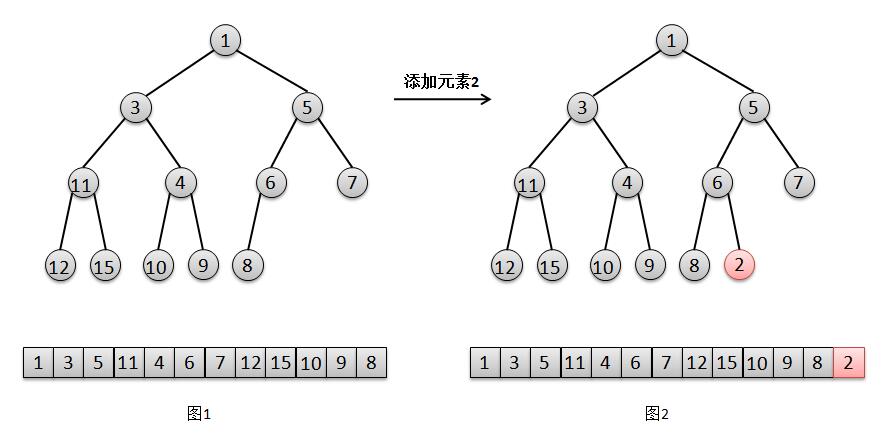
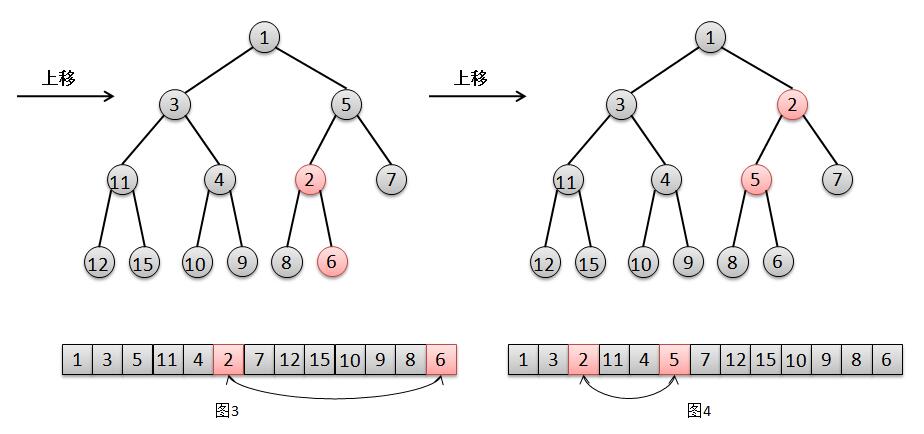
结合上面的图解,我们来说明一下二叉堆的添加元素过程:
1. 将元素2添加在最后一个位置(队尾)(图2)。
2. 由于2比其父亲6要小,所以将元素2上移,交换2和6的位置(图3);
3. 然后由于2比5小,继续将2上移,交换2和5的位置(图4),此时2大于其父亲(根节点)1,结束。
注:这里的节点颜色是为了凸显,应便于理解,跟红黑树的中的颜色无关,不要弄混。。。
看完了这4张图,是不是觉得二叉堆的添加还是挺容易的,那么下面我们具体看下PriorityQueue的代码是怎么实现入队操作的吧。
1 /**
2 * 添加一个元素
3 */
4 public boolean add(E e) {
5 return offer(e);
6 }
7
8 /**
9 * 入队
10 */
11 public boolean offer(E e) {
12 // 如果元素e为空,则排除空指针异常
13 if (e == null)
14 throw new NullPointerException();
15 // 修改版本+1
16 modCount++;
17 // 记录当前队列中元素的个数
18 int i = size ;
19 // 如果当前元素个数大于等于队列底层数组的长度,则进行扩容
20 if (i >= queue .length)
21 grow(i + 1);
22 // 元素个数+1
23 size = i + 1;
24 // 如果队列中没有元素,则将元素e直接添加至根(数组小标0的位置)
25 if (i == 0)
26 queue[0] = e;
27 // 否则调用siftUp方法,将元素添加到尾部,进行上移判断
28 else
29 siftUp(i, e);
30 return true;
31 }
这里的add方法依然没有按照Queue的规范,在队列满的时候抛出异常,因为PriorityQueue和前面讲的ArrayDeque一样,会进行扩容,所以只有当队列容量超出int范围才会抛出异常。
既然PriorityQueue会进行队列扩容,那么就来看下扩容的具体实现吧(对于数组实现的容器,我们见过太多的扩容了。。。)。
1 /**
2 * 数组扩容
3 */
4 private void grow(int minCapacity) {
5 // 如果最小需要的容量大小minCapacity小于0,则说明此时已经超出int的范围,则抛出OutOfMemoryError异常
6 if (minCapacity < 0) // overflow
7 throw new OutOfMemoryError();
8 // 记录当前队列的长度
9 int oldCapacity = queue .length;
10 // Double size if small; else grow by 50%
11 // 如果当前队列长度小于64则扩容2倍,否则扩容1.5倍
12 int newCapacity = ((oldCapacity < 64)?
13 ((oldCapacity + 1) * 2):
14 ((oldCapacity / 2) * 3));
15 // 如果扩容后newCapacity超出int的范围,则将newCapacity赋值为Integer.Max_VALUE
16 if (newCapacity < 0) // overflow
17 newCapacity = Integer. MAX_VALUE;
18 // 如果扩容后,newCapacity小于最小需要的容量大小minCapacity,则按找minCapacity长度进行扩容
19 if (newCapacity < minCapacity)
20 newCapacity = minCapacity;
21 // 数组copy,进行扩容
22 queue = Arrays.copyOf( queue, newCapacity);
23 }
需要理解的是,这里为什么当minCapacity小于0的时候,就代表超出int范围呢,我们来看下。
int在java中占4个字节,一个字节8位,从0开始记,那么4个字节的最高位就是31,而java中的基本数据类型都是有符号的,所以最高位代表的是符号位。
int的最大值Integer.MAX_VALUE=0111 1111 1111 1111 1111 1111 1111 1111,Integer.MAX_VALUE+1=1000 0000 0000 0000 0000 0000 0000 0000,此时最高位是符号位为1,所以这个数是负数。负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后+1(即在反码的基础上+1)。
好了,看完上面这个小插曲,我们来看下二叉堆的一个重要操作"上移"是怎么实现的吧。
1 /**
2 * 上移,x表示新插入元素,k表示新插入元素在数组的位置
3 */
4 private void siftUp(int k, E x) {
5 // 如果比较器comparator不为空,则调用siftUpUsingComparator方法进行上移操作
6 if (comparator != null)
7 siftUpUsingComparator(k, x);
8 // 如果比较器comparator为空,则调用siftUpComparable方法进行上移操作
9 else
10 siftUpComparable(k, x);
11 }
12
13 private void siftUpComparable(int k, E x) {
14 // 比较器comparator为空,需要插入的元素实现Comparable接口,用于比较大小
15 Comparable<? super E> key = (Comparable<? super E>) x;
16 // k>0表示判断k不是根的情况下,也就是元素x有父节点
17 while (k > 0) {
18 // 计算元素x的父节点位置[(n-1)/2]
19 int parent = (k - 1) >>> 1;
20 // 取出x的父亲e
21 Object e = queue[parent];
22 // 如果新增的元素k比其父亲e大,则不需要"上移",跳出循环结束
23 if (key.compareTo((E) e) >= 0)
24 break;
25 // x比父亲小,则需要进行"上移"
26 // 交换元素x和父亲e的位置
27 queue[k] = e;
28 // 将新插入元素的位置k指向父亲的位置,进行下一层循环
29 k = parent;
30 }
31 // 找到新增元素x的合适位置k之后进行赋值
32 queue[k] = key;
33 }
34
35 // 这个方法和上面的操作一样,不多说了
36 private void siftUpUsingComparator(int k, E x) {
37 while (k > 0) {
38 int parent = (k - 1) >>> 1;
39 Object e = queue[parent];
40 if (comparator .compare(x, (E) e) >= 0)
41 break;
42 queue[k] = e;
43 k = parent;
44 }
45 queue[k] = x;
46 }
结合上面的图解,二叉堆"上移"操作的代码还是很容易理解的,主要就是不断的将新增元素和其父亲进行大小比较,比父亲小则上移,最终找到一个合适的位置。
5.二叉堆的删除根原理及PriorityQueue的出队实现
对于二叉堆的出队操作,出队永远是要删除根元素,也就是最小的元素,要删除根元素,就要找一个替代者移动到根位置,相对于被删除的元素来说就是"下移"。
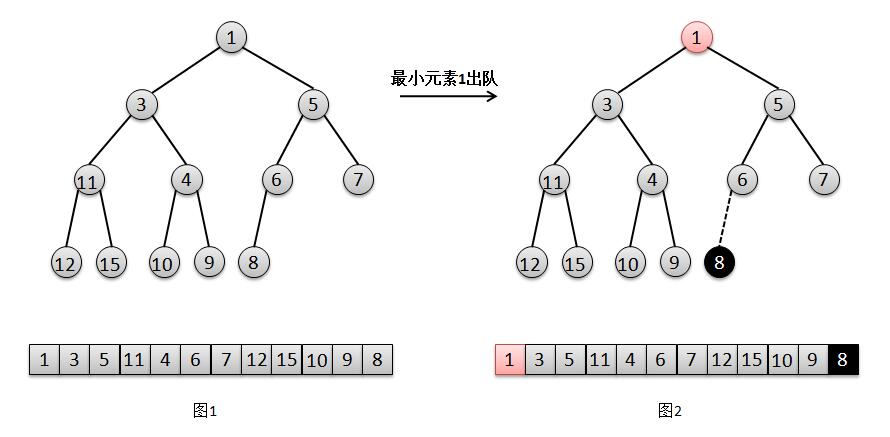

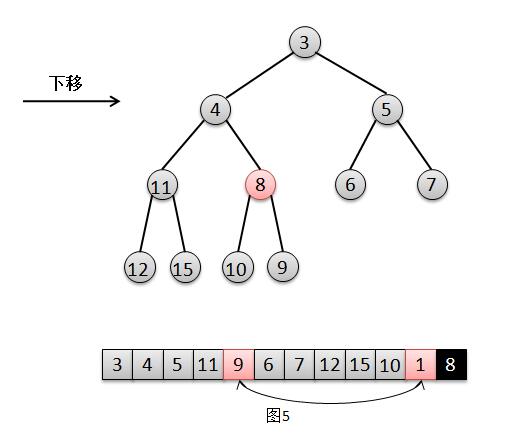
结合上面的图解,我们来说明一下二叉堆的出队过程:
1. 将找出队尾的元素8,并将它在队尾位置上删除(图2);
2. 此时队尾元素8比根元素1的最小孩子3要大,所以将元素1下移,交换1和3的位置(图3);
3. 然后此时队尾元素8比元素1的最小孩子4要大,继续将1下移,交换1和4的位置(图4);
4. 然后此时根元素8比元素1的最小孩子9要小,不需要下移,直接将根元素8赋值给此时元素1的位置,1被覆盖则相当于删除(图5),结束。
看完了这6张图,下面我们具体看下PriorityQueue的代码是怎么实现出队操作的吧。
1 /**
2 * 删除并返回队头的元素,如果队列为空则抛出NoSuchElementException异常(该方法在AbstractQueue中)
3 */
4 public E remove() {
5 E x = poll();
6 if (x != null)
7 return x;
8 else
9 throw new NoSuchElementException();
10 }
11
12 /**
13 * 删除并返回队头的元素,如果队列为空则返回null
14 */
15 public E poll() {
16 // 队列为空,返回null
17 if (size == 0)
18 return null;
19 // 队列元素个数-1
20 int s = --size ;
21 // 修改版本+1
22 modCount++;
23 // 队头的元素
24 E result = (E) queue[0];
25 // 队尾的元素
26 E x = (E) queue[s];
27 // 先将队尾赋值为null
28 queue[s] = null;
29 // 如果队列中不止队尾一个元素,则调用siftDown方法进行"下移"操作
30 if (s != 0)
31 siftDown(0, x);
32 return result;
33 }
34
35 /**
36 * 上移,x表示队尾的元素,k表示被删除元素在数组的位置
37 */
38 private void siftDown(int k, E x) {
39 // 如果比较器comparator不为空,则调用siftDownUsingComparator方法进行下移操作
40 if (comparator != null)
41 siftDownUsingComparator(k, x);
42 // 比较器comparator为空,则调用siftDownComparable方法进行下移操作
43 else
44 siftDownComparable(k, x);
45 }
46
47 private void siftDownComparable(int k, E x) {
48 // 比较器comparator为空,需要插入的元素实现Comparable接口,用于比较大小
49 Comparable<? super E> key = (Comparable<? super E>)x;
50 // 通过size/2找到一个没有叶子节点的元素
51 int half = size >>> 1; // loop while a non-leaf
52 // 比较位置k和half,如果k小于half,则k位置的元素就不是叶子节点
53 while (k < half) {
54 // 找到根元素的左孩子的位置[2n+1]
55 int child = (k << 1) + 1; // assume left child is least
56 // 左孩子的元素
57 Object c = queue[child];
58 // 找到根元素的右孩子的位置[2(n+1)]
59 int right = child + 1;
60 // 如果左孩子大于右孩子,则将c复制为右孩子的值,这里也就是找出左右孩子哪个最小
61 if (right < size &&
62 ((Comparable<? super E>) c).compareTo((E) queue [right]) > 0)
63 c = queue[child = right];
64 // 如果队尾元素比根元素孩子都要小,则不需"下移",结束
65 if (key.compareTo((E) c) <= 0)
66 break;
67 // 队尾元素比根元素孩子都大,则需要"下移"
68 // 交换跟元素和孩子c的位置
69 queue[k] = c;
70 // 将根元素位置k指向最小孩子的位置,进入下层循环
71 k = child;
72 }
73 // 找到队尾元素x的合适位置k之后进行赋值
74 queue[k] = key;
75 }
76
77 // 这个方法和上面的操作一样,不多说了
78 private void siftDownUsingComparator(int k, E x) {
79 int half = size >>> 1;
80 while (k < half) {
81 int child = (k << 1) + 1;
82 Object c = queue[child];
83 int right = child + 1;
84 if (right < size &&
85 comparator.compare((E) c, (E) queue [right]) > 0)
86 c = queue[child = right];
87 if (comparator .compare(x, (E) c) <= 0)
88 break;
89 queue[k] = c;
90 k = child;
91 }
92 queue[k] = x;
93 }
jdk中,不是直接将根元素删除,然后再将下面的元素做上移,重新补充根元素;而是找出队尾的元素,并在队尾的位置上删除,然后通过根元素的下移,给队尾元素找到一个合适的位置,最终覆盖掉跟元素,从而达到删除根元素的目的。这样做在一些情况下,会比直接删除在上移根元素,或者直接下移根元素再调整队尾元素的位置少操作一些步奏(比如上面图解中的例子,不信你可以试一下^_^)。
明白了二叉堆的入队和出队操作后,其他的方法就都比较简单了,下面我们再来看一个二叉堆中比较重要的过程,二叉堆的构造。
6.堆的构造过程
我们在上面提到过的,堆的构造是通过一个heapify方法,下面我们来看下heapify方法的实现。
1 /**
2 * Establishes the heap invariant (described above) in the entire tree,
3 * assuming nothing about the order of the elements prior to the call.
4 */
5 private void heapify() {
6 for (int i = (size >>> 1) - 1; i >= 0; i--)
7 siftDown(i, (E) queue[i]);
8 }
这个方法很简单,就这几行代码,但是理解起来却不是那么容器的,我们来分析下。
假设有一个无序的数组,要求我们将这个数组建成一个二叉堆,你会怎么做呢?最简单的办法当然是将数组的数据一个个取出来,调用入队方法。但是这样做,每次入队都有可能会伴随着元素的移动,这么做是十分低效的。那么有没有更加高效的方法呢,我们来看下。
为了方便,我们将上面我们图解中的数组去掉几个元素,只留下7、6、5、12、10、3、1、11、15、4(顺序已经随机打乱)。ok、那么接下来,我们就按照当前的顺序建立一个二叉堆,暂时不用管它是否符合标准。
int a = [7, 6, 5, 12, 10, 3, 1, 11, 15, 4 ];
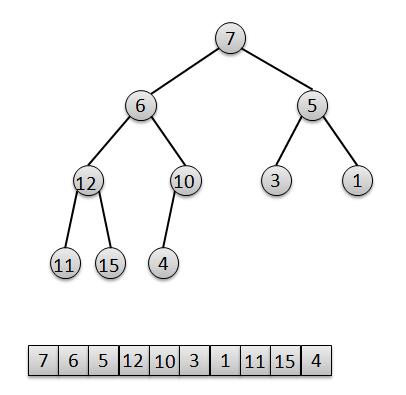
我们观察下用数组a建成的二叉堆,很明显,对于叶子节点4、15、11、1、3来说,它们已经是一个合法的堆。所以只要最后一个节点的父节点,也就是最后一个非叶子节点a[4]=10开始调整,然后依次调整a[3]=12,a[2]=5,a[1]=6,a[0]=7,分别对这几个节点做一次"下移"操作就可以完成了堆的构造。ok,我们还是用图解来分析下这个过程。
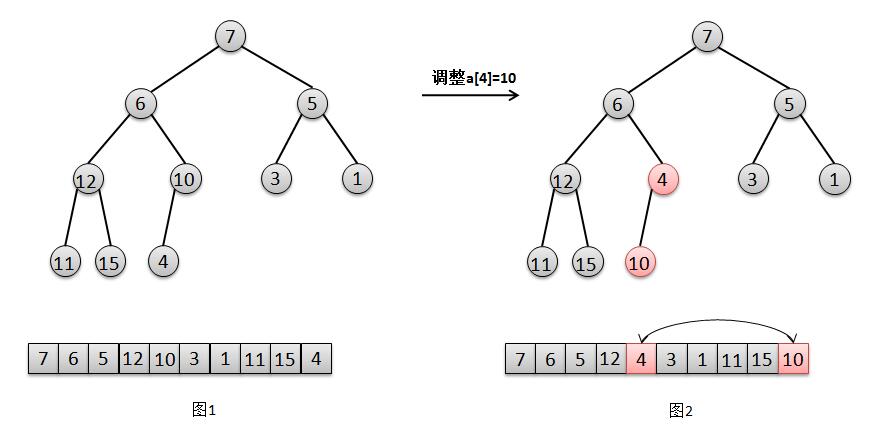
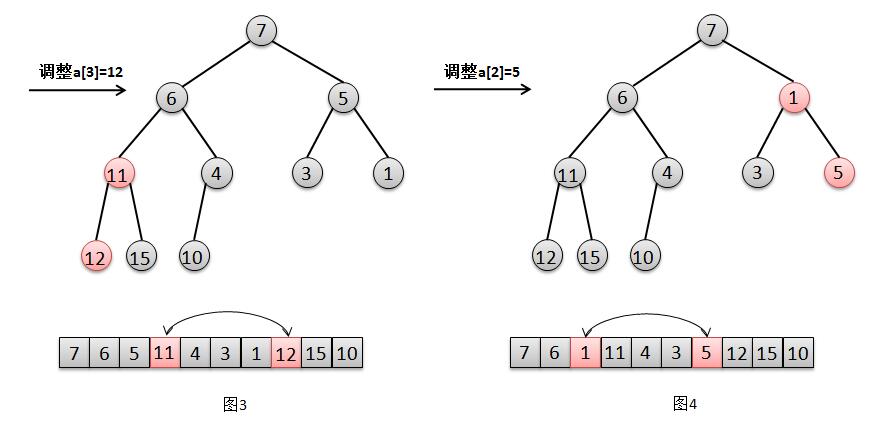
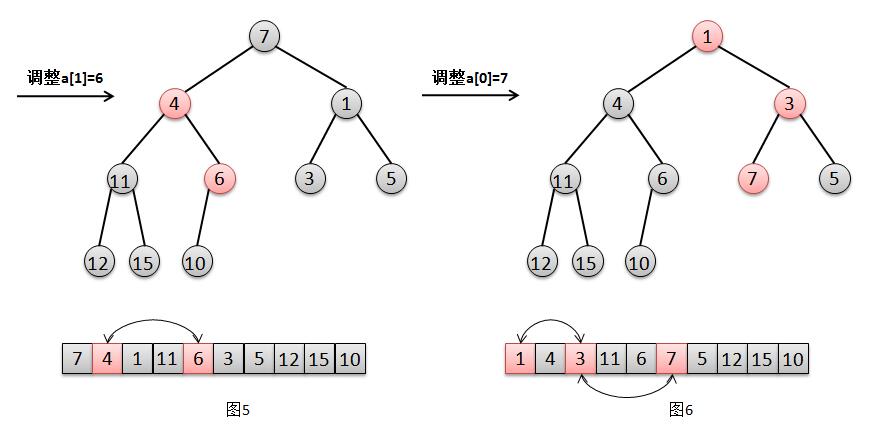
我们参照图解分别来解释下这几个步奏:
1. 对于节点a[4]=10的调整(图1),只需要交换元素10和其子节点4的位置(图2)。
2. 对于节点a[3]=12的调整,只需要交换元素12和其最小子节点11的位置(图3)。
3. 对于节点a[2]=5的调整,只需要交换元素5和其最小子节点1的位置(图4)。
4. 对于节点a[1]=6的调整,只需要交换元素6和其最小子节点4的位置(图5)。
5. 对于节点a[0]=7的调整,只需要交换元素7和其最小子节点1的位置,然后交换7和其最小自己点3的位置(图6)。
至此,调整完毕,建堆完成。
再来回顾一下,PriorityQueue的建堆代码,看看是否可以看得懂了。
1 private void heapify() {
2 for (int i = (size >>> 1) - 1; i >= 0; i--)
3 siftDown(i, (E) queue[i]);
4 }
int i = (size >>> 1) - 1,这行代码是为了找寻最后一个非叶子节点,然后倒序进行"下移"siftDown操作,是不是很显然了。
到这里PriorityQueue的基本操作就分析完了,明白了其底层二叉堆的概念及其入队、出队、建堆等操作,其他的一些方法代码就很简单了,这里就不一一分析了。
PriorityQueue 完!