1、Python字符串
字符串的常用方法:
1 Python 3.6.2 (v3.6.2:5fd33b5, Jul 8 2017, 04:14:34) [MSC v.1900 32 bit (Intel)] on win32 2 Type "copyright", "credits" or "license()" for more information. 3 >>> 4 >>> name = 'visonwong' 5 >>># 首字母大写 6 >>> name.capitalize() 7 'Visonwong' 8 >>> # 大写全部变小写 9 >>> name.casefold() 10 'visonwong' 11 >>> # 居中输出 12 >>> name.center(50,'_') 13 '____________________visonwong_____________________' 14 >>> # 统计o出现的次数 15 >>> name.count('o') 16 2 17 >>> # 将字符串编码成bytes格式 18 >>> name.encode() 19 b'visonwong' 20 >>> # 判断字符串是否已wong结尾 21 >>> name.endswith('wong') 22 True 23 >>> # 查找'v',找到返回其索引,找不到返回-1 24 >>> name.find('v') 25 0 26 >>># 替换 27 >>> name.replace('vi','Vi') 28 'Visonwong' 29 >>> # 判断字符串是否为字母或数字 30 >>> '9a'.isalnum() 31 True 32 >>> # 判断字符串是否为数字 33 >>> '9'.isdigit() 34 True
2、Python字符编码
- bytes和str的区别
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。
文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。
Python 3不会以任意隐式的方式混用str和bytes(类似int和long之间自动转换),正是这使得两者的区分特别清晰。
你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。
在py3中encode,在转码的同时还会把string 变成bytes类型。
同样,decode在解码的同时还会把bytes变回string。
这是件好事。不管怎样,字符串和字节包之间的界线是必然的,下面的图解非常重要,务请牢记于心:
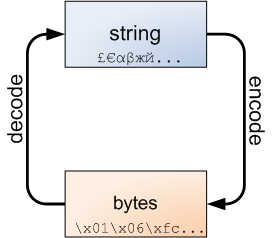
str和bytes类型互换:
1 #!/user/bin/env ptyhon 2 # -*- coding:utf-8 -*- 3 # Author: VisonWong 4 5 msg = "人生苦短,快学python" 6 7 print(msg.encode("utf-8")) # 如果不指定编码格式,默认为utf-8 8 9 print(b'xe4xbaxbaxe7x94x9fxe8x8bxa6xe7x9fxadxefxbcx8cxe5xbfxabxe5xadxa6python'.decode("utf-8")) 10 11 12 13 # b'xe4xbaxbaxe7x94x9fxe8x8bxa6xe7x9fxadxefxbcx8cxe5xbfxabxe5xadxa6python' 14 # 人生苦短,快学python
- 为什么要进行编码和转码
由于每个国家电脑的字符编码格式不统一(列中国:GBK),同一款软件放到不同国家的电脑上会出现乱码的情况,出现这种情况如何解决呢?!
当然由于所有国家的电脑都支持Unicode万国码,那么我们可以把Unicode为跳板,先把字符编码转换为Unicode,在把Unicode转换为另一个国家的字符编码(例韩国),则不会出现乱码的情况。
当然这里只是转编码集并不是翻译成韩文不要弄混了。

python3
1 #!/user/bin/env ptyhon 2 # -*- coding:utf-8 -*- 3 # Author: VisonWong 4 5 import sys 6 # 输出默认编码格式 7 print(sys.getdefaultencoding()) 8 9 msg = "人生苦短,快学Python" 10 # 转成GBK格式,PY3默认就是unicode,不用再decode 11 msg_gbk = msg.encode('gbk') 12 # 转成utf-8格式 13 msg_utf8 = msg.encode('utf-8') 14 # 从GBK转回utf8,先用当下编码方式解码,转换为unicode,再编码为希望的格式 15 msg_gbk_to_utf8 = msg_gbk.decode('gbk').encode('utf-8') 16 17 18 print(msg) 19 print(msg_gbk) 20 print(msg_utf8) 21 print(msg_gbk_to_utf8) 22 23 24 # utf-8 25 # 人生苦短,快学Python 26 # b'xc8xcbxc9xfaxbfxe0xb6xccxa3xacxbfxecxd1xa7Python' 27 # b'xe4xbaxbaxe7x94x9fxe8x8bxa6xe7x9fxadxefxbcx8cxe5xbfxabxe5xadxa6Python' 28 # b'xe4xbaxbaxe7x94x9fxe8x8bxa6xe7x9fxadxefxbcx8cxe5xbfxabxe5xadxa6Python'
python2
声明字符编码(utf-8)
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 #Python2.0环境 默认编码ascii 5 import sys 6 name = "你好" #ascii码里是没有字符“你好”的,此时的name为uft-8 7 8 print (sys.getdefaultencoding()) #获取默认编码 9 print(name.decode("utf-8")) #把uft-8码解码为Unicode 10 11 name_unicode=name.decode("utf-8") 12 print (name_unicode,type(name.decode("utf-8"))) #查看当前的字符编码 13 14 name_gbk=name_unicode.encode("gbk") #把字符有Unicode转换为gbk 15 print(name_gbk) 16 17 #ascii 18 #你好 19 #(u'u4f60u597d', <type 'unicode'>) 20 #���
使用默认字符编码(ascii)
1 #!/usr/bin/env python 2 #-Author-Lia 3 import sys 4 name = "nihao" #英文字符,且第二行字符声明去掉,此刻name为ascii码 5 6 print (sys.getdefaultencoding()) #获取系统编码 7 name_unicode = name.decode("ascii") #ascii码转换为unicode 8 print(name_unicode,type(name_unicode)) 9 10 name_utf8=name_unicode.encode("utf-8") #unicode转换为utf-8 11 print(name_utf8,type(name_utf8)) 12 13 14 name_gbk=name_unicode.encode("gbk") #unicode转换为gbk 15 print(name_gbk,type(name_gbk)) 16 17 #ascii 18 #(u'nihao', <type 'unicode'>) 19 #('nihao', <type 'str'>) 20 #('nihao', <type 'str'>)
总结:
Python2.x里默认字符编码为ascii,如果不声明编码格式,则输入的字符格式都是ascii码(中文不在ascii里面,输入报错);
如果要输入中文字符,则需要声明编码格式,此时中文字符的编码格式不跟随默认字符编码格式,而是与声明的编码格式一致(上面实例为utf-8),这些都需谨记。