初露锋芒
HTTP/2: the Future of the Internet 这是 Akamai 公司建立的一个官方的演示,用以说明 HTTP/2 相比于之前的 HTTP/1.1 在性能上的大幅度提升。 同时请求 379 张图片,从Load time 的对比可以看出 HTTP/2 在速度上的优势。

此时如果我们打开 Chrome Developer Tools 查看 Network 一栏可以发现,HTTP/2 在网络请求方面与 HTTP /1.1的明显区别。
HTTP/1:
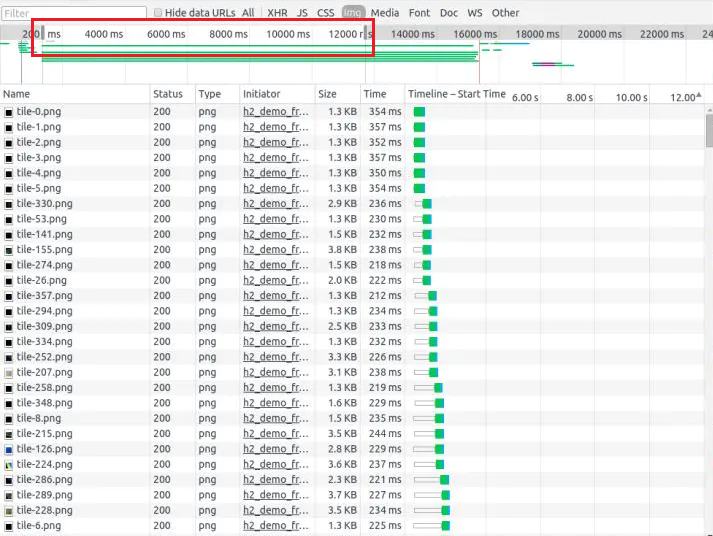
HTTP/2:
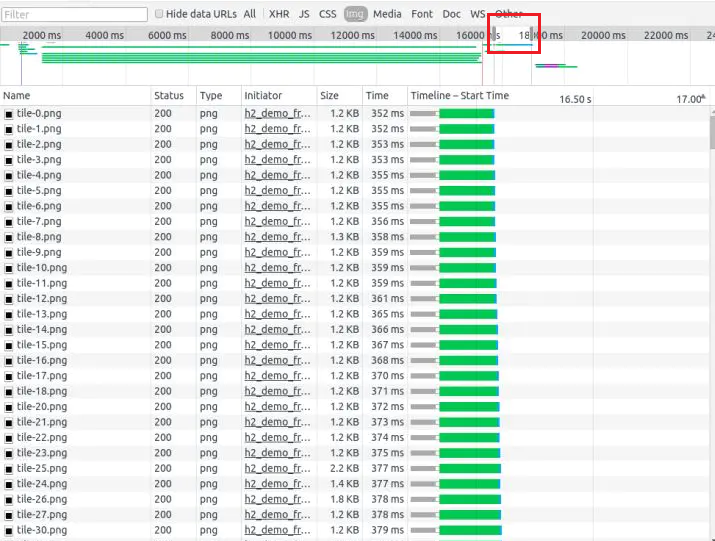
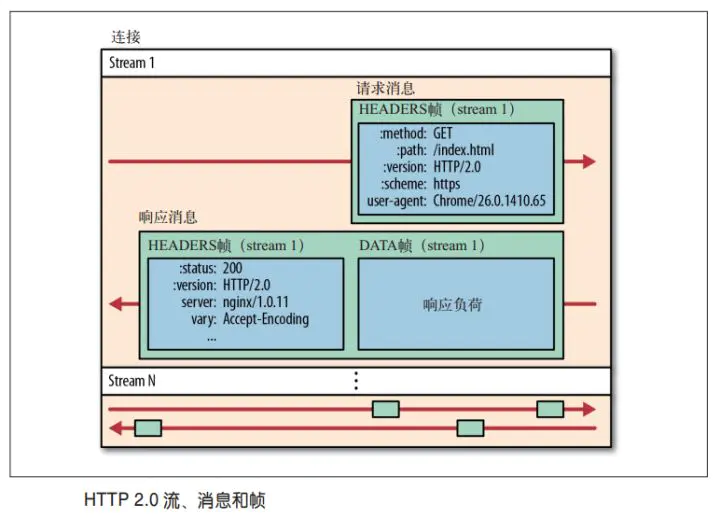
多路复用 (Multiplexing)
多路复用允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息。
众所周知 ,在 HTTP/1.1 协议中 「浏览器客户端在同一时间,针对同一域名下的请求有一定数量限制。超过限制数目的请求会被阻塞」。
该图总结了不同浏览器对该限制的数目。

在 HTTP 1.0 中,发起一个请求是这样的:
浏览器请求 url -> 解析域名 -> 建立 HTTP 连接 -> 服务器处理文件 -> 返回数据 -> 浏览器解析、渲染文件
这个流程最大的问题是,每次请求都需要建立一次 HTTP 连接,也就是我们常说的3次握手4次挥手,这个过程在一次请求过程中占用了相当长的时间;为了解决这个问题, HTTP 1.1 中提供了 Keep-Alive,允许我们建立一次 HTTP 连接,来返回多次请求数据。
但是这里有两个问题:
a.HTTP 1.1 基于串行文件传输数据,因此这些请求必须是有序的,所以实际上我们只是节省了建立连接的时间,而获取数据的时间并没有减少
b.最大并发数问题,假设我们在 Apache 中设置了最大并发数 300,而因为浏览器本身的限制,最大请求数为 6,那么服务器能承载的最高并发数是 50
而 HTTP/2 引入二进制数据帧和流的概念,其中帧对数据进行顺序标识,这样浏览器收到数据之后,就可以按照序列对数据进行合并,而不会出现合并后数据错乱的情况。同样是因为有了序列,服务器就可以并行的传输数据。
HTTP/2 对同一域名下所有请求都是基于流,也就是说同一域名不管访问多少文件,也只建立一路连接。同样Apache的最大连接数为300,因为有了这个新特性,最大的并发就可以提升到300,比原来提升了6倍。
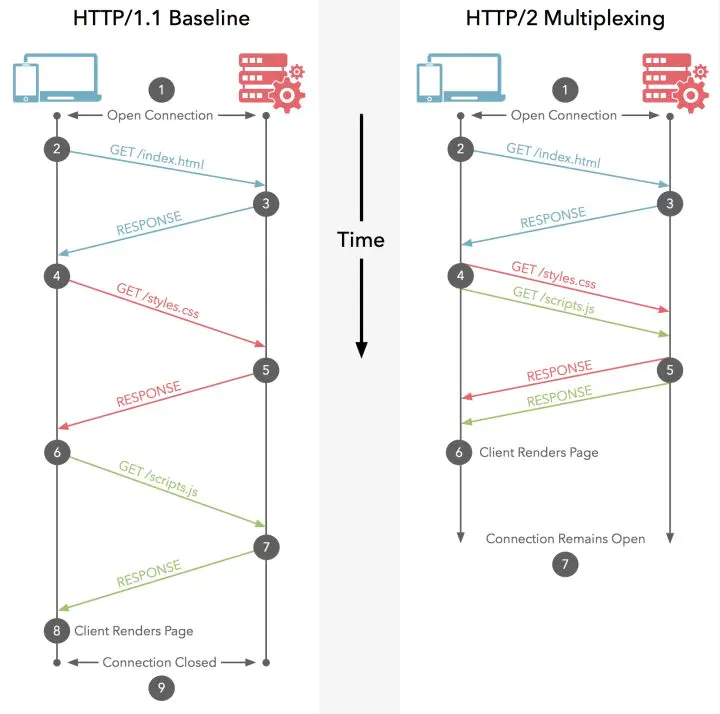
二进制分帧
在不改动 HTTP/1.x 的语义、方法、状态码、URI 以及首部字段….. 的情况下, HTTP/2 是如何做到「突破 HTTP1.1 的性能限制,改进传输性能,实现低延迟和高吞吐量」的 ?
关键之一就是在 应用层(HTTP/2)和传输层(TCP or UDP)之间增加一个二进制分帧层。
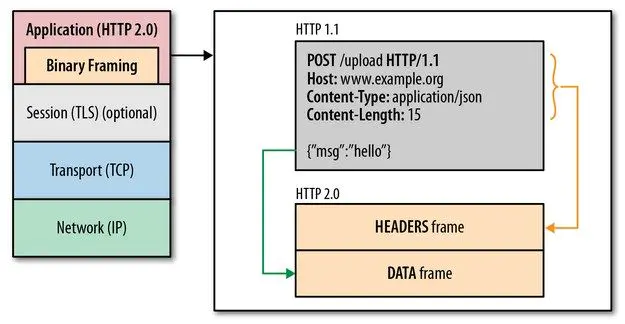
在二进制分帧层中, HTTP/2 会将所有传输的信息分割为更小的消息和帧(frame),并对它们采用二进制格式的编码 ,其中 HTTP1.x 的首部信息会被封装到 HEADER frame,而相应的 Request Body 则封装到 DATA frame 里面。
HTTP/2 通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流。
在过去, HTTP 性能优化的关键并不在于高带宽,而是低延迟。TCP 连接会随着时间进行自我「调谐」,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐则被称为 TCP 慢启动。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。
HTTP/2 通过让所有数据流共用同一个连接,可以更有效地使用 TCP 连接,让高带宽也能真正的服务于 HTTP 的性能提升。
总结:
- 单连接多资源的方式,减少服务端的链接压力,内存占用更少,连接吞吐量更大
- 由于 TCP 连接的减少而使网络拥塞状况得以改善,同时慢启动时间的减少,使拥塞和丢包恢复速度更快
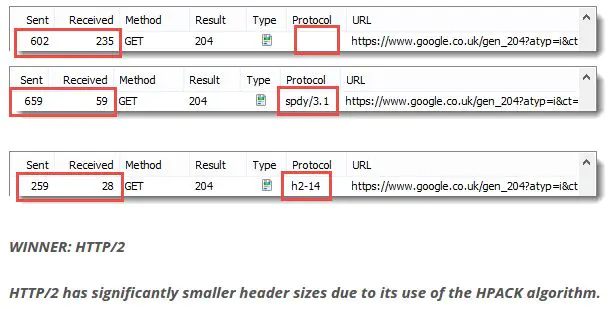
首部压缩(Header Compression)
HTTP/1.1并不支持 HTTP 首部压缩,为此 SPDY 和 HTTP/2 应运而生, SPDY 使用的是通用的DEFLATE算法,而 HTTP/2 则使用了专门为首部压缩而设计的 HPACK 算法。
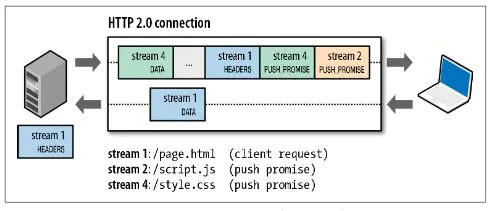
服务端推送(Server Push)
服务端推送是一种在客户端请求之前发送数据的机制。在 HTTP/2 中,服务器可以对客户端的一个请求发送多个响应。Server Push 让 HTTP1.x 时代使用内嵌资源的优化手段变得没有意义;如果一个请求是由你的主页发起的,服务器很可能会响应主页内容、logo 以及样式表,因为它知道客户端会用到这些东西。这相当于在一个 HTML 文档内集合了所有的资源,不过与之相比,服务器推送还有一个很大的优势:可以缓存!也让在遵循同源的情况下,不同页面之间可以共享缓存资源成为可能。
请求优先级
既然所有资源都是并行发送,那么就需要「优先级」的概念了,这样就可以对重要的文件进行先传输,加速页面的渲染。
HTTP/2给前端带来哪些影响?
减少HTTP请求不一定提升性能
如上所述, HTTP/2 针对多个请求进行了优化,因此之前我们在前端中所做的 关于减少HTTP请求的最佳实践都不再适用,如合并JS、CSS文件(Concatenation),多个图片或图标合并(Spriting),将较小的JS或CSS文件内嵌到HTML中(Inlining),合并HTML文件(Vulcanize),根据 此网站 的测试结果显示,在使用HTTP/2后,合并为一个大文件的加载时间反而会比不合并更长。
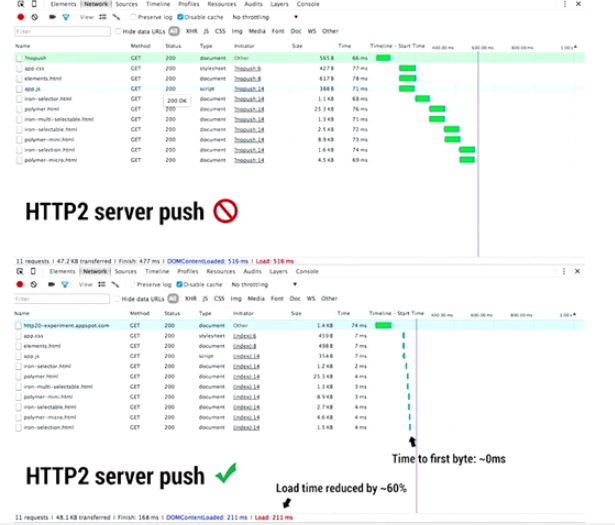
如上图所示,其中TTFB时间明显减少,所谓TTFB(Time To First Byte),即从浏览器发送请求开始,到接受到来自服务器的返回的第一字节信息(HTTP头信息)结束,之间所耗费的时间。这里就会包含 TCP连接往返(round trip)+服务器处理时间(如SQL执行)。 因为浏览器在第一次发送请求后,服务器已经预先把其他资源文件一同推送给了浏览器,因此后续的资源请求中,TTFB的时间得到了缩小。
压缩仍然需要
有些可能会问,那是不是用了 HTTP/2 后,资源文件也不需要压缩了呢? 答案是No,压缩文件还是有必要的,毕竟获取一个小文件的时间比大文件更短,HTTP/2并不会帮你自动压缩文件。
可以看出,HTTP/2 目的之一,就在于想把开发环境与生产环境的部署尽量保持一致,减少因为打包合并而产生一些不必要的麻烦。