1,进程和线程:线程是调度的基本单位 进程是资源分配的基本单位
2,线程基础


链接:https://www.nowcoder.com/questionTerminal/e33c72bceb4343879948342e2b6e3bca 来源:牛客网 狠狠地幸福 ①继承Thread类(真正意义上的线程类),是Runnable接口的实现。 ②实现Runnable接口,并重写里面的run方法。 ③使用Executor框架创建线程池。Executor框架是juc里提供的线程池的实现。 调用线程的start():启动此线程;调用相应的run()方法 继承于Thread类的线程类,可以直接调用start方法启动线程(使用static也可以实现资源共享).一个线程(对象)只能够执行一次start(),而且不能通过Thread实现类对象的run()去启动一个线程。 实现Runnable接口的类需要再次用Thread类包装后才能调用start方法。(三个Thread对象包装一个类对象,就实现了资源共享)。 线程的使用的话,注意锁和同步的使用。(多线程访问共享资源容易出现线程安全问题) 一般情况下,常见的是第二种。 * Runnable接口有如下好处: *①避免点继承的局限,一个类可以继承多个接口。 *②适合于资源的共享 /* * Thread的常用方法: * 1.start():启动线程并执行相应的run()方法 * 2.run():子线程要执行的代码放入run()方法中 * 3.currentThread():静态的,调取当前的线程 * 4.getName():获取此线程的名字 * 5.setName():设置此线程的名字 * 6.yield():调用此方法的线程释放当前CPU的执行权(很可能自己再次抢到资源) * 7.join():在A线程中调用B线程的join()方法,表示:当执行到此方法,A线程停止执行,直至B线程执行完毕, * A线程再接着join()之后的代码执行 * 8.isAlive():判断当前线程是否还存活 * 9.sleep(long l):显式的让当前线程睡眠l毫秒 (只能捕获异常,因为父类run方法没有抛异常) * 10.线程通信(方法在Object类中):wait() notify() notifyAll() * *设置线程的优先级(非绝对,只是相对几率大些) * getPriority():返回线程优先值 * setPriority(int newPriority):改变线程的优先级 */
3,死锁
链接:https://www.nowcoder.com/questionTerminal/09b51b00891543d6b08ace80c0704b01 来源:牛客网 死锁 :是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去 (1) 因为系统资源不足。 (2) 进程运行推进顺序不合适。 (3) 资源分配不当等。 如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则 就会因争夺有限的资源而陷入死锁。其次,进程运行推进顺序与速度不同,也可能产生死锁。 (1) 互斥条件:一个资源每次只能被一个进程使用。 (2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。 (3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。 (4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。 这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之 一不满足,就不会发生死锁。 死锁的解除与预防: 理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和 解除死锁。所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确 定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态 的情况下占用资源。因此,对资源的分配要给予合理的规划。
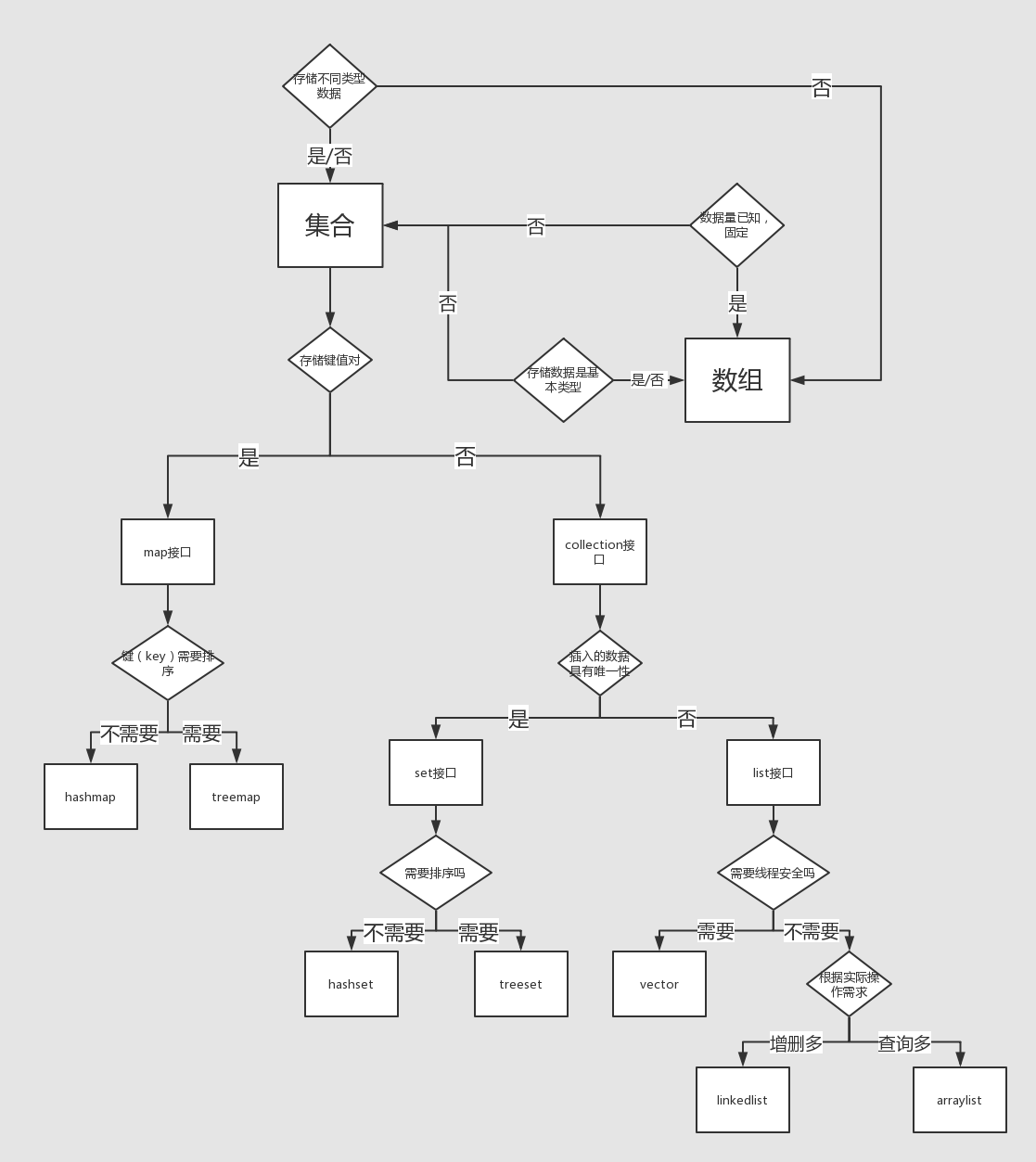
4,集合类

5,多线程的iterator
链接:https://www.nowcoder.com/questionTerminal/95e4f9fa513c4ef5bd6344cc3819d3f7 来源:牛客网 一:快速失败(fail—fast) 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。 原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。 注意:这里异常的抛出条件是检测到 modCount!=expectedmodCount 这个条件。如果集合发生变化时修改modCount值刚好又设置为了expectedmodCount值,则异常不会抛出。因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的bug。 场景:java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)。 二:安全失败(fail—safe) 采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。 原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception。 缺点:基于拷贝内容的优点是避免了Concurrent Modification Exception,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。 场景:java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
6,hashmap
链接:https://www.nowcoder.com/questionTerminal/6bd3857199564b3fb2d3fee4f4de06ea 来源:牛客网 HashMap的底层是用hash数组和单向链表实现的 ,当调用put方法是,首先计算key的hashcode,定位到合适的数组索引,然后再在该索引上的单向链表进行循环遍历用equals比较key是否存在,如果存在则用新的value覆盖原值,如果没有则向后追加。HashMap的两个重要属性是容量capacity和加载因子loadfactor,默认值分布为16和0.75,当容器中的元素个数大于 capacity*loadfactor时,容器会进行扩容resize 为2n,在初始化Hashmap时可以对着两个值进行修改,负载因子0.75被证明为是性能比较好的取值,通常不会修改,那么只有初始容量capacity会导致频繁的扩容行为,这是非常耗费资源的操作,所以,如果事先能估算出容器所要存储的元素数量,最好在初始化时修改默认容量capacity,以防止频繁的resize操作影响性能。
7,hashtable
链接:https://www.nowcoder.com/questionTerminal/f93bce3b4f07467dbcaef98675a5d767 来源:牛客网 1、HashMap是非线程安全的,HashTable是线程安全的。 2、HashMap的键和值都允许有null值存在,而HashTable则不行。 3、因为线程安全的问题,HashMap效率比HashTable的要高。 4、Hashtable是同步的,而HashMap不是。因此,HashMap更适合于单线程环境,而Hashtable适合于多线程环境。
8,Comparable和Comparator接口是
Collections.sort(listA); 链接:https://www.nowcoder.com/questionTerminal/99f7d1f4f8374e419a6d6924d35d9530 来源:牛客网 steaf Comparable & Comparator 都是用来实现集合中元素的比较、排序的,只是 Comparable 是在集合内部定义的方法实现的排序,Comparator 是在集合外部实现的排序,所以,如想实现排序,就需要在集合外定义 Comparator 接口的方法或在集合内实现 Comparable 接口的方法。 Comparator位于包java.util下,而Comparable位于包 java.lang下 Comparable 是一个对象本身就已经支持自比较所需要实现的接口(如 String、Integer 自己就可以完成比较大小操作,已经实现了Comparable接口) 自定义的类要在加入list容器中后能够排序,可以实现Comparable接口,在用Collections类的sort方法排序时,如果不指定Comparator,那么就以自然顺序排序, 这里的自然顺序就是实现Comparable接口设定的排序方式。 而 Comparator 是一个专用的比较器,当这个对象不支持自比较或者自比较函数不能满足你的要求时,你可以写一个比较器来完成两个对象之间大小的比较。 可以说一个是自已完成比较,一个是外部程序实现比较的差别而已。 用 Comparator 是策略模式(strategy design pattern),就是不改变对象自身,而用一个策略对象(strategy object)来改变它的行为。 比如:你想对整数采用绝对值大小来排序,Integer 是不符合要求的,你不需要去修改 Integer 类(实际上你也不能这么做)去改变它的排序行为,只要使用一个实现了 Comparator 接口的对象来实现控制它的排序就行了。
9,ArrayList和LinkedList
ArrayList 是线性表(数组) get() 直接读取第几个下标,复杂度 O(1) add(E) 添加元素,直接在后面添加,复杂度O(1) add(index, E) 添加元素,在第几个元素后面插入,后面的元素需要向后移动,复杂度O(n) remove()删除元素,后面的元素需要逐个移动,复杂度O(n) LinkedList 是链表的操作 get() 获取第几个元素,依次遍历,复杂度O(n) add(E) 添加到末尾,复杂度O(1) add(index, E) 添加第几个元素后,需要先查找到第几个元素,直接指针指向操作,复杂度O(n) remove()删除元素,直接指针指向操作,复杂度O(1)
10,jvm堆的结构
链接:https://www.nowcoder.com/questionTerminal/5c3dc3914da548e5b0617f4da9da7488 来源:牛客网 虚拟机中的共划分为三个代: 年轻代(Young Generation)、年老代(Old Generation)和持久代(Permanent Generation)。其中持久代主要存放的是Java类的类信息,与垃圾收集要收集的Java对象关系 不大。年轻代和年老代的划分是对垃 圾收集影响比较大的。 年轻代: 所有新生成的对象首先都是放在年轻代的。年轻代的目标就是尽可能快速的收集掉那些生 命周期短的对象。年轻代分三个区。一个Eden区,两个 Survivor区(一般而言)。大部分对象在 Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这 个 Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor去也满了 的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制“年老区 (Tenured)”。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时 存在从Eden复制过来对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第 一个Survivor去过来的对象。而且,Survivor区总有一个是空的。同时,根据程序需要, Survivor区是可以配置为多个的(多于两个),这样可以增加对象在年轻代中的存在时间,减 少被放到年老代的可能。 年老代: 在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认 为年老代中存放的都是一些生命周期较长的对象。 持久代: 用于存放静态文件,如今Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应 用可能动态生成或者调用一些class,例如Hibernate 等,在这种时候需要设置一个比较大的持 久代空间来存放这些运行过程中新增的类。持久代大小通过-XX:MaxPermSize=<N>进行设置。
11,sendRedirect()和forward()
链接:https://www.nowcoder.com/questionTerminal/c6fba3939ff54a39985611b489a5fceb 来源:牛客网 forward是服务器内部的跳转,浏览器的地址栏不会发生变化,同时可以把request和response传递给后一个请求。sendRedirect()是浏览器方面的跳转,要发送两次请求,地址栏也会发生变化,同时request和response也会发生变化,重新生成新的对象。