Sigcomm'18
AuTO: Scaling Deep Reinforcement Learning for Datacenter-Scale Automatic Traffic Optimization
问题
主要问题:流量算法的配置周期长,人工配置难且繁复。人工配置的时间成本大,人为错误导致的性能降低。
要计算MLFQ的阈值参数是很麻烦的事情,先前有人构建了一个数学模型来优化这个阈值,在几个星期或者几个月更新一次阈值,更新周期过长。
可以使用DRL(Deep Reinforcement Learning)的方法根据环境自动配置(决策)算法参数,减少人工配置的时间成本,减少人为错误导致的性能降低。
基于主流框架TensorFlow或是pytorch等框架的的DRL难以掌控TO(traffic optimization)的小流(速度过快)
使用DRL优化时遇见的问题:DRL配置TO时,由于小流通过速度大于配置下发的速度,所以来不及下发配置。
解决方法
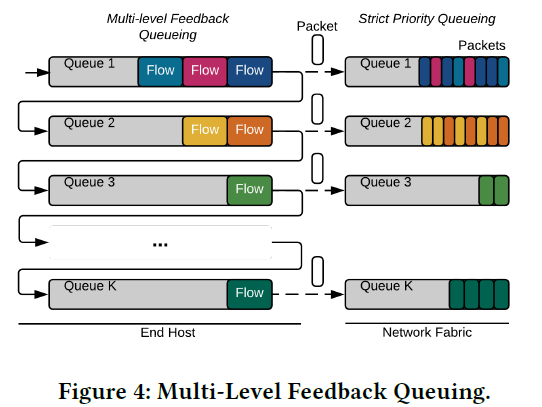
优化的算法:采用 Multi-Level Feedback Queueing(MLFQ)来管理流。第一级别的队列为小流,所有流初始化为小流。当流的大小超过阈值时,判定为大流,在队列中被降级到第二队列。可以有k个队列,按照流的不同级别分在不同的队列当中。
决策参数:基于比特数和阈值来对每个流做出决策,判定流属于第几级别的队列。
评价参数:当一次流处理完成时,计算一个比率,比率为本次的吞吐量与前一次的吞吐量之比。 吞吐量Sizef(流长)与FCT(Flow completion time)之比。
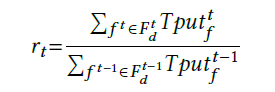
使用DRL优化:使用强化学习优化阈值。根据结果反馈调整阈值的设定。
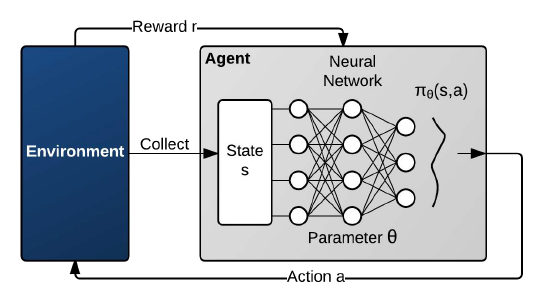
状态和奖励返回是随机的马尔科夫过程
模型选择
公式一

公式一的改进:公式二
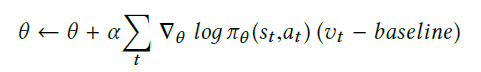
算法主要使用公式二
算法

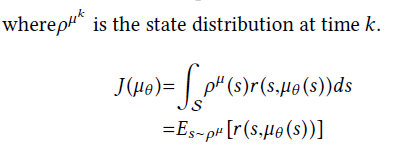
论文从强化学习的算法PG讲到DPG再讲到DDPG,最后使用了DDPG。
经过查询资料,DDPG使用了深度神经网络,并且针对的是决策值为连续的情况,而参数值的变化又是连续的,所以使用DDPG较为合适且有效。
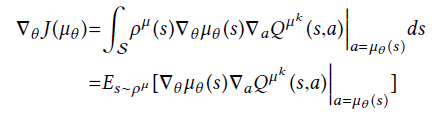
当一次流处理完成时,计算一个比率,比率为本次的吞吐量与前一次的吞吐量之比。 吞吐量Sizef(流长)与FCT(Flow completion time)之比。
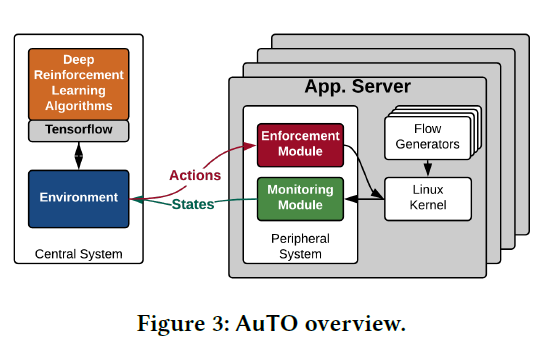
框架构建
模型组成:
- 边缘系统
- 中心系统
边缘系统
有一个MLFQ,首级队列为小流,当流超过阈值,判定为大流,在队列中被降级。
边缘系统分为增强模块和探测模块。
- 探测模块:获取流的状态信息(包括所有流的大小和处理完成的时间)
- 增强模块:获取中心系统的action,执行操作。
中心系统
其中的DRL有两个agent:
- sRLA(short Reinforcement Learning Agent): 优化小流阈值
- lRLA(long Reinforcement Learning Agent):优化大流,速率、路由、优先级