1.Memcached常用命令总结
Memcached命令格式一般为:
command
其中描述如下:
| 参数 | 描述 |
|---|---|
| command | 操作命令,一般为set/add/replace/get/delete等 |
| key | 缓存的key,Memcache内部限制不能超过250个字符, |
| flag | 标识数据格式,比如JSON、XML等 |
| expiration time | 过期时间,单位为s,0为不过期,最好设置过期时间,以免保存大量无效数据,最大过期时间为30天,超过30天则缓存获取不到 |
| bytes | 字节数,比如1234,则字节数为4 |
| value | 缓存中的值 |
比如以下命令:
set name 0 0 4 test// key 为name,value为test,字节数4个,缓存不过期
常用命令列表如下:
| 命令 | 描述 |
|---|---|
| set | 添加或者更新 |
| get | 获取数据 |
| add | 数据不存在的时候添加 |
| replace | 数据存在的时候替换value的值 |
| append | 后面追加 |
| prepend | 前面追加 |
2.Memcached主要特征
1.协议简单
server和client的通信并不使用复杂的XML或者json协议,而是使用简单的文本协议和二进制协议
2.内置内存存储方式
Memcached是纯内存存储,不支持持久化,因此当Memcached重启或者机器重启的时候所有数据会丢失。
因此会存在数据重启无法恢复的问题。
3.Memcached使用客户端分布式
Memcached服务端没有分布式的功能,各个实例之间并不会互相通信或者数据共享,因此需要依赖客户端实现分布式。
3.Memcached存在的问题
1.因此会存在数据重启无法恢复的问题
可以通过配合持久化数据库MemcachedDB使用
2.无法通过key做范围查询
3.没有提供高可用相关支持,只能通过客户端逻辑来处理,比如写入的时候同时写入主备服务器
4.Memcached内存存储分析
Memcached使用Slab Allocator机制分配和管理内存,这种分配机制可以减少内存碎片的产生,减轻系统管理内存的负担。
Slab Allocator的分配机制其实很简单,就是将内存分割成各种尺寸的内存快(Chunk)并将尺寸相同的内存块分组Slab Class。其中分配的快可以重新利用,不会释放到内存中。
其中分配给Slab Class的内存空间为Page(默认大小为1MB)。
内存分配结构大致如下:
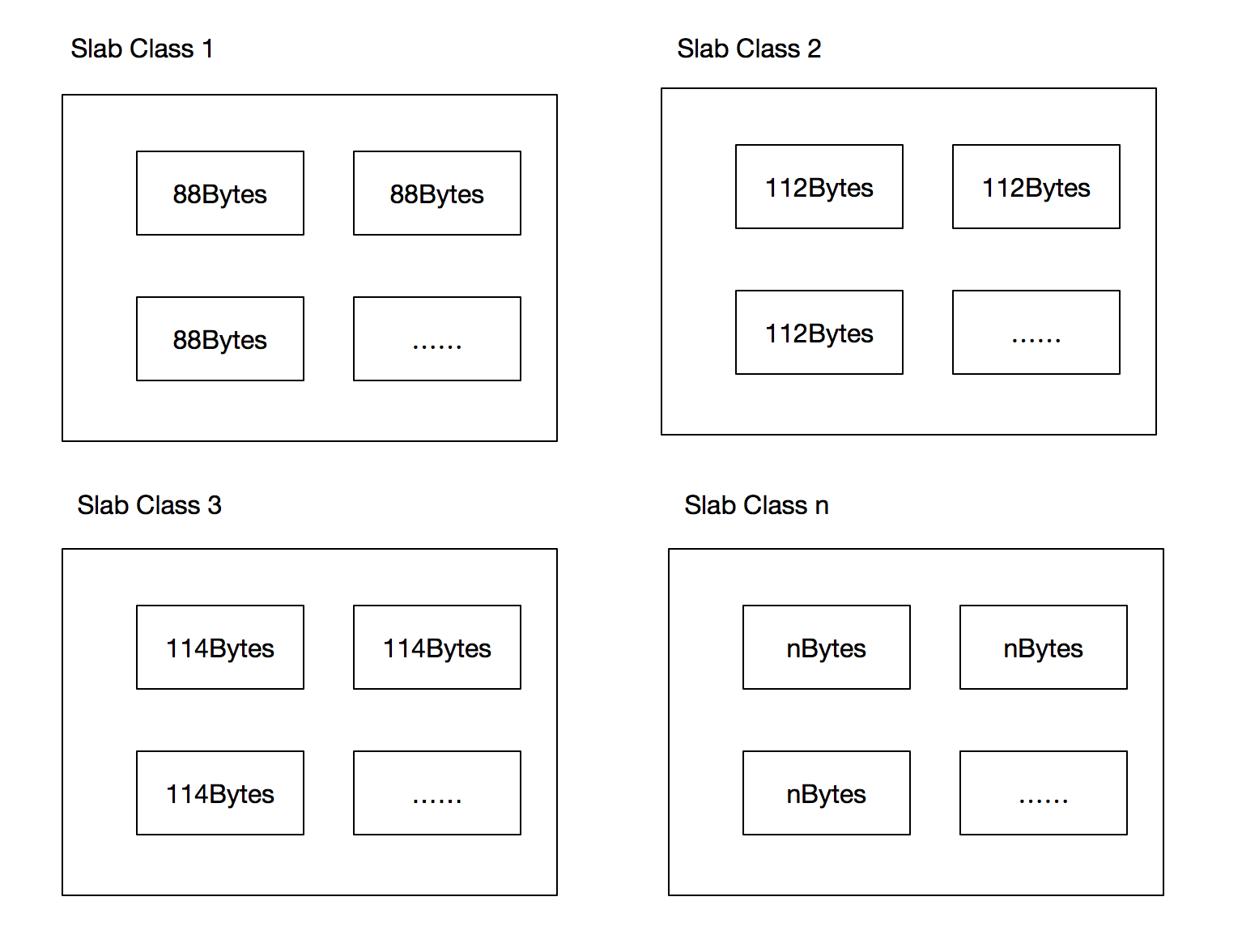
分配的内存快大小目前默认最小内存块为:88Bytes,Growth Factor决定了内存块增长的幅度,默认值为1.25,可以通过启动参数配置。
这种分配方式在一定程度上也会造成内存的浪费,比如要保存100字节的数据的时候,只能放到112Bytes的内存块中,剩余的12Byte内存空间被浪费。
结构中各个部分数量的计算:
Page个数 = 内存总空间 / 1MB
各个Page中Chunk的个数 = 1MB / Chunk的大小
Chunk大小计算 = 初始值 * Growth Factor
当设置缓存的时候,会根据Item的大小来决定保存到那个Slab Class中,其中Item大小为:
key长 + value长度 + 后缀长度 + item长度大小(32个字节)
其中Memcached可以保存的数据Item最大为1MB。
5.Memcached典型问题分析
对于Memcached的使用中一般会出现以下问题:
1. 容量问题
单一节点无法突破内存上限
2. 服务高可用
服务宕机会导致访问全部穿透数据库
3. 扩展问题
无法突破单实例请求峰值
Memcached当达到内存上线的时候,会对内存数据进行垃圾回收,垃圾回收有两种方式:
1.Lazy模式,Memcached不会自动去检查数据的过期情况,而是在查询的时候,检查数据的过期情况,然后对数据进行相应处理。
2.使用LRU算法进行内存垃圾回收(最近最少使用算法)
其中垃圾回收是在Slab Class范围内的,并不是全局的LRU
对于Memcached使用集群的方式,有两种算法来计算缓存落在那一台缓存机器。
方法一: key.hashCode() / 缓存节点个数
缺点:当对分布式缓存中添加、删除或者节点故障剔除操作中,会导致所有的历史数据都无法找到
方法二:使用一致性哈希算法可以解决1中的问题
数据一致性问题怎么解决
key冲突的问题解决
可以使用明明空间,对于不同的系统,使用不同的明明空间,比如前缀:ns_