注:本实验的源代码和测试数据已经上传到git上,链接如下:
一、实验目的
- 通过简单例子学习k-近邻算法的原理。
- 使用k-近邻算法改进约会网站。
- 使用k-近邻算法编写手写识别系统。
二、实验内容与设计思想
实验内容:
-
理解k-近邻算法的原理,学习简单例子。
-
通过阅读资料中的“2.2节使用k-maean算法改进约会网站效果”,参照代码自己敲一遍,并通过资料中的讲解,对代码进行一步步的分析和注释。
-
最后通过自己对k-近邻算法求解约会网站效果的理解,动手自己写一遍代码。
设计思想:
-
k-近邻算法对约会网站的解析的设计思想:
- 收集资料:上网查阅资料获得的文本文件(“datingTestSet2.txt”数据文件)
- 准备数据:使用Python解析文本文件
- 分析数据:使用Matplotlib画二维扩散图
- 训练算法:该步骤不适用于k-近邻算法
- 测试算法:使用上面文本文件中的部分数据作为测试样本。
- 使用算法:产生简单的命令行运行程序,让海伦可以通过输入一些特征数据就可以判断出对方是否是自己喜欢的类型。
-
k-近邻算法在手写识别系统的设计思想:
- 收集数据:提供文本文件,网上查阅资料获得(trainingDigits文件夹和testDigits文件夹下的数据文件)
- 准备数据:编写img2vector()函数,将图像格式转化为分类器使用的list格式。
- 分析数据:在Python命令提示符中检查数据,确保符合要求。
- 训练算法:此步骤不适用于k-近邻算法
- 测试算法:编写函数使用提供的部分数据集作为测试样本,测试样本与非测试样本的区别在于测试样本已经完成分类的数据,如果分类器得到的预测分类与实际类别不同,则标记为一次错误。
- 使用算法:通过自己创建一个32×32数组形式的数字图像,运用上诉算法进行测试数字类别。
三、实验使用环境
- 操作系统:Microsoft Windows 10
- 编程环境:Python 3.6、pycharm
四、实验步骤和调试过程
4.1 通过简单例子理解k-近邻算法
-
导入的库:
from numpy import * import operator -
k-近邻算法的核心--分类器函数classify()说明:
def classify(inX, dataSet, labels, k): """ 分类器,通过距离计算公式,来获得最终的分类结果。 :param inX: 传入需要测试的列表 :param dataSet: 特征集合 :param labels: 类别集合 :param k: 匹配次数 :return: 返回训练结果,即所属类型 """ # 欧式距离公式:d = [(xA0 - xB0)^2 + (xA1 - xB1)^2]^0.5 dataSetSize = dataSet.shape[0] diffMat = tile(inX, (dataSetSize, 1)) - dataSet sqDiffMat = diffMat ** 2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances ** 0.5 # 获得排序后各个值在原数组中的索引 sortedDistIndicies = distances.argsort() classCount = {} # 选择距离最小的k个点进行统计 for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 逆序排序,获得票数最多的特征值 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0]小结:
-
欧式距离公式:
[d= √[(xA_0-xB_0)^2+(xA_1-xB_1)^2 ] ] -
该公式是k-近邻算法的核心所在,通过计算目标点到给定数据集中的各个点的距离,并取出离目标点最近的k个点,统计这k个点所属的类型的数量,得到数量最多的类型作为目标点的最终类型。即为
k-近邻算法。 -
简单点说,k-近邻算法采用测量不同特征值之间的距离方法进行分类。
-
-
createDataSet()函数说明:
def createDataSet(): """ 一个简单的测试例子。 :return: """ # group是一个简单的特征数据集 group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]]) # labels是上面的各个特征最终所对应的类型 labels = ['A', 'A', 'B', 'B'] # 通过classify函数来判断[0, 0]这个特征所属类型 print('分类器求得的最终类型是:%s' % (classify([0, 0], group, labels, 3))) if __name__ == '__main__': createDataSet()输出:
分类器求得的最终类型是:B
小结:
- 通过createDataSet()这个函数,可以看到,要使用k-近邻算法,我们首先需要要有一些现成的样本,样本可以帮助我们找到数据的一般性规律,函数中的
group即为一份简单样本数据。其次这些样本我们要知道这些样本数据所属的类型,函数中的labels充当的就是这个角色。最终我们可以通过classify()这个函数来判断[0, 0]这个特征所属的类型。
- 通过createDataSet()这个函数,可以看到,要使用k-近邻算法,我们首先需要要有一些现成的样本,样本可以帮助我们找到数据的一般性规律,函数中的
4.2 分析k-近邻算法在改进约会网站中的应用
4.2.1 题目说明
我的朋友海伦一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的人选,但她并不喜欢每一个人。经过一番总结,她发现曾交往过三种类型的人:
-
不喜欢的人
-
魅力一般的人
-
极具魅力的人
尽管发现了上述规律,但海伦依然无法将约会网站推荐的匹配对象归入恰当的分类。她觉得可以在周一到周五约会那些魅力一般的人,而周末则更喜欢与那些极具魅力的人为伴。海伦希望我们的分类软件可以更好地帮助她将匹配对象划分到确切的分类中。此外海伦还收集了一些约会网站未曾记录的数据信息,她认为这些数据更有助于匹配对象的归类。
收集的数据如下:
数据说明:
前三列分别表示:
-
每年获得的飞行常客历程数
-
玩视频游戏所耗时间百分比
-
每周消费的冰淇淋公升数
最后一列表示:
- 1表示不喜欢的人
- 2表示魅力一般的人
- 3表示极具魅力的人
4.2.2 源代码解析(运用kNN算法求解的一般步骤解析)
导入的模块
from numpy import *
import matplotlib.pyplot as plt
import operator
1. 准备数据:从文本文件中解析数据→file2matrix(filename)函数
def file2matrix(filename):
"""
读取文件中的数据,进行格式化处理,并存储到相应的数组中
:param filename: 要读取的文件路径和文件名
:return: returnMat, classLabelVector
returnMat中存储每行3个数据的二维数组,三个数据分别表示:
1.每年获得的飞行常客历程数
2.玩视频游戏所耗时间百分比
3.每周消费的冰淇淋公升数
classLabelVector中存储的是文件中每行的最后一个字符串,表示所属类型。
"""
# 分割字符串,每一个tab键分割出一个字符串
fr = open(filename)
# 将文件中的数据以行的形式,存入到arrayOLines
arrayOLines = fr.readlines()
# 计算arrayOLines的存储的记录数量
numberOfLines = len(arrayOLines)
"""
给returnMat这个数组赋值,zeros函数是默认给每个位置赋值为0
其中zeros函数中的括号中的内容表示生成一个:
行数为numberOfLines,列数为3的的二维数组。
"""
returnMat = zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
# 去除一行字符串的首尾空格或换行符
line = line.strip()
# 分割字符串,每一个tab键分割出一个字符串
listFromLine = line.split(' ')
"""
数组returnMat[index, :]中:
index是数组的索引值
冒号":"是切片符
即将后面的listFromLine[0: 3]数组中取出三个值,加入到returnMat数组的第index行。
"""
returnMat[index, :] = listFromLine[0: 3]
# 将文件中的每一行的最后一个字符串依次加入到classLabelVector中。
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat, classLabelVector
小结:
- 通过将文本中的数据提取出来,并格式化成想要的格式的矩阵,便于后面操作使用。通过该操作,便于后面直接通过文本文件中解析出来的数据矩阵进行操作,节省了后面每次都要从文本汇总取数据的操作。
- 在对矩阵的操作中,我们用到了NumPy库中的相应的函数:
zeros()函数:生成一个所有元素都是0的矩阵(俗称多个zero加s)- 如果是一维矩阵,只要传入一个值代表列数即可。如果是二维矩阵,则需要传入一个列表(m, n),表示生成m行n列的矩阵。三维矩阵以此类推。
- 与之类似的NumPy函数有
ones(),表示生成全为1的矩阵。
2. 分析数据:使用Matplotlib创建散点图→show_file2matrix()函数
def show_file2matrix():
"""
图形化展示数据,清晰展示三个不同样本分类区域,具有不同爱好的人其类别区域也不同
:return:
"""
Mat, Labels = file2matrix('datingTestSet2.txt')
# figure()操作时创建或者调用画板,使用时遵循就近原则,所有画图操作是在最近一次调用的画图板上实现。
fig = plt.figure('特征关系图')
# add_subplot()函数表示在图像在网格中显示的位置。111表示“1×1网格数,第1个网格,(111)可以替代为(1, 1, 1)
ax = fig.add_subplot(111)
"""
scatter()函数为绘图功能,其中:
第一个参数和第二个参数分别表示x轴和y轴的坐标,一一对应。
第三个参数表示图中显示的点的大小,这里×15是为了让点更大,更清晰。
第四个参数表示图中点的颜色,使用Labels数组中的不同值使不同类型显示不同颜色。
这里的x轴和y轴的值选择的是数据集中的第1列和第2列主要原因:
三种类型在这两种特征下区分比较明显。
"""
ax.scatter(Mat[:, 0], Mat[:, 1], 15 * array(Labels), 15.0 * array(Labels))
plt.show() # 显示图像
输出图像:
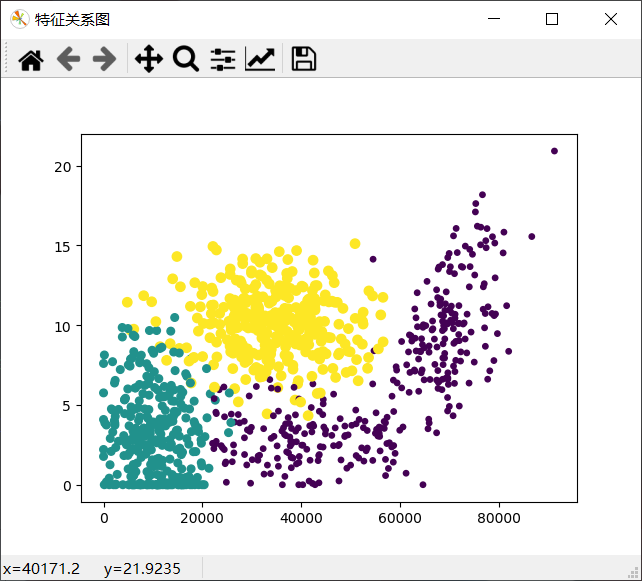
小结:
-
创建散点图的目的是什么?
为了了解给定数据的真实含义。当然我们可以通过直接浏览文本文件来分析数据的含义,但显然,干巴巴的数据看起来是非常死板的,从1000条数据中提取有效信息时非常困难的,也是非常不友好的。所以采用图形化的方式直观展示数据。
-
上面图形化得到的效果非常的清晰地标识了三个不同的样本分类区域,具有不同爱好的人其类别区域也不同。
-
上面图形化效果的呈现使用的x轴和y轴分别是特征中的:每年获得的飞行常客里程数和玩视频游戏所耗时间百分比。展示的效果较其他使用其他两种类型的好。这里我们通过修改上面函数中的下面这一句的代码,来看看用其他特征值呈现的效果:
ax.scatter(Mat[:, 0], Mat[:, 1], 15*array(Labels), 15.0 * array(Labels))通过修改前两个参数来实现。
1.修改方案一:
x轴表示:玩视频游戏所耗时间百分比。
ax.scatter(Mat[:, 1], Mat[:, 2], 15*array(Labels), 15.0 * array(Labels))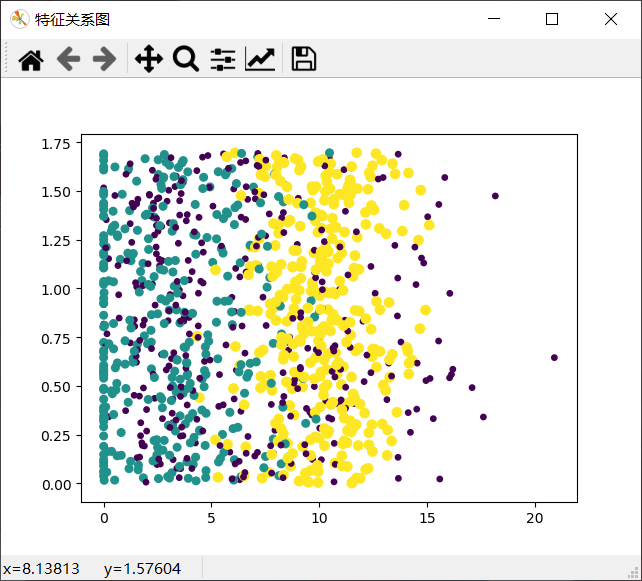
2.修改方案二:
x轴表示:每年获得的飞行常客里程数。
y轴表示:每周消费的冰淇淋公升数。
ax.scatter(Mat[:, 0], Mat[:, 2], 15*array(Labels), 15.0 * array(Labels))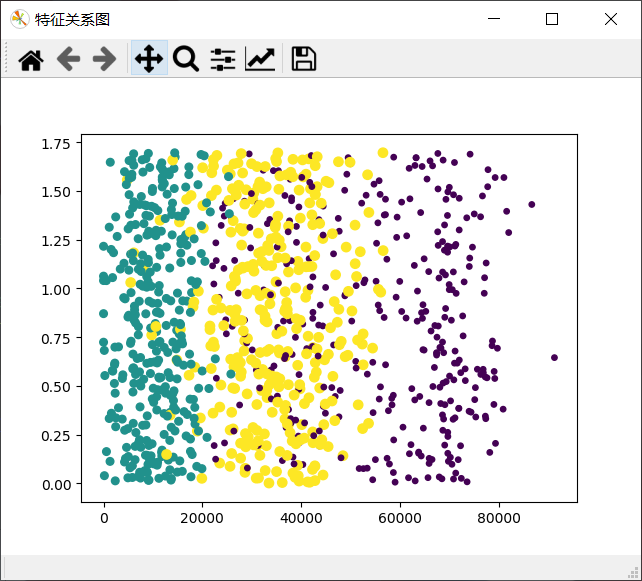
通过三个效果图的对比可以看出,运用0,1列展示的效果最佳,可以清晰地表示三个不同样本分类区域。
3. 准备数据:归一化数值→autoNorm(dataSet)函数
def autoNorm(dataSet):
"""
数值归一化,可以自动将数字特征值转化为0到1区间的值,表示所占比例
归一化处理的目的是:让数据中所有特征的权重一样。
数值归一化公式:(特征值-min)/(max-min)
:param dataSet: 传入上面已经格式化好的数据数组
:return:normDataSet, ranges, minVals
normDataSet:数值归一化后的数组
ranges:1×3数组,maxVals - minVals
minVals:数组中每列选取的最小值
"""
"""
dataSet.min(0)中的参数0使得函数可以从每列中选取最小值,而不是选取当前行的最小汉字。
同理:dataSet.max(0)是从数组的每列中选取最大值
这里获得的minVals和maxVals都是1×3的数组
"""
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
# 计算(max-min)的部分
ranges = maxVals - minVals
# 生成一个和dataSet同行数同列数的数组,数组中的数据全部填充为0
normDataSet = zeros(shape(dataSet))
"""
shape方法本身返回的是数组的结构,例:二维数组:返回的是(m, n),表示m行n列
此时shape[0]中就是m行的意思了
"""
m = dataSet.shape[0]
"""
tile函数是对数据进行格式化处理
tile(minVals, (m, 1))中的minVals表示要被格式化的数组,
(m, 1)表示生成一个m行,每行一个minVals数组的数组
"""
normDataSet = dataSet - tile(minVals, (m, 1)) # 就算(特征值-min)部分
# 数值归一化公式:(特征值-min)/(max-min)
normDataSet = normDataSet / tile(ranges, (m, 1))
return normDataSet, ranges, minVals
小结:
-
归一化数值的公式:
[n = (x-min)/(max-min)(0<n<1.0) ] -
为什么要数值归一化?
观察文本文件中的数据,我们可以发现,飞行常客里程数这一特征值相对于其他特征值在数值上大的多,当我们运用欧式距离公式计算的时候,该特征值的对于结果的影响远大于其他两个特征值(玩视频游戏所耗时间百分比、每周消费冰激凌公升数)的影响。
而对于该问题来说,三种特征值应该同等重要,通过数值归一化可以让任意范围的的特征值转化为0到1区间的值,即可以认为是某特征值占总特征值的比例,最后所有数据的范围都在0到1之间,即可实现特征值同等重要性。
-
NumPy相关函数解析:
-
min()函数:顾名思义就是得到最小值。但用在数组中则计算的方式就有点不一样了。min(0)表示从一列中的所有行中取出最小值,形成一个1×n数组。
min(1)表示从一行中的所有列中取出最小值,形成一个n×1数组。
-
max()函数:顾名思义取最大值,max(0)和max(1)效果同上。 -
tile(array, (m,n))函数:表示生成一个m行,每列n个array数组的矩阵。 -
shape()函数:获得数组的行列数,例:二维数组,返回一个(m, n)的列表,表示m行n列,此时如果使用shape[0]返回的就是m行。
-
4. 测试算法:作为完整程序验证分类器→datingClassTest()函数
分类器函数classify():(同上面简单例子中的分类器函数)
def classify(inX, dataSet, labels, k):
"""
分类器,训练模块,计算某些特征所属类型
:param inX: 传入需要测试的列表
:param dataSet: 特征集合
:param labels: 类别集合
:param k: 匹配次数
:return: 返回训练结果,即所属类型
"""
# 因为dataSet是一个二维数组,(m, n)表示m行n列,shape[0]获得m行的数量
dataSetSize = dataSet.shape[0]
"""
tile函数用于生成一个dataSetSize行数,inX列数的二维数组
将新生成的二维数组的每个值依次减去dataSet这个数组中的各个值
"""
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
# diffMat数组中的各个值平方
sqDiffMat = diffMat ** 2
# .sum(axis=1)中axis为1时表示按行的方向相加;axis为0时表示按列的方向相加
sqDistances = sqDiffMat.sum(axis=1)
# 再将上面得到的各个和值分别开根号,求得两点之间的距离
distances = sqDistances ** 0.5
"""
argsort()函数功能说明:返回的是数组值从小到大的索引值。
例:[3, 2, 1]这个数组,使用argsort()函数,经历的步骤:
1.排序:[1, 2, 3]
2.得到排序后各个值所对应的原数组中的索引:1对应的索引值为2,2对应的索引值为1,3对应的索引值为0,
3.最后返回的数组为[2, 1, 0]
"""
# argsort函数返回的是distances这个数组中的值从小到大的索引值
sortedDistIndicies = distances.argsort()
classCount = {}
# 该for语句用来取出离目标数据最近的k个点
for i in range(k):
# 通过获得的最小k个值在原来数组中的索引值,可以从labels数组中得到该索引下所对应的喜欢类型和程度
voteIlabel = labels[sortedDistIndicies[i]]
# 字典处理方式,get方法中voteIlabel是key值,0是当字典中不存在voteIlabel时,给它赋默认值0
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# 对classCount这个字典的value值进行逆序排序,使得取第一个数为最大值
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 返回字典中的最大值,即算法计算得到的最接近的类型
return sortedClassCount[0][0]
测试分类器函数datingClassTest():
def datingClassTest():
"""
选取10%的数据来测试分类器的性能,即测试分类器分析数据的错误率。
:return:
"""
hoRatio = 0.10
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
# 因为normMat是一个二维数组,(m, n)表示m行n列,shape[0]获得m行的数量
m = normMat.shape[0]
# 取总数据的10%作为测试数据
numTestVecs = int(m * hoRatio)
errorCount = 0.0
"""
遍历所有测试数据,让测试数据原文件中正确的结果和分类器得到的结果进行对比,
对不正确的情况的数量进行统计,用于最后计算错误率。
"""
for i in range(numTestVecs):
"""
切片理解:
normMat[i, :],其中方括号中的逗号前后分别表示对行和列的切片,:前后没有值,表示取所有列的值,整个表示取第i行所有列的值
normMat[numTestVecs: m, :],同上,整个表示取出numTestVecs行到m行的所有列的值
datingLabels[numTestVecs: m],表示取出numTestVecs列到m列的值
"""
classifierResult = classify(normMat[i, :], normMat[numTestVecs: m, :],
datingLabels[numTestVecs: m], 3)
print("%d: 分类器返回的结果是: %d, 真正的答案是:%d" % (i,
classifierResult, datingLabels[i]))
# 当分类器得到的类型和原数据中的类型不同时,错误数加1
if classifierResult != datingLabels[i]:
errorCount += 1.0
print("分类器处理约会数据集的错误率为: %f" % (errorCount / float(numTestVecs)))
输出:
0: 分类器返回的结果是: 3, 真正的答案是:3
1: 分类器返回的结果是: 2, 真正的答案是:2
2: 分类器返回的结果是: 1, 真正的答案是:1
... ...
97: 分类器返回的结果是: 2, 真正的答案是:2
98: 分类器返回的结果是: 1, 真正的答案是:1
99: 分类器返回的结果是: 3, 真正的答案是:1
分类器处理约会数据集的错误率为: 0.050000
小结:
- 通过上面的测试可以看到,分类器处理约会数据集的错误率是5.0%,是一个不错的结果。可以通过datingClassTest的参数k,错误率会有一定的起伏变化。依赖于分类算法、数据集合程序设置,分类器的输出结果可能有很大的不同。
- 因为错误率较低,所以完全可以使用该程序来判断海伦输入的对象信息,给出判断的最终类型。
- 小知识:机器学习算法一个很重要的工作就是评估算法的正确率,通过我们已有的数据的90%作为训练样本来训练分类器,而使用其余的10%数据取测试分类器,检测分类器的正确率。通过得到的正确率判断该分类器是否可以真正应用到现实中。
5. 使用算法:构建完整的可用体系→classifyPerson()函数
def classifyPerson():
"""
通过数据处理和分类器的筛选,得到相应特征下的人所属的类别。
:return:
"""
resultList = ['不喜欢的人', '魅力一般的人', '极具魅力的人']
ffMiles = float(input("每年获得的飞行常客历程数:"))
percentTats = float(input("玩视频游戏所耗时间百分比:"))
iceCream = float(input("每年消费冰淇淋公升数:"))
datingDataMat, datingLabels = file2matrix("datingTestSet2.txt")
normMat, ranges, minVals = autoNorm(datingDataMat)
# 将上面用户输入的数据,整合到一个数组中
inArr = array([ffMiles, percentTats, iceCream])
# (inArr - minVals) / ranges 对inArr中的数值进行归一化处理
classifierResult = classify((inArr - minVals) / ranges, normMat, datingLabels, 3)
print("你对这个人的印象是:", resultList[classifierResult - 1])
输出:
每年获得的飞行常客历程数:40000
玩视频游戏所耗时间百分比:8
每年消费冰淇淋公升数:0.9
你对这个人的印象是: 极具魅力的人
小结:
- 注意这里我们输入的特征数据要进行归一化处理,在传入分类器中判断类型。
4.3 通过对kNN算法的理解,自己编写改进约会网站主要运行代码
from numpy import *
import operator
__author__ = 'zjw'
def fileToMatrix(fileName):
"""
将文件转为相应的矩阵
:param fileName: 文件路径和文件名
:return:
eigenvalueMatrix:特征值矩阵
typeMatrix:类型矩阵
"""
file = open(fileName)
lines = file.readlines()
numOfLines = len(lines)
eigenvalueMatrix = zeros((numOfLines, 3))
typeMatrix = zeros(numOfLines)
index = 0
for line in lines:
line = line.strip()
line = line.split(" ")
eigenvalueMatrix[index, 0:3] = line[0:3]
typeMatrix[index] = line[-1]
index += 1
return eigenvalueMatrix, typeMatrix
def eigenvalueNormalization(eigenvalueMatrix):
"""
特征值归一化,使所有特征值所占权重相等。
单一特征值归一化公式:
(特征值-min)/(max-min)
:param eigenvalueMatrix:特征矩阵
:return:
"""
# 取出每列所对应的所有行中的最大值/最小值,形成一个以为矩阵赋值给maxValues/minValues
maxValues = eigenvalueMatrix.max(0)
minValues = eigenvalueMatrix.min(0)
ranges = maxValues - minValues
numOfRows = len(eigenvalueMatrix)
# 特征值-min矩阵
eigenvalueSubMinMatrix = zeros(shape(eigenvalueMatrix))
# max-min矩阵
rangesMatrix = zeros(shape(eigenvalueMatrix))
for i in range(numOfRows):
eigenvalueSubMinMatrix[i, :] = eigenvalueMatrix[i, :] - minValues[:]
rangesMatrix[i, :] = ranges[:]
normEigenvalueMatrix = eigenvalueSubMinMatrix / rangesMatrix
return normEigenvalueMatrix, ranges, minValues
def classify(toBeJudged, normEigenvalueMatrix, typeMatrix, k):
"""
分类器,通过计算获得带判断特征的类型
:param toBeJudged:待判断的特征类型
:param normEigenvalueMatrix:归一化特征值矩阵
:param typeMatrix:类型矩阵
:param k:k个最近类型
:return:
"""
numOfRows = len(normEigenvalueMatrix)
judgeMatrix = zeros(shape(normEigenvalueMatrix))
for i in range(numOfRows):
judgeMatrix[i, :] = toBeJudged[:]
squareMatrix = (normEigenvalueMatrix - judgeMatrix) ** 2
sumMatrix = squareMatrix.sum(axis=1)
distancesMatrix = sumMatrix ** 0.5
sortedDistancesMatrix = distancesMatrix.argsort()
eachOfCount = {}
for i in range(k):
index = sortedDistancesMatrix[i]
eachOfCount[typeMatrix[index]] = eachOfCount.get(typeMatrix[index], 0) + 1
sortedEachOfCount = sorted(eachOfCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedEachOfCount[0][0]
if __name__ == '__main__':
eigenvalueMatrix, typeMatrix = fileToMatrix('datingTestSet2.txt')
normEigenvalueMatrix, ranges, minValues = eigenvalueNormalization(eigenvalueMatrix)
dis = float(input("每年获得的飞行常客历程数:"))
per = float(input("玩视频游戏所耗时间百分比:"))
ice = float(input("每年消费冰淇淋公升数:"))
toBeJudged = array([dis, per, ice])
normJudged = (toBeJudged - minValues) / ranges
type = classify(normJudged, normEigenvalueMatrix, typeMatrix, 3)
typeOfPeople = ['不喜欢的人', '魅力一般的人', '极具魅力的人']
print(typeOfPeople[int(type) - 1])
输出:
每年获得的飞行常客历程数:40000
玩视频游戏所耗时间百分比:8
每年消费冰淇淋公升数:0.9
极具魅力的人
小结:
- 可以看到这里得到的测试结果和上面的测试结果一致。在外面进行了几组测试也是一致的。
- 通过自己编写主要的算法步骤,来生成判断对象类型的分类器,可以实现基本的判断约会网站对象的算法。但是这里我省去了
分析数据和测试数据两个步骤,因为上面的主要程序中已经完成了这两方面的测试,所以这里就不再重复测试。 - 通过自己敲一遍代码,对该算法有了更加直观的理解,且增强了堆NumPy库中的一些函数使用的记忆,边回忆边思考的学习方式还是很有效果的。
4.4 分析k-近邻算法在手写识别系统中的应用
4.4.1 题目说明
构造使用k-近邻分类器的手写识别系统,该系统可以识别数字0到9,需要识别的数字图像已经转化成相同色彩和大小的图像:宽高都是32像素×32像素的黑白图像。为了方便测试和理解,这里将图像转化为txt文件,用01绘图方式构建数字图像进行测试。数字图像实例如下:

可以看到该图像展示的一个大大的0.
而我们的手写识别系统就是为了判断这样一张32×32数组表示的数是多少。
这里将训练数据和测试数据分别存储在trainingDigits和testDigits这两个文件夹中,具体文件夹和图像文件文件名命名形式如下截图所示:
其中,每个txt文件中的图像都是32×32数组形式。
4.4.2 源代码解析(运用kNN算法求解的一般步骤解析)
导入模块
from numpy import *
from os import listdir
import operator
1. 准备数据:将图像转化为测试向量→img2vector()函数
def img2vector(filename):
"""
将文件中的图像(这里是一个数字二维矩阵)转化为以为的数组
:param filename: 文件路径和文件名
:return:
"""
# 创建一个1行1024列的数组,每个值都为0
returnVector = zeros((1, 1024))
fr = open(filename)
for i in range(32): # 遍历行
lineStr = fr.readline() # 取出一整行的数据
for j in range(32): # 遍历列
# 将一行的数据相接在returnVector数组中
returnVector[0, 32 * i + j] = int(lineStr[j])
return returnVector
小结:
- 该函数通过将32×32的数组图像转化为一维测试向量,以便存储作为特征矩阵和特征集合。
- 通过读取图像文件的的每一行每一列,将每行连接起来的形式存储到单一的测试向量中并返回。
2. 测试算法:使用k-近邻算法识别手写数字→handwritingClassTest()函数
def handwritingClassTest():
"""
使用kNN算法中的分类器来测试识别手写数字系统。
其中特征集数组放在trainingDigits文件夹下面,待测试特征集数据放在testDigits文件夹下面。
:return:
"""
# 依次存放各个图像所表示的数字
hwLabels = []
# listdir()函数是os模块下的函数,功能是可以列出指定文件夹下的文件名。
trainingFileList = listdir('trainingDigits')
# 计算trainingDigits文件夹下文件数量
m = len(trainingFileList)
# 生成一个m行1024列的数组,数组中各个值为0,用来存放m个1024个特征值。
trainingMat = zeros((m, 1024))
# 遍历所有训练图像
for i in range(m):
# 依次获取图像的txt文件名
fileNameStr = trainingFileList[i]
# 通过split()函数将文件名分成名字和txt两部分
fileStr = fileNameStr.split('.')[0]
# 再将前缀分成数字和序号两部分
classNumStr = int(fileStr.split('_')[0])
# 将图像表示的数字依次存入到hwLabels数组中
hwLabels.append(classNumStr)
# 通过路径和文件名传入到img2vector函数中,将相应txt中的图像转化为数组,并存入到trainingMat矩阵中的第i行
trainingMat[i, :] = img2vector('trainingDigits/%s' % fileNameStr)
# 初始化错误次数为0
errorCount = 0.0
# listdir函数列出了testDigits文件夹下的文件名
testFileList = listdir('testDigits')
# 计算testDigits文件下的文件数量
mTest = len(testFileList)
# 遍历所有测试图像
for i in range(mTest):
# 同上,先取出文件名,切割文件名取出文件中图像的数字。
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
# 通过路径和文件名传入img2vector函数中,将相应txt中的图像转化为数组,并存入到vectorUnderTest这个待测试特征矩阵中
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
# 将待测试特征矩阵,特征集矩阵,特征集对应的数字和k依次传入到分类器中进行运算测试,得到测试结果的数字
classifierResult = classify(vectorUnderTest, trainingMat, hwLabels, 3)
print("%d:分类器返回的数字为:%d,真正的数字是:%d" % (i+1, classifierResult, classNumStr))
# 如果测试结果不等于真实的数字,则错误数量加1
if classifierResult != classNumStr:
errorCount += 1.0
print("
分类器筛选出来错误的情况有:%d次" % errorCount)
# 计算错误率
print("
分类器的错误率为:%f" % (errorCount / float(mTest)))
输出:
1:分类器返回的数字为:0,真正的数字是:0
2:分类器返回的数字为:0,真正的数字是:0
3:分类器返回的数字为:0,真正的数字是:0
4:分类器返回的数字为:0,真正的数字是:0
5:分类器返回的数字为:0,真正的数字是:0
6:分类器返回的数字为:0,真正的数字是:0... ...
943:分类器返回的数字为:9,真正的数字是:9
944:分类器返回的数字为:9,真正的数字是:9
945:分类器返回的数字为:9,真正的数字是:9
946:分类器返回的数字为:9,真正的数字是:9分类器筛选出来错误的情况有:10次
分类器的错误率为:0.010571
注:这里运用的classify()分类器函数和上面简单例子以及约会网站例子的函数一致。
小结:
- 通过测试数据可以看到分类器判断手写数字的类型的错误率为1.06%,改变k值或则训练样本本、或则样本数目等都会对错误率产生影响。而这里得到的1.06%的错误率是一个非常好的结果,说明该算法可以用于进行手写数字系统。
- 而实际上,但我执行这个测试函数时,有一个很直观的感受就是该算法的执行效率并不高。因为算法需要进行m次距离运算,每个距离运算包括了1024个维度浮点运算,总计要执行mTest次。此外还需给测试数据和训练数据准备大量的空间存储。所以在时间和空间复杂度上该算法并不是很完美。
- os模块中的listdir()函数:用于列出相应文件夹下的所有文件名。
五、实验小结
-
k-近邻算法:采用测量不同特征值之间的距离方法进行分类。
-
欧式距离公式:
用于计算数据集中的各个点到目标点的距离。以便于筛选出k个最近的数据集点。
- 数值归一化公式:
归一化数值可以使特征值同等重要。
-
测试数据时,选用10%样本数据作为测试数据,90%样本数据作为参照数据来测试分类器的正确率,通过正确率判断分类器效果是否可行。
-
绘制散点图有助于我们更加清晰地观察数据集之间的真实关系。
-
NumPy库中的一些函数:
zeros()、ones()、min()、max()、shape()、tile()等。相关用法可以翻看上面的讲解。
-
实验遇见问题:
Matplotlib包导入问题:
一开始编译器显示不存在这个包。
根据编译器提示:install package matplotlib ,直接在pycharm上给安装了。
六、参考资料
- 《机器学习实战》 Peter Harrington (作者) 李锐 , 李鹏 , 曲亚东 , 王斌 (译者) 第2章 k-近邻算法
- 【机器学习】k-近邻算法案例——约会网站的配对效果、手写数字识别系统
- 数据来源:https://github.com/apachecn/data
版权声明:欢迎转载=>请标注信息来源于 Vanish丶博客园